Вам также может понравиться
- Frases para Tarjeta de Invitación Al Acto de EgresadosДокумент2 страницыFrases para Tarjeta de Invitación Al Acto de EgresadosLeonel Bezier75% (4)
- Plan de Desarrollo de SoftwareДокумент14 страницPlan de Desarrollo de SoftwareJonathan Muñoz Aleman0% (1)
- Ejercicios Resueltos de ProbabilidadesДокумент25 страницEjercicios Resueltos de ProbabilidadesJose Miguel Avilez Bozo100% (3)
- Acantosis NigricansДокумент2 страницыAcantosis Nigricansshirleyperalta100% (2)
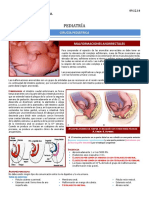
- Tema 9 (Malformaciones Anorrectales)Документ6 страницTema 9 (Malformaciones Anorrectales)Darliana Ospina DuarteОценок пока нет
- Learn Yaml in Y MinutesДокумент9 страницLearn Yaml in Y MinutesAmilcar de Jesus Gómez CogolloОценок пока нет
- Arte y PsicoanalisisДокумент111 страницArte y PsicoanalisisEric FuentesОценок пока нет
- La AnemiaДокумент4 страницыLa AnemiaNanYeni100% (5)
- Formas CuadraticasДокумент12 страницFormas CuadraticasPatricia PuigОценок пока нет
- PEC1 Solucion PDFДокумент18 страницPEC1 Solucion PDFJorge BenítezОценок пока нет
- ENSAYO 2 LengДокумент12 страницENSAYO 2 LengKarina RodriguezОценок пока нет
- Encriptacion 090108 PDFДокумент8 страницEncriptacion 090108 PDFAlejandro Huarachi TitoОценок пока нет
- Decifrando El ExadepДокумент53 страницыDecifrando El ExadepJose Alexander Martin Medina100% (4)
- Guia de Lab 1Документ20 страницGuia de Lab 1chahum47Оценок пока нет
- Ejercicio Refinadores Textura en Forma de LingotesДокумент11 страницEjercicio Refinadores Textura en Forma de LingotesLeison Ocoró CarabalíОценок пока нет
- Sofia RmarkДокумент25 страницSofia Rmarkjhon erick montañez ponceОценок пока нет
- Sesion 2Документ20 страницSesion 2Paula LoperaОценок пока нет
- Practica1 RДокумент12 страницPractica1 RRaymundo LumbrerasОценок пока нет
- Para Declarar Variables en PHP Debemos Anteponer El SignoДокумент9 страницPara Declarar Variables en PHP Debemos Anteponer El SignoReyna Villar LopezОценок пока нет
- Practica 0Документ12 страницPractica 0Valeria ToledoОценок пока нет
- Practica TLP 1819Документ11 страницPractica TLP 1819Luis Moreno GonzalezОценок пока нет
- Iniciacion A RДокумент11 страницIniciacion A RvaruthapaОценок пока нет
- Árboles de VerdadДокумент40 страницÁrboles de VerdadRosaVelazquezОценок пока нет
- Introducción A R y Tipos de VariablesДокумент9 страницIntroducción A R y Tipos de VariablesAlejandra SajquinОценок пока нет
- Tarea IndividualДокумент9 страницTarea IndividualJavier SanchezОценок пока нет
- Trabajo Definitivo Ramboarnoldshuarnegerrobocopjordy 1Документ20 страницTrabajo Definitivo Ramboarnoldshuarnegerrobocopjordy 1Jordy Alexander Rodríguez RosalesОценок пока нет
- Inspeccionar variables y cambiar clases en RДокумент7 страницInspeccionar variables y cambiar clases en Rcarlos andres hernandez maceaОценок пока нет
- Funciones PHP cadenas y fechasДокумент17 страницFunciones PHP cadenas y fechasErwin VidesОценок пока нет
- Clase 2 - Web ScrapingДокумент15 страницClase 2 - Web ScrapingmagonzalezОценок пока нет
- Python 3Документ49 страницPython 3Karen JaureguiОценок пока нет
- Algoritmos Computacionales U5Документ6 страницAlgoritmos Computacionales U5BryanMtzI11Оценок пока нет
- MEDA CasoTitanicДокумент19 страницMEDA CasoTitanicÁngel David TorresОценок пока нет
