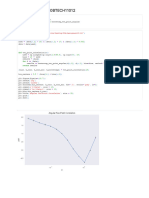
Вам также может понравиться
- Peer Review Assignment 4: InstructionsДокумент17 страницPeer Review Assignment 4: Instructionshamza omar100% (1)
- Exp 4Документ10 страницExp 4jayОценок пока нет
- AI_ManualДокумент69 страницAI_ManualDev SejvaniОценок пока нет
- Karmbir 19 MLДокумент20 страницKarmbir 19 MLdeepakyadavyadav987Оценок пока нет
- Mlaifile1 3Документ27 страницMlaifile1 3Krishna kumarОценок пока нет
- AIDS_DM Using Python_Lab programsДокумент19 страницAIDS_DM Using Python_Lab programsyelubandirenukavidyadhariОценок пока нет
- 2.3 Aiml RishitДокумент7 страниц2.3 Aiml Rishitheex.prosОценок пока нет
- ML LAB Mannual - IndexДокумент29 страницML LAB Mannual - IndexNisahd hiteshОценок пока нет
- Planar Data Classification With One Hidden Layer v5Документ19 страницPlanar Data Classification With One Hidden Layer v5sn3fruОценок пока нет
- Homework 1: CS 178: Machine Learning: Spring 2020Документ4 страницыHomework 1: CS 178: Machine Learning: Spring 2020Jonathan NguyenОценок пока нет
- Introduction To Python and Computer Programming 1704298503Документ44 страницыIntroduction To Python and Computer Programming 1704298503el.tico.138623Оценок пока нет
- Practical V - PYTHONДокумент50 страницPractical V - PYTHONE01202913-KARTHICK S MCAОценок пока нет
- Designing Machine Learning Workflows in Python Chapter2Документ39 страницDesigning Machine Learning Workflows in Python Chapter2FgpeqwОценок пока нет
- PS Project - Jupyter NotebookДокумент6 страницPS Project - Jupyter NotebookM. Mobeen KhattakОценок пока нет
- EDA Lab ManualДокумент93 страницыEDA Lab ManualYash Rox100% (2)
- Final - DNN - Hands - On - Jupyter NotebookДокумент8 страницFinal - DNN - Hands - On - Jupyter Notebooktango charlie25% (4)
- Linear and Logistic RegressionДокумент6 страницLinear and Logistic RegressionMahevish FatimaОценок пока нет
- 21BEC505 Exp2Документ7 страниц21BEC505 Exp2jayОценок пока нет
- Aim: Write A R Script To Demonstrate The Use of Matrix Do Some ComputationsДокумент4 страницыAim: Write A R Script To Demonstrate The Use of Matrix Do Some ComputationsdwrreОценок пока нет
- Lab 8 DSPДокумент9 страницLab 8 DSPzubair tahirОценок пока нет
- ML 4 to 9 keyurДокумент21 страницаML 4 to 9 keyurjay limbadОценок пока нет
- Simple Case Study of Implementing K Means Clustering On The IRIS DatasetДокумент4 страницыSimple Case Study of Implementing K Means Clustering On The IRIS Datasetgargwork1990Оценок пока нет
- DM Slip SolutionsДокумент24 страницыDM Slip Solutions09.Khadija Gharatkar100% (1)
- PGM 7Документ3 страницыPGM 7badeniОценок пока нет
- Datamining ReportДокумент37 страницDatamining ReportPranav ViswanathanОценок пока нет
- AD3411- 1 to 5Документ11 страницAD3411- 1 to 5Raj kamalОценок пока нет
- Data Mining DBSCAN ClusteringДокумент1 страницаData Mining DBSCAN ClusteringSwappy BoiОценок пока нет
- DNN ALL Practical 28Документ34 страницыDNN ALL Practical 284073Himanshu PatleОценок пока нет
- Maxbox - Starter68 Machine LearningДокумент5 страницMaxbox - Starter68 Machine LearningMax KleinerОценок пока нет
- PythonfileДокумент36 страницPythonfilecollection58209Оценок пока нет
- Solution First Point ML-HW4Документ6 страницSolution First Point ML-HW4Juan Sebastian Otálora Montenegro100% (1)
- 1 An Introduction To Machine Learning With Scikit LearnДокумент2 страницы1 An Introduction To Machine Learning With Scikit Learnkehinde.ogunleye007Оценок пока нет
- Final Practical File 2022-23Документ87 страницFinal Practical File 2022-23Kuldeep SinghОценок пока нет
- Worksheet-1 (Python)Документ9 страницWorksheet-1 (Python)rizwana fathimaОценок пока нет
- Carreon WS06Документ4 страницыCarreon WS06Keneth CarreonОценок пока нет
- Classification Is For Predicting Type and Regression Is For Predicting ValueДокумент4 страницыClassification Is For Predicting Type and Regression Is For Predicting ValueranaОценок пока нет
- 178 hw1Документ4 страницы178 hw1Vijay kumarОценок пока нет
- ML With Python PracticalДокумент22 страницыML With Python Practicaln58648017Оценок пока нет
- CSE 3024: Web Mining Lab Assessment - 3 Decision Tree vs Naive Bayes PerformanceДокумент13 страницCSE 3024: Web Mining Lab Assessment - 3 Decision Tree vs Naive Bayes PerformanceNikitha ReddyОценок пока нет
- Assignment8 EP20BTECH11012Документ2 страницыAssignment8 EP20BTECH11012kuteniharikaОценок пока нет
- R PrgmsДокумент12 страницR PrgmsRadhiyadevi ChinnasamyОценок пока нет
- PatternДокумент1 страницаPatternahmadkhalilОценок пока нет
- SFB EdaДокумент13 страницSFB EdaPraneeth AluruОценок пока нет
- Roll NO 2020Документ8 страницRoll NO 2020Ali MohsinОценок пока нет
- Capstone Project Report (Digit-Recognition Using CNN)Документ11 страницCapstone Project Report (Digit-Recognition Using CNN)seenuОценок пока нет
- Urmi ML Practical FileДокумент37 страницUrmi ML Practical Filebekar kaОценок пока нет
- FML LabFile 7expsДокумент37 страницFML LabFile 7expsKunal SainiОценок пока нет
- House Price Prediction Using Machine Learning in PythonДокумент13 страницHouse Price Prediction Using Machine Learning in PythonMayank Vasisth GandhiОценок пока нет
- #Create Vector of Numeric Values #Display Class of VectorДокумент10 страниц#Create Vector of Numeric Values #Display Class of VectorAnooj SrivastavaОценок пока нет
- 1.diagnosis Using MLДокумент69 страниц1.diagnosis Using MLChoral WealthОценок пока нет
- Machine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Документ2 страницыMachine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Penchal DoggalaОценок пока нет
- Comparison of Various System Identification Methods For A MISO SystemДокумент16 страницComparison of Various System Identification Methods For A MISO SystemSashank Varma JampanaОценок пока нет
- PCA Guide: When, Why, How and Feature ImportanceДокумент9 страницPCA Guide: When, Why, How and Feature ImportanceRaj kumarОценок пока нет
- DM PracticeДокумент15 страницDM Practice66 Rohit PatilОценок пока нет
- Tillämpad Maskininlärning - Labb-1Документ17 страницTillämpad Maskininlärning - Labb-1baselОценок пока нет
- Fds AnswersДокумент53 страницыFds AnswerssaranyatvcetОценок пока нет
- Knn1 HouseVotesДокумент2 страницыKnn1 HouseVotesJoe1Оценок пока нет
- KRAI PracticalДокумент14 страницKRAI PracticalContact VishalОценок пока нет
- Logistic RegressionДокумент10 страницLogistic RegressionChichi Jnr100% (1)
- Java Environment Setup for Selenium TestingДокумент7 страницJava Environment Setup for Selenium TestingJoe1Оценок пока нет
- Java Core Concepts for Selenium AutomationДокумент9 страницJava Core Concepts for Selenium AutomationJoe1Оценок пока нет
- Power BIДокумент32 страницыPower BIDeepak Arya100% (4)
- Data Dictionary - Unsupervised Customers PDFДокумент1 страницаData Dictionary - Unsupervised Customers PDFJoe1Оценок пока нет
- Selenium 1: Introduction To SeleniumДокумент7 страницSelenium 1: Introduction To SeleniumpriyanshuОценок пока нет
- Troubleshooting TipsДокумент3 страницыTroubleshooting TipsJoe1Оценок пока нет
- POMДокумент8 страницPOMJoe1Оценок пока нет
- Selenium 3 Testing Process Part 2Документ7 страницSelenium 3 Testing Process Part 2Joe1Оценок пока нет
- Selenium Testing ProcessДокумент9 страницSelenium Testing ProcessJoe1Оценок пока нет
- MATHДокумент52 страницыMATHJoe1Оценок пока нет
- COALESCE() - Learn how to handle null values in SQLДокумент13 страницCOALESCE() - Learn how to handle null values in SQLJoe1Оценок пока нет
- Employees Mod DB PDFДокумент1 страницаEmployees Mod DB PDFJoe1Оценок пока нет
- Machine Learning Reflections WorksheetДокумент3 страницыMachine Learning Reflections WorksheetJoe1Оценок пока нет
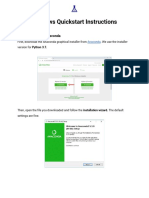
- Windows Quickstart Instructions: Step 1: Download AnacondaДокумент7 страницWindows Quickstart Instructions: Step 1: Download AnacondaJoe1Оценок пока нет
- Hive and ImpalaДокумент46 страницHive and ImpalaJoe1Оценок пока нет
- Big Data Hadoop and Spark Developer: Hbase SupportДокумент27 страницBig Data Hadoop and Spark Developer: Hbase SupportJoe1Оценок пока нет
- HDFS and YARNДокумент91 страницаHDFS and YARNJoe1Оценок пока нет
- Worksheet 1Документ3 страницыWorksheet 1Joe1Оценок пока нет
- PigДокумент39 страницPigJoe1Оценок пока нет
- SELECT From NobelДокумент13 страницSELECT From NobelJoe1Оценок пока нет
- Decision Tree and EDA With Functions: Import Pandas As PDДокумент9 страницDecision Tree and EDA With Functions: Import Pandas As PDJoe1Оценок пока нет
- SELECT From WORLD TutorialДокумент13 страницSELECT From WORLD TutorialJoe1Оценок пока нет
- Knn1 MinMaxScalarДокумент13 страницKnn1 MinMaxScalarJoe1Оценок пока нет
- Business ScenarioДокумент1 страницаBusiness ScenarioJoe1Оценок пока нет
- Beautiful Soup 4Документ78 страницBeautiful Soup 4Siva TarunОценок пока нет
- NycДокумент12 страницNycJoe1Оценок пока нет
- Knn1 HouseVotesДокумент2 страницыKnn1 HouseVotesJoe1Оценок пока нет
- Regular Expressions in PythonДокумент16 страницRegular Expressions in PythonJoe1Оценок пока нет
- Random Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBДокумент17 страницRandom Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBJoe1Оценок пока нет
- Random Forest: Random Forest Has Classifier For Classification and Regressor For RegressionДокумент9 страницRandom Forest: Random Forest Has Classifier For Classification and Regressor For RegressionJoe1Оценок пока нет
- 1-Theory of Programming Languages - IntroductionДокумент19 страниц1-Theory of Programming Languages - IntroductionGES ISLAMIA PATTOKIОценок пока нет
- Mckinsey Driving Impact at Scale From Automation and AIДокумент100 страницMckinsey Driving Impact at Scale From Automation and AIpanigrahivikashОценок пока нет
- Hand Gesture Recognition Based On Computer Vision: A Review of TechniquesДокумент29 страницHand Gesture Recognition Based On Computer Vision: A Review of TechniquespradyumnОценок пока нет
- University Michigan: BeginnerДокумент26 страницUniversity Michigan: BeginnerMfundo ShabalalaОценок пока нет
- NNFL LPДокумент4 страницыNNFL LPKrushnasamy SuramaniyanОценок пока нет
- Mr. Manmeet SinghДокумент9 страницMr. Manmeet SinghChinmoy HazarikaОценок пока нет
- Emerging Technology AssigmentДокумент2 страницыEmerging Technology AssigmentSalih AnwarОценок пока нет
- SAR AI PaperДокумент26 страницSAR AI PaperDharmesh PanchalОценок пока нет
- Artificial Intelligence How It Changes The FutureДокумент89 страницArtificial Intelligence How It Changes The FutureShin Ito100% (1)
- Human-Centered Artificial Intelligence: Mohamed Chetouani Virginia Dignum Paul Lukowicz Carles SierraДокумент434 страницыHuman-Centered Artificial Intelligence: Mohamed Chetouani Virginia Dignum Paul Lukowicz Carles Sierrajsprados2618Оценок пока нет
- Analyzing a Hotel Booking SystemДокумент29 страницAnalyzing a Hotel Booking SystemKamal FortniteОценок пока нет
- Caixinha 2016Документ16 страницCaixinha 201611Dewi Meiliyan Ningrum dewimeiliyan.2020Оценок пока нет
- A Sollution To Score 8 in IELTS Writing - UnlockedДокумент53 страницыA Sollution To Score 8 in IELTS Writing - UnlockedJeffery GulОценок пока нет
- Whats FairДокумент12 страницWhats FairfactorialthreeОценок пока нет
- Segmap: Segment-Based Mapping and Localization Using Data-Driven DescriptorsДокумент18 страницSegmap: Segment-Based Mapping and Localization Using Data-Driven Descriptorsxingwu jiОценок пока нет
- Level 4 Module 2 - UnlockedДокумент57 страницLevel 4 Module 2 - UnlockedDavid MartinezОценок пока нет
- Artificial Intelligence and Machine Learning-LylaДокумент3 страницыArtificial Intelligence and Machine Learning-LylaARJUN MURALIОценок пока нет
- Chockalingam, Venkatesh Bharadwaj S Spider, The Research and Development Club of NIT TrichyДокумент1 страницаChockalingam, Venkatesh Bharadwaj S Spider, The Research and Development Club of NIT TrichyvenkithebossОценок пока нет
- Checklist To Become Customer-First Neo Bank - 2021 Proven SolutionДокумент14 страницChecklist To Become Customer-First Neo Bank - 2021 Proven SolutionMarketing- INTОценок пока нет
- Meta Q3 2022 Earnings Call TranscriptДокумент19 страницMeta Q3 2022 Earnings Call Transcriptnamit singalОценок пока нет
- Machine Learning and Artificial Intelligence As A Complement To Condition Monitoring in A Predictive Maintenance SettingДокумент20 страницMachine Learning and Artificial Intelligence As A Complement To Condition Monitoring in A Predictive Maintenance SettingHoa Dinh NguyenОценок пока нет
- Introduction to RoboticsДокумент29 страницIntroduction to RoboticsMae PaviaОценок пока нет
- Neural Networks: Chapter 20, Section 5Документ21 страницаNeural Networks: Chapter 20, Section 5api-19801502Оценок пока нет
- 2024 Sustainability TrendsДокумент6 страниц2024 Sustainability Trendsmarciasn1961Оценок пока нет
- MSMOTE Improving Classification Performance When Training Data Is ImbalancedДокумент5 страницMSMOTE Improving Classification Performance When Training Data Is ImbalancedNguyễn TomОценок пока нет
- Diffusion of Artificial Intelligence in Human Resource Domain With Specific Reference To Recruitment Function A Literature Review StudyДокумент8 страницDiffusion of Artificial Intelligence in Human Resource Domain With Specific Reference To Recruitment Function A Literature Review StudyInternational Journal of Innovative Science and Research TechnologyОценок пока нет
- AI Unit III Part 2Документ72 страницыAI Unit III Part 2Shilpa SahuОценок пока нет
- Aima 17Документ1 страницаAima 17Summer TriangleОценок пока нет
- Exploring The Problems of MankindДокумент5 страницExploring The Problems of Mankindapi-537096690Оценок пока нет
- Ethics and Artificial Intelligence in Investment Management - OnlineДокумент18 страницEthics and Artificial Intelligence in Investment Management - Onlineramachandra rao sambangiОценок пока нет