Вам также может понравиться
- 1.1 The Importance of Vision: 2002 CRC Press LLCДокумент22 страницы1.1 The Importance of Vision: 2002 CRC Press LLCVany BraunОценок пока нет
- 1.1 The Importance of Vision: 2002 CRC Press LLCДокумент22 страницы1.1 The Importance of Vision: 2002 CRC Press LLCsansureОценок пока нет
- Computer Stereo Vision: Exploring Depth Perception in Computer VisionОт EverandComputer Stereo Vision: Exploring Depth Perception in Computer VisionОценок пока нет
- A Simple Scheme For Contour Detection: Gopal Datt JoshiДокумент7 страницA Simple Scheme For Contour Detection: Gopal Datt Joshigupta_akash30Оценок пока нет
- Detection of Human Motion: Adopting Machine and Deep LearningДокумент8 страницDetection of Human Motion: Adopting Machine and Deep LearningPavithra iyerОценок пока нет
- 1.1 Motivation For Image Fusion ResearchДокумент27 страниц1.1 Motivation For Image Fusion ResearchVivek InfoTechОценок пока нет
- Image Correction - FCC - ClassificationДокумент8 страницImage Correction - FCC - ClassificationrohitОценок пока нет
- 9780198070788Документ52 страницы9780198070788palak parmarОценок пока нет
- Contrast Sensitivity For Human Eye SystemДокумент10 страницContrast Sensitivity For Human Eye SystemNandagopal SivakumarОценок пока нет
- Object Detection and Tracking in Video SequencesДокумент6 страницObject Detection and Tracking in Video SequencesIDESОценок пока нет
- Vikram Narayan Research Engineer GREYC, University of CaenДокумент19 страницVikram Narayan Research Engineer GREYC, University of Caensargam111111Оценок пока нет
- Lens Light: in Barrel Distortion, Straight Lines Bulge Outwards at The Center, As in AДокумент7 страницLens Light: in Barrel Distortion, Straight Lines Bulge Outwards at The Center, As in AFaseela HarshadОценок пока нет
- Articulated Body Pose Estimation: Unlocking Human Motion in Computer VisionОт EverandArticulated Body Pose Estimation: Unlocking Human Motion in Computer VisionОценок пока нет
- Question 1-Explain The Process of Formation of Image in Human EyeДокумент6 страницQuestion 1-Explain The Process of Formation of Image in Human EyeDebapriya SahooОценок пока нет
- Image Fusion Algorithm Based On Biorthogonal Wavelet: Vol. 1 Issue 2 July 2011Документ6 страницImage Fusion Algorithm Based On Biorthogonal Wavelet: Vol. 1 Issue 2 July 2011Vasudeva AcharyaОценок пока нет
- Object Detection and Tracking in Video SequencesДокумент6 страницObject Detection and Tracking in Video SequencesidesajithОценок пока нет
- Tone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionОт EverandTone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionОценок пока нет
- Design If Iris Based Medical Diagnosis SystemДокумент4 страницыDesign If Iris Based Medical Diagnosis SystemDr Vaishali MathapatiОценок пока нет
- Unit 1 CVДокумент13 страницUnit 1 CVBobbyОценок пока нет
- New Approaches to Image Processing based Failure Analysis of Nano-Scale ULSI DevicesОт EverandNew Approaches to Image Processing based Failure Analysis of Nano-Scale ULSI DevicesРейтинг: 5 из 5 звезд5/5 (1)
- I Ji Scs 01112012Документ11 страницI Ji Scs 01112012WARSE JournalsОценок пока нет
- 5 - AshwinKumar - FinalPaper - IISTE Research PaperДокумент6 страниц5 - AshwinKumar - FinalPaper - IISTE Research PaperiisteОценок пока нет
- Unit 1 Digital Image .Документ74 страницыUnit 1 Digital Image .Prabhu ShibiОценок пока нет
- Edge Detection Techniques For Image SegmentationДокумент9 страницEdge Detection Techniques For Image SegmentationAnonymous Gl4IRRjzNОценок пока нет
- Sixth Sense TechnologyДокумент18 страницSixth Sense TechnologySanthu vОценок пока нет
- Human EyeДокумент78 страницHuman Eyenandini bhalekarОценок пока нет
- Active Contour: Advancing Computer Vision with Active Contour TechniquesОт EverandActive Contour: Advancing Computer Vision with Active Contour TechniquesОценок пока нет
