Вам также может понравиться
- GCSE Maths Revision: Cheeky Revision ShortcutsОт EverandGCSE Maths Revision: Cheeky Revision ShortcutsРейтинг: 3.5 из 5 звезд3.5/5 (2)
- Notes No. 5 For 11 e Understanding Z ScoresДокумент5 страницNotes No. 5 For 11 e Understanding Z Scoresnikkigabanto.24Оценок пока нет
- H4 ExpectedValue NormalDistribution SolutionДокумент6 страницH4 ExpectedValue NormalDistribution SolutionHennrocksОценок пока нет
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankОт EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankОценок пока нет
- STAT100 Fall19 Test 2 ANSWERS Practice Problems PDFДокумент23 страницыSTAT100 Fall19 Test 2 ANSWERS Practice Problems PDFabutiОценок пока нет
- Tugas Kuliah StatistikaДокумент4 страницыTugas Kuliah StatistikaCEOAmsyaОценок пока нет
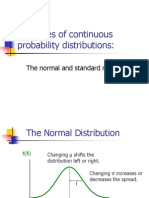
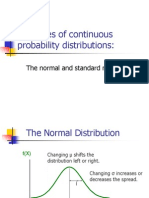
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalДокумент57 страницExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuОценок пока нет
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalДокумент57 страницExamples of Continuous Probability Distributions:: The Normal and Standard NormalkethavarapuramjiОценок пока нет
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalДокумент57 страницExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalОценок пока нет
- Z-Score Problems With The Normal Model: ObjectiveДокумент24 страницыZ-Score Problems With The Normal Model: ObjectiveCleverton da VeigaОценок пока нет
- Continuous Probability Z-ScoreДокумент51 страницаContinuous Probability Z-ScoreKhalil UllahОценок пока нет
- Lecture 3Документ42 страницыLecture 3S.WaqquasОценок пока нет
- Saint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesДокумент11 страницSaint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesJimkenneth RanesОценок пока нет
- Tugas Kuliah Statistika SESI 4Документ4 страницыTugas Kuliah Statistika SESI 4CEOAmsyaОценок пока нет
- The Normal Distribution: Armando A. Camana JR., MaedДокумент23 страницыThe Normal Distribution: Armando A. Camana JR., MaedKEISHA ARIANNA GORREZОценок пока нет
- Continuous Probability Distribution PDFДокумент47 страницContinuous Probability Distribution PDFDipika PandaОценок пока нет
- ECON1203 PASS Week 3Документ4 страницыECON1203 PASS Week 3mothermonkОценок пока нет
- STATISTICДокумент23 страницыSTATISTICnur ainun arsyadОценок пока нет
- Lecture 5: Statistical Inference by Dr. Javed IqbalДокумент4 страницыLecture 5: Statistical Inference by Dr. Javed IqbalHamna AghaОценок пока нет
- Week 5Документ55 страницWeek 5Yumi Ryu TatsuОценок пока нет
- The Z Score.1Документ17 страницThe Z Score.1Meliza AnalistaОценок пока нет
- Normal Distribution StanfordДокумент43 страницыNormal Distribution Stanfordapi-204699162100% (1)
- Normal DistributionДокумент29 страницNormal DistributionSandeepОценок пока нет
- Chapter 6Документ30 страницChapter 6Mohd Nazri OthmanОценок пока нет
- Problem MathДокумент3 страницыProblem MathSAKHAWAT HOSSAIN KHAN MDОценок пока нет
- Module 16 Areas Under A Normal DistributionДокумент6 страницModule 16 Areas Under A Normal DistributionAlayka Mae Bandales LorzanoОценок пока нет
- Random Variable & Probability DistributionДокумент48 страницRandom Variable & Probability DistributionRISHAB NANGIAОценок пока нет
- Week7 Quiz Help 2009Документ1 страницаWeek7 Quiz Help 2009dtreffnerОценок пока нет
- KK MathДокумент13 страницKK Mathm-3977431Оценок пока нет
- Normal DistributionДокумент29 страницNormal DistributionMohamed Abd El-MoniemОценок пока нет