- (UNED) Apuntes de Matemáticas BásicasДокумент16 страниц(UNED) Apuntes de Matemáticas Básicasstrokes142Оценок пока нет
- Tarea 4Документ12 страницTarea 4Arnau Monzo FerragutОценок пока нет
- Clasificación de cangrejos mediante árboles de decisión en RДокумент8 страницClasificación de cangrejos mediante árboles de decisión en RVictor Jose Castro PinОценок пока нет
- Complemento Unidad de NúmerosДокумент11 страницComplemento Unidad de NúmerosMatiasОценок пока нет
- Algoritmos de CifradoДокумент3 страницыAlgoritmos de CifradoCarlos BrydenОценок пока нет
- Prácticas RДокумент35 страницPrácticas RJackie Denisse Maldonado MojarrangoОценок пока нет
- GUIAMATLABДокумент19 страницGUIAMATLABhitomisan01Оценок пока нет
- Expresiones Regulares en Java - ChuWiki PDFДокумент6 страницExpresiones Regulares en Java - ChuWiki PDFKarla Guadalupe Carrillo HernandezОценок пока нет
- Clase 27. Python 3Документ46 страницClase 27. Python 3Fernando Enrique SilvaОценок пока нет
- Documento RecuperadoДокумент358 страницDocumento RecuperadoRoberto GuevaraОценок пока нет
- Simplificación de operaciones algebraicasДокумент13 страницSimplificación de operaciones algebraicasMizza RodriguezОценок пока нет
- 07 PRG FytsykAДокумент6 страниц07 PRG FytsykAArtur FytsykОценок пока нет
- FORMULAS deДокумент190 страницFORMULAS dehfuentes0100% (1)
- Actividad Aprendizaje-LyA Tema 2Документ13 страницActividad Aprendizaje-LyA Tema 2Tom BahenaОценок пока нет
- Exel y MacrosДокумент19 страницExel y MacrosAnonymous IWpXYQfH3Оценок пока нет
- Enunciados Verbales AlgebraicosДокумент5 страницEnunciados Verbales AlgebraicosMUS01Оценок пока нет
- BDD RelacionalДокумент27 страницBDD RelacionalMariachi GalaОценок пока нет
- Integridad Referencial de MySQLДокумент4 страницыIntegridad Referencial de MySQLChristian AyaОценок пока нет
- LogaritmosДокумент9 страницLogaritmosNicolasОценок пока нет
- Funciones básicas en R para análisis de datosДокумент6 страницFunciones básicas en R para análisis de datosOscar Hernan Arias GomezОценок пока нет
- Criptograma... Lengua y ComunicaciónДокумент4 страницыCriptograma... Lengua y ComunicacióncruxholОценок пока нет
- Expresión Regular para Coincidir Con Un Paréntesis LiteralДокумент4 страницыExpresión Regular para Coincidir Con Un Paréntesis LiteralErnesto MoraОценок пока нет
- Actividad Codificacion LZWДокумент4 страницыActividad Codificacion LZWHarairis Brunet CesarОценок пока нет
- PDF Metodos y Tecnicas de EncriptacionДокумент5 страницPDF Metodos y Tecnicas de Encriptacioncarlos mamaniОценок пока нет
- MDS 5Документ19 страницMDS 5winhezedОценок пока нет
- Modelo Probabilistico Del LenguajeДокумент4 страницыModelo Probabilistico Del LenguajeMakariwinОценок пока нет
- El Contador de ArenaДокумент5 страницEl Contador de Arenasosputa0% (1)
- Expresiones Regulares en JavaДокумент8 страницExpresiones Regulares en JavaGrisel JimenezОценок пока нет
- Taller 02 Proyecto de tesis con stringrДокумент2 страницыTaller 02 Proyecto de tesis con stringrFrank De La Cruz UrquizaОценок пока нет
- (P2-1) Estadistica DescriptivaДокумент24 страницы(P2-1) Estadistica DescriptivaDavid AyalaОценок пока нет
- CombinaiconesДокумент16 страницCombinaiconesMariselОценок пока нет
- 2.4 Transformaciones Elementales Por Renglón. Escalonamiento de Una Matriz. Rango de Una MatrizДокумент3 страницы2.4 Transformaciones Elementales Por Renglón. Escalonamiento de Una Matriz. Rango de Una MatrizJessika GuzmanОценок пока нет
- Programacion en C Conceptos Avanzados PRДокумент22 страницыProgramacion en C Conceptos Avanzados PRadecara543Оценок пока нет
- Álgebra abstracta aplicada en ingeniería: casos de aplicación en sistemas difusos tipo 1 y tipo 2От EverandÁlgebra abstracta aplicada en ingeniería: casos de aplicación en sistemas difusos tipo 1 y tipo 2Оценок пока нет
- Sobre el crecimiento de las redes socialesОт EverandSobre el crecimiento de las redes socialesРейтинг: 4 из 5 звезд4/5 (1)
- Regresion Multiple PDFДокумент1 страницаRegresion Multiple PDFJose Miguel Avilez BozoОценок пока нет
- Listado 04 SolucionДокумент5 страницListado 04 SolucionJose Miguel Avilez BozoОценок пока нет
- Formulario Test HipotesisДокумент6 страницFormulario Test HipotesisJose Miguel Avilez BozoОценок пока нет
- RtweetДокумент1 страницаRtweetJose Miguel Avilez BozoОценок пока нет
- MultiДокумент3 страницыMultiJose Miguel Avilez BozoОценок пока нет
- Prueba de Jarque-BeraДокумент1 страницаPrueba de Jarque-BeraJose Miguel Avilez BozoОценок пока нет
- TareaДокумент5 страницTareaJose Miguel Avilez BozoОценок пока нет
- Tarea N3Документ4 страницыTarea N3Jose Miguel Avilez BozoОценок пока нет
- Teorema de GerschgorinДокумент4 страницыTeorema de GerschgorinJose Miguel Avilez BozoОценок пока нет
- TareaДокумент5 страницTareaJose Miguel Avilez BozoОценок пока нет
- Matemáticas Bachillerato LOGSE - CombinatoriaДокумент11 страницMatemáticas Bachillerato LOGSE - CombinatoriaJose Miguel Avilez BozoОценок пока нет
- Tarea #1 - 2017Документ10 страницTarea #1 - 2017Jose Miguel Avilez BozoОценок пока нет
- Practica 1Документ6 страницPractica 1Jose Miguel Avilez BozoОценок пока нет
- Certamen Pauta 1 2011 2Документ9 страницCertamen Pauta 1 2011 2Jonathan Ovalle LabrinОценок пока нет
- Progrma Series de Tiempo2 2014Документ3 страницыProgrma Series de Tiempo2 2014Jose Miguel Avilez BozoОценок пока нет
- Certamen 1 - 2010Документ4 страницыCertamen 1 - 2010Jose Miguel Avilez BozoОценок пока нет
- Pauta Test 1Документ22 страницыPauta Test 1Jose Miguel Avilez BozoОценок пока нет
- Pauta Certamen2 (523265-1-2012)Документ4 страницыPauta Certamen2 (523265-1-2012)Jose Miguel Avilez BozoОценок пока нет
- Pauta Certamen2 (523265-1-2012)Документ4 страницыPauta Certamen2 (523265-1-2012)Jose Miguel Avilez BozoОценок пока нет
- Ejecicio 1Документ2 страницыEjecicio 1Jose Miguel Avilez BozoОценок пока нет
- Lab1 2Документ8 страницLab1 2Jose Miguel Avilez BozoОценок пока нет
- Ayudantia 2Документ3 страницыAyudantia 2Jose Miguel Avilez BozoОценок пока нет
- Tarea 6, Matematica I (529103)Документ2 страницыTarea 6, Matematica I (529103)Jose Miguel Avilez BozoОценок пока нет
- Microsoft Word - Syllabus 523413-2013Документ2 страницыMicrosoft Word - Syllabus 523413-2013Jose Miguel Avilez BozoОценок пока нет
- UNIVERSIDAD DE CONCEPCION FACULTAD DE CIENCIAS FISICAS Y MATEMATICAS Matemática II ListadoДокумент2 страницыUNIVERSIDAD DE CONCEPCION FACULTAD DE CIENCIAS FISICAS Y MATEMATICAS Matemática II ListadoJose Miguel Avilez BozoОценок пока нет
- Guia 1Документ2 страницыGuia 1Nataly Grace Z MОценок пока нет
- Intro RДокумент12 страницIntro RJose Miguel Avilez BozoОценок пока нет
- Linares, S. y Velázquez, G. (2012) - Capítulo 11. La Conformación Histórica Del