- Mc0086 AssignmentДокумент8 страницMc0086 Assignmentクマー ヴィーンОценок пока нет
- Detection of Skin Diasease Using CurvletsДокумент5 страницDetection of Skin Diasease Using CurvletsInternational Journal of Research in Engineering and TechnologyОценок пока нет
- Student AttendanceДокумент50 страницStudent AttendanceHarikrishnan ShunmugamОценок пока нет
- Paper 1Документ36 страницPaper 1Ahmed MateenОценок пока нет
- Evaluation of Image Fusion AlgorithmsДокумент5 страницEvaluation of Image Fusion AlgorithmsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- What Is Digital Image?: Remember Digitization Implies That A Digital Image Is An Approximation of A RealДокумент7 страницWhat Is Digital Image?: Remember Digitization Implies That A Digital Image Is An Approximation of A RealBhagyesh ShahОценок пока нет
- Currency Recognition On Mobile Phones Proposed System ModulesДокумент26 страницCurrency Recognition On Mobile Phones Proposed System Moduleshab_dsОценок пока нет
- Underwater Computer Vision: Exploring the Depths of Computer Vision Beneath the WavesОт EverandUnderwater Computer Vision: Exploring the Depths of Computer Vision Beneath the WavesОценок пока нет
- A New Framework For Color Image Segmentation Using Watershed AlgorithmДокумент6 страницA New Framework For Color Image Segmentation Using Watershed AlgorithmpavithramasiОценок пока нет
- Abhishek KushДокумент17 страницAbhishek KushAbhishek KushОценок пока нет
- Image Fusion Algorithm Based On Biorthogonal WaveletДокумент7 страницImage Fusion Algorithm Based On Biorthogonal WaveletEmon KhanОценок пока нет
- Ijcai07 monocularStereoDepthДокумент7 страницIjcai07 monocularStereoDepthsigmateОценок пока нет
- Introduction To Image File FormatsДокумент87 страницIntroduction To Image File FormatsRajeswari PurushothamОценок пока нет
- Survey On Different Image Fusion Techniques: Miss. Suvarna A. Wakure, Mr. S.R. TodmalДокумент7 страницSurvey On Different Image Fusion Techniques: Miss. Suvarna A. Wakure, Mr. S.R. TodmalInternational Organization of Scientific Research (IOSR)Оценок пока нет
- Computer Vision Fundamental Matrix: Please, suggest a subtitle for a book with title 'Computer Vision Fundamental Matrix' within the realm of 'Computer Vision'. The suggested subtitle should not have ':'.От EverandComputer Vision Fundamental Matrix: Please, suggest a subtitle for a book with title 'Computer Vision Fundamental Matrix' within the realm of 'Computer Vision'. The suggested subtitle should not have ':'.Оценок пока нет
- Base PaperДокумент7 страницBase PaperMaria SmithОценок пока нет
- Image Processing Is Any Form ofДокумент6 страницImage Processing Is Any Form ofAbichithu23Оценок пока нет
- Project 1 FДокумент63 страницыProject 1 FSivaОценок пока нет
- Recognition of ASL Using Hand GesturesДокумент5 страницRecognition of ASL Using Hand GesturesInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Image Processing and AnalysisДокумент16 страницImage Processing and AnalysispoojavvceОценок пока нет
- EC-0104 Digital Image Processing: Application For Abnormal Incident Detection Mr. Mohd - Azahruddin Ansari Mr.C. Sujith Kumar AbstractДокумент9 страницEC-0104 Digital Image Processing: Application For Abnormal Incident Detection Mr. Mohd - Azahruddin Ansari Mr.C. Sujith Kumar AbstractSpandana ReddyОценок пока нет
- Modified Watershed Segmentation With Denoising of Medical ImagesДокумент6 страницModified Watershed Segmentation With Denoising of Medical ImagesAshish KumarОценок пока нет
- Handbook On Image Processing and Computer Vision Volume 3 From Pattern To ObjectДокумент694 страницыHandbook On Image Processing and Computer Vision Volume 3 From Pattern To ObjectRaghavendranОценок пока нет
- Brain Tumor DetectionДокумент16 страницBrain Tumor DetectionBHARATH BELIDE0% (1)
- Sensors On 3D DigitizationДокумент2 страницыSensors On 3D DigitizationamithpnaikОценок пока нет