- TLP 6 Normal DistributionДокумент7 страницTLP 6 Normal Distributionandy gamingОценок пока нет
- Pptcomputes Probabilities and Percentile Using The Standard NormalДокумент30 страницPptcomputes Probabilities and Percentile Using The Standard Normalnot deniseОценок пока нет
- NormalDistribution2012 PDFДокумент29 страницNormalDistribution2012 PDFElisa Dela Reyna BaladadОценок пока нет
- Probility DistributionДокумент41 страницаProbility Distributionnitindhiman30Оценок пока нет
- Worksheet 10 - Spring 2014 - Chapter 10 - KeyДокумент4 страницыWorksheet 10 - Spring 2014 - Chapter 10 - KeyMisbah MirzaОценок пока нет
- Lecture21 HypothesisTest1Документ53 страницыLecture21 HypothesisTest1Sonam AlviОценок пока нет
- NormalWS1 PDFДокумент4 страницыNormalWS1 PDFRizza Jane BautistaОценок пока нет
- Biostatistics For Academic3Документ28 страницBiostatistics For Academic3Semo gh28Оценок пока нет
- Chapter 1 - Solutions of ExercisesДокумент4 страницыChapter 1 - Solutions of ExercisesDanyValentinОценок пока нет
- Discussion1 SolutionДокумент5 страницDiscussion1 Solutionana_paciosОценок пока нет
- Activity 4: Guide Page 30-39Документ5 страницActivity 4: Guide Page 30-39MARLYNJHANE PEPITOОценок пока нет
- 4.-Normal-Distribution - LECTUREДокумент34 страницы4.-Normal-Distribution - LECTURERoyce GomezОценок пока нет
- Lc07 SL Estimation - PPT - 0Документ48 страницLc07 SL Estimation - PPT - 0Deni ChanОценок пока нет
- QTM Cycle 7 Session 4Документ79 страницQTM Cycle 7 Session 4OttilieОценок пока нет
- STA1007S Lab 10: Confidence Intervals: October 2020Документ5 страницSTA1007S Lab 10: Confidence Intervals: October 2020mlunguОценок пока нет
- Statistics Week 3.2Документ23 страницыStatistics Week 3.2Rena Rose MalunesОценок пока нет
- P (74 - X - 78) - Learn Math and Stats With Dr. GДокумент3 страницыP (74 - X - 78) - Learn Math and Stats With Dr. GnotmeОценок пока нет
- Normal DistributionДокумент29 страницNormal Distributionatul_rockstarОценок пока нет
- Normal Z Score and Sampling DistributionДокумент36 страницNormal Z Score and Sampling DistributionHanz ManzanillaОценок пока нет
- STAT 241 - Unit 5 NotesДокумент9 страницSTAT 241 - Unit 5 NotesCassie LemonsОценок пока нет
- Normal Probability Curve: Dr. K Uldeep KaurДокумент37 страницNormal Probability Curve: Dr. K Uldeep KaurK M TripathiОценок пока нет
- WIN SEM (2020-21) CSE4029 ETH AP2020215000156 Reference Material I 27-Jan-2021 DistibutionДокумент7 страницWIN SEM (2020-21) CSE4029 ETH AP2020215000156 Reference Material I 27-Jan-2021 DistibutionmaneeshmogallpuОценок пока нет
- Normal Distribution of Statistics and Probability and Basic Calculus - Continuity of FunctionsДокумент4 страницыNormal Distribution of Statistics and Probability and Basic Calculus - Continuity of FunctionsAlt GakeОценок пока нет
- Normal Probability Curve: Dr. Kuldeep KaurДокумент36 страницNormal Probability Curve: Dr. Kuldeep KaurKanchan ManhasОценок пока нет
- 2ndSemChapter2 AutosavedДокумент32 страницы2ndSemChapter2 AutosavedElmer Salamanca Hernando Jr.Оценок пока нет
- Statistic Sample Question IiswbmДокумент15 страницStatistic Sample Question IiswbmMudasarSОценок пока нет
- cHAPTER 6 STATISTICSДокумент22 страницыcHAPTER 6 STATISTICSjana ShmaysemОценок пока нет
- Midterm Review: Chapter 1 - Descriptive StatsДокумент6 страницMidterm Review: Chapter 1 - Descriptive StatsDenish ShresthaОценок пока нет
- Handnote On B-Stat.-I-chapter-3Документ57 страницHandnote On B-Stat.-I-chapter-3Kim NamjoonneОценок пока нет
- BScIMT 1920 Aug2019 PDFДокумент222 страницыBScIMT 1920 Aug2019 PDFtacamp daОценок пока нет
- Types of Contract FarmingДокумент14 страницTypes of Contract Farmingtacamp daОценок пока нет
- 09 Chapter 3Документ56 страниц09 Chapter 3tacamp daОценок пока нет
- Future of India The Winning LeapДокумент148 страницFuture of India The Winning LeapAsitya DevОценок пока нет
- Course OutlineДокумент4 страницыCourse Outlinetacamp daОценок пока нет
- Tending OperationsДокумент26 страницTending Operationstacamp da100% (2)
- Economics of EcucalyptusДокумент3 страницыEconomics of Ecucalyptustacamp daОценок пока нет
- Foreign Exchange Market: Indicative Forward Rates Indicative Spot RatesДокумент2 страницыForeign Exchange Market: Indicative Forward Rates Indicative Spot Ratestacamp daОценок пока нет
- Cost of Production: Dr. S P SinghДокумент31 страницаCost of Production: Dr. S P Singhtacamp daОценок пока нет
- Us Figures PDFДокумент6 страницUs Figures PDFtacamp daОценок пока нет
- Ooks FOR RadersДокумент12 страницOoks FOR Raderstacamp daОценок пока нет
- Data Range Description Rating NotesДокумент3 страницыData Range Description Rating Notestacamp daОценок пока нет
- NUS Student Investment Society PDFДокумент29 страницNUS Student Investment Society PDFtacamp daОценок пока нет
- David Elliot MIT MAP.1.2Документ59 страницDavid Elliot MIT MAP.1.2tacamp da100% (1)
- Lesson1 1 PDFДокумент14 страницLesson1 1 PDFtacamp daОценок пока нет
- HSBC InvestmentsДокумент52 страницыHSBC Investmentstacamp daОценок пока нет
- Quantitative Analysis For ManagementДокумент100 страницQuantitative Analysis For ManagementErika Rosales80% (5)
- Statistics Definitions From Pagano TextbookДокумент13 страницStatistics Definitions From Pagano TextbookIngenious AngelОценок пока нет
- Fluke - An - pm668Документ6 страницFluke - An - pm668polancomarquezОценок пока нет
- CH 2 - Frequency Analysis and ForecastingДокумент31 страницаCH 2 - Frequency Analysis and ForecastingYaregal Geremew100% (1)
- Unit Plan Nursing ResearchДокумент7 страницUnit Plan Nursing Researchrocky50% (2)
- Bum2413 AssignmentДокумент5 страницBum2413 AssignmentKH200 73NG LIHUAОценок пока нет
- Learning ObjectivesДокумент20 страницLearning ObjectivesMark Christian Dimson GalangОценок пока нет
- Implementation of Mathematica-Assisted Learning To Improve Understanding and Problem-Solving Skills For Prospective TeachersДокумент8 страницImplementation of Mathematica-Assisted Learning To Improve Understanding and Problem-Solving Skills For Prospective TeachersNerru PranutaОценок пока нет
- (P) Worst-Case Design and Margin For Embedded SRAM, 2007Документ6 страниц(P) Worst-Case Design and Margin For Embedded SRAM, 2007DMОценок пока нет
- Data TransformationДокумент58 страницData TransformationMuhamamd Khan MuneerОценок пока нет
- Empirical Rule-Examples (Normal Distribution)Документ17 страницEmpirical Rule-Examples (Normal Distribution)michella vegaОценок пока нет
- Programming Python StatisticsДокумент7 страницProgramming Python StatisticsTate KnightОценок пока нет
- 3 - Introduction To Inferential StatisticsДокумент32 страницы3 - Introduction To Inferential StatisticsVishal ShivhareОценок пока нет
- Syllabus: Cambridge O Level Statistics 4040Документ22 страницыSyllabus: Cambridge O Level Statistics 4040Memona EmmanОценок пока нет
- A Parametric Approach To Nonparametric Statistics: Mayer Alvo Philip L. H. YuДокумент277 страницA Parametric Approach To Nonparametric Statistics: Mayer Alvo Philip L. H. Yuasat12100% (3)
- Deterministic Risk Analysis - "Best Case, Worst Case, Most Likely"Документ25 страницDeterministic Risk Analysis - "Best Case, Worst Case, Most Likely"Başchir CameliaОценок пока нет
- Unit III Probability B.tech 2nd SemДокумент30 страницUnit III Probability B.tech 2nd Sempure handsОценок пока нет
- 2.parameter EstimationДокумент59 страниц2.parameter EstimationLEE LEE LAUОценок пока нет
- Chapter 2 Hypothesis TestingДокумент43 страницыChapter 2 Hypothesis TestingMario M. Ramon100% (7)
- 20 Reliability Testing and VerificationДокумент13 страниц20 Reliability Testing and VerificationrogeriojuruaiaОценок пока нет
- 2 Simple Regression Model Estimation and PropertiesДокумент48 страниц2 Simple Regression Model Estimation and PropertiesMuhammad Chaudhry100% (1)
- Six Sigma BookДокумент218 страницSix Sigma BookAbbas Gujjar Abbas GujjarОценок пока нет
- Slides Prepared by John S. Loucks St. Edward's UniversityДокумент44 страницыSlides Prepared by John S. Loucks St. Edward's UniversityAnkit Mishra100% (1)
- Assignment # 1 - AmmarДокумент7 страницAssignment # 1 - AmmarAmmar AsifОценок пока нет
- Hypothesis TestingДокумент6 страницHypothesis TestingDynamic ClothesОценок пока нет
- (Cigital) 100M Hand Analysis ReportДокумент16 страниц(Cigital) 100M Hand Analysis Reportpokerplayersalliance100% (3)
- Chapter 4Документ17 страницChapter 4JHAN FAI MOOОценок пока нет
- Univariate Analysis and Normality Test Using SAS, Stata, and SpssДокумент38 страницUnivariate Analysis and Normality Test Using SAS, Stata, and SpssEDYLON01Оценок пока нет
- Birla Institute of Technology and Science, Pilani Pilani Campus Instruction DivisionДокумент3 страницыBirla Institute of Technology and Science, Pilani Pilani Campus Instruction DivisionSaurabh ChaubeyОценок пока нет
- Jmapaii Regents Book by Pi Topic PDFДокумент96 страницJmapaii Regents Book by Pi Topic PDFMackaingar WalkerОценок пока нет
- AP Physics 1 Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Physics 1 Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- AP Computer Science A Premium, 2024: 6 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Computer Science A Premium, 2024: 6 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- AP World History: Modern Premium, 2024: Comprehensive Review with 5 Practice Tests + an Online Timed Test OptionОт EverandAP World History: Modern Premium, 2024: Comprehensive Review with 5 Practice Tests + an Online Timed Test OptionРейтинг: 5 из 5 звезд5/5 (1)
- AP English Language and Composition Premium, 2024: 8 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP English Language and Composition Premium, 2024: 8 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- GMAT Prep 2024/2025 For Dummies with Online Practice (GMAT Focus Edition)От EverandGMAT Prep 2024/2025 For Dummies with Online Practice (GMAT Focus Edition)Оценок пока нет
- AP Biology Premium, 2024: Comprehensive Review With 5 Practice Tests + an Online Timed Test OptionОт EverandAP Biology Premium, 2024: Comprehensive Review With 5 Practice Tests + an Online Timed Test OptionОценок пока нет
- How to Be a High School Superstar: A Revolutionary Plan to Get into College by Standing Out (Without Burning Out)От EverandHow to Be a High School Superstar: A Revolutionary Plan to Get into College by Standing Out (Without Burning Out)Рейтинг: 4.5 из 5 звезд4.5/5 (11)
- Digital SAT Reading and Writing Practice Questions: Test Prep SeriesОт EverandDigital SAT Reading and Writing Practice Questions: Test Prep SeriesРейтинг: 5 из 5 звезд5/5 (2)
- AP U.S. History Premium, 2024: Comprehensive Review With 5 Practice Tests + an Online Timed Test OptionОт EverandAP U.S. History Premium, 2024: Comprehensive Review With 5 Practice Tests + an Online Timed Test OptionОценок пока нет
- AP Environmental Science Premium, 2024: 5 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Environmental Science Premium, 2024: 5 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- AP Microeconomics/Macroeconomics Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Microeconomics/Macroeconomics Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- GMAT Foundations of Verbal: Practice Problems in Book and OnlineОт EverandGMAT Foundations of Verbal: Practice Problems in Book and OnlineОценок пока нет
- College Level Anatomy and Physiology: Essential Knowledge for Healthcare Students, Professionals, and Caregivers Preparing for Nursing Exams, Board Certifications, and Beyond Angela GloverОт EverandCollege Level Anatomy and Physiology: Essential Knowledge for Healthcare Students, Professionals, and Caregivers Preparing for Nursing Exams, Board Certifications, and Beyond Angela GloverОценок пока нет
- AP Chemistry Flashcards, Fourth Edition: Up-to-Date Review and PracticeОт EverandAP Chemistry Flashcards, Fourth Edition: Up-to-Date Review and PracticeОценок пока нет
- Digital SAT Prep 2024 For Dummies: Book + 4 Practice Tests Online, Updated for the NEW Digital FormatОт EverandDigital SAT Prep 2024 For Dummies: Book + 4 Practice Tests Online, Updated for the NEW Digital FormatОценок пока нет
- SAT Prep Plus: Unlocked Edition 2022 - 5 Full Length Practice Tests - Behind-the-scenes game-changing answer explanations to each question - Top level strategies, tips and tricks for each sectionОт EverandSAT Prep Plus: Unlocked Edition 2022 - 5 Full Length Practice Tests - Behind-the-scenes game-changing answer explanations to each question - Top level strategies, tips and tricks for each sectionОценок пока нет
- LSAT For Dummies (with Free Online Practice Tests)От EverandLSAT For Dummies (with Free Online Practice Tests)Рейтинг: 4 из 5 звезд4/5 (1)
- Digital SAT Preview: What to Expect + Tips and StrategiesОт EverandDigital SAT Preview: What to Expect + Tips and StrategiesРейтинг: 5 из 5 звезд5/5 (3)
- AP Human Geography Premium, 2024: 6 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Human Geography Premium, 2024: 6 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- The LSAT Law School Admission Test Study Guide Volume I - Reading Comprehension, Logical Reasoning, Writing Sample, and Analytical Reasoning Review Proven Methods for Passing the LSAT Exam With ConfidenceОт EverandThe LSAT Law School Admission Test Study Guide Volume I - Reading Comprehension, Logical Reasoning, Writing Sample, and Analytical Reasoning Review Proven Methods for Passing the LSAT Exam With ConfidenceОценок пока нет
- GMAT Foundations of Math: Start Your GMAT Prep with Online Starter Kit and 900+ Practice ProblemsОт EverandGMAT Foundations of Math: Start Your GMAT Prep with Online Starter Kit and 900+ Practice ProblemsРейтинг: 4 из 5 звезд4/5 (7)
- AP Physics 2 Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОт EverandAP Physics 2 Premium, 2024: 4 Practice Tests + Comprehensive Review + Online PracticeОценок пока нет
- Medical English Dialogues: Clear & Simple Medical English Vocabulary for ESL/EFL LearnersОт EverandMedical English Dialogues: Clear & Simple Medical English Vocabulary for ESL/EFL LearnersОценок пока нет