- Unit 5Документ13 страницUnit 5asuras1234Оценок пока нет
- Learning Deep Architectures For AI - Yoshua BengioДокумент130 страницLearning Deep Architectures For AI - Yoshua BengioJohn Jairo SilvaОценок пока нет
- A New Framework For Color Image Segmentation Using Watershed AlgorithmДокумент7 страницA New Framework For Color Image Segmentation Using Watershed AlgorithmbudiОценок пока нет
- International Journal of Engineering Research and DevelopmentДокумент5 страницInternational Journal of Engineering Research and DevelopmentIJERDОценок пока нет
- International Journals Call For Paper HTTP://WWW - Iiste.org/journalsДокумент14 страницInternational Journals Call For Paper HTTP://WWW - Iiste.org/journalsAlexander DeckerОценок пока нет
- Image Fusion: Institute For Plasma ResearchДокумент48 страницImage Fusion: Institute For Plasma Researchbhargava1990100% (1)
- Az 03303230327Документ5 страницAz 03303230327International Journal of computational Engineering research (IJCER)Оценок пока нет
- SGM 3-2020 PDFДокумент16 страницSGM 3-2020 PDFcuickОценок пока нет
- SGM 3-2020Документ16 страницSGM 3-2020cuickОценок пока нет
- Transparenta Septembrie 2021Документ212 страницTransparenta Septembrie 2021cuickОценок пока нет
- SilverCrest SAB 160 B2 ManualДокумент1 страницаSilverCrest SAB 160 B2 ManualcuickОценок пока нет
- Scanned With CamscannerДокумент6 страницScanned With CamscannercuickОценок пока нет
- c4 Test 2Документ4 страницыc4 Test 2cuickОценок пока нет
- Grande PuntoДокумент4 страницыGrande Puntocuick100% (1)
- Image Processing Series: Published TitlesДокумент9 страницImage Processing Series: Published TitlescuickОценок пока нет
- 7.1 Modeling Timing: Timed CircuitsДокумент18 страниц7.1 Modeling Timing: Timed CircuitscuickОценок пока нет
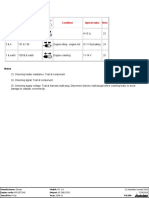
- Heated Oxygen Sensor (HO2S) 1: Terminals Wire Colour/number Condition Typical Value NoteДокумент1 страницаHeated Oxygen Sensor (HO2S) 1: Terminals Wire Colour/number Condition Typical Value NotecuickОценок пока нет
- Cikuit: Asynchronous DesignДокумент14 страницCikuit: Asynchronous DesigncuickОценок пока нет
- Fundamentals of Neural Network Image RestorationДокумент15 страницFundamentals of Neural Network Image RestorationcuickОценок пока нет
- 5.1.1 Weight-Parameterized Model-Based Neuron: N P M P NДокумент33 страницы5.1.1 Weight-Parameterized Model-Based Neuron: N P M P NcuickОценок пока нет
- 6A05 THRU 6A10: Axial Silastic Guard Junction Standard RectifierДокумент2 страницы6A05 THRU 6A10: Axial Silastic Guard Junction Standard RectifiercuickОценок пока нет
- FR201 FR207: FeaturesДокумент3 страницыFR201 FR207: FeaturescuickОценок пока нет
- Arduino GuideДокумент39 страницArduino GuidecuickОценок пока нет
- NR - CRT ID Nume Prenume Clasa Profesor Indrumator Binar Oficiu Numere Oficiu Total Premiu Rezultat Scoala de Provenie NtaДокумент9 страницNR - CRT ID Nume Prenume Clasa Profesor Indrumator Binar Oficiu Numere Oficiu Total Premiu Rezultat Scoala de Provenie NtacuickОценок пока нет
- King BrightДокумент4 страницыKing BrightcuickОценок пока нет
- Rezultate Clasa A Vi-A: NR - Crt. ID Nume Prenume Clasa Scoala Prof Coordonatori Of. Joc Of. Total Premiu Rezultat Data PalДокумент5 страницRezultate Clasa A Vi-A: NR - Crt. ID Nume Prenume Clasa Scoala Prof Coordonatori Of. Joc Of. Total Premiu Rezultat Data PalcuickОценок пока нет
- Automotive Electronics DesignДокумент270 страницAutomotive Electronics Designcuick83% (6)
- Ambreiaj Golf 5Документ6 страницAmbreiaj Golf 5cuickОценок пока нет
- TO-92 Plastic-Encapsulate Thyristors: Jiangsu Changjiang Electronics Technology Co., LTDДокумент1 страницаTO-92 Plastic-Encapsulate Thyristors: Jiangsu Changjiang Electronics Technology Co., LTDcuickОценок пока нет
- Neural Network Controller For Power Electronics CircuitsДокумент7 страницNeural Network Controller For Power Electronics CircuitsIAES IJAIОценок пока нет
- SVM NotesДокумент40 страницSVM NotesMohitRajputОценок пока нет
- Modern Digital Communication: Statistical AveragesДокумент25 страницModern Digital Communication: Statistical AveragesSusheelkumar SreedharanОценок пока нет
- Python ProjectsДокумент24 страницыPython ProjectsHari haranОценок пока нет
- Linear Algebra, Signal Processing, and Wavelets - A Unifi Ed ApproachДокумент381 страницаLinear Algebra, Signal Processing, and Wavelets - A Unifi Ed Approachshoaibsaleem001100% (1)
- Tea Insect Pests Classification Based On Artificial NeuralДокумент8 страницTea Insect Pests Classification Based On Artificial NeuralMax ReaganОценок пока нет
- Numerical Analysis Lecture-10: Dr. Muhammad Shabbir Department of MathematicsДокумент11 страницNumerical Analysis Lecture-10: Dr. Muhammad Shabbir Department of MathematicsMuhammad AliОценок пока нет
- Coupled Eulerian Lagrange 1Документ17 страницCoupled Eulerian Lagrange 1nahoОценок пока нет
- Assignment 1Документ8 страницAssignment 1hoangngse180434Оценок пока нет
- 1improvement Algorithms of Perceptually Important P PDFДокумент5 страниц1improvement Algorithms of Perceptually Important P PDFredameОценок пока нет
- DOM105 Session 27Документ6 страницDOM105 Session 27DevanshiОценок пока нет
- Principles of Communication Systems LECTURE 2BДокумент33 страницыPrinciples of Communication Systems LECTURE 2BNITYA SATHISHОценок пока нет
- Transform Coding of Image Feature DescriptorsДокумент9 страницTransform Coding of Image Feature DescriptorsVarun PrakashОценок пока нет
- ML VisualsДокумент61 страницаML VisualsChrisОценок пока нет
- Course Syllabus of Digital Image Processing (EE6131)Документ1 страницаCourse Syllabus of Digital Image Processing (EE6131)Ritunjay GuptaОценок пока нет
- Lecture-8 Queuing TheoryДокумент67 страницLecture-8 Queuing TheoryAhmer ChaudhryОценок пока нет
- Lect 26 and 27 - Locality Sensitive HashingДокумент43 страницыLect 26 and 27 - Locality Sensitive HashingPriyam KumarОценок пока нет
- Time Series Analysis - Solution of Homework 6: Exercise 2.1Документ2 страницыTime Series Analysis - Solution of Homework 6: Exercise 2.1Mahyaddin GasimzadaОценок пока нет
- CH 04Документ26 страницCH 04pkabandaОценок пока нет
- CRYPT QuestionsДокумент7 страницCRYPT QuestionsNirajan KunwarОценок пока нет
- Bias in The TRNG of The Mifare Desfire EV1: Darren Hurley-SmithДокумент18 страницBias in The TRNG of The Mifare Desfire EV1: Darren Hurley-SmithMircea PetrescuОценок пока нет
- PD Control Based On Reinforcement Learning Compensation For A DC Servo DriveДокумент6 страницPD Control Based On Reinforcement Learning Compensation For A DC Servo DriveAlejandro MisesОценок пока нет
- Machine Learning With SQLДокумент12 страницMachine Learning With SQLprince krish100% (1)
- Quadratic FunctionsДокумент27 страницQuadratic FunctionsCHARLIENE FAYE ASPRERОценок пока нет
- Project PPT Review (Batch 1)Документ28 страницProject PPT Review (Batch 1)Prashanth KumarОценок пока нет
- Essay About Quantum ComputingДокумент1 страницаEssay About Quantum Computing부계부계Оценок пока нет
- Graph Representations: Adjacency Matrix Adjacency Lists Adjacency MultilistsДокумент20 страницGraph Representations: Adjacency Matrix Adjacency Lists Adjacency MultilistsRM IDEAL SOLUTIONSОценок пока нет
- Sample Exam2Документ81 страницаSample Exam2MarichelleAvilaОценок пока нет
- Estimating Group Fixed Effects in Panel Data With A Binary Dependent Variable How The LPM Outperforms Logistic Regression in Rare Events DataДокумент12 страницEstimating Group Fixed Effects in Panel Data With A Binary Dependent Variable How The LPM Outperforms Logistic Regression in Rare Events DataMHD RICKY KARUNIA LUBISОценок пока нет
- Spring 2012 Mth101 1 SolДокумент3 страницыSpring 2012 Mth101 1 SolShahbaz AbbasiОценок пока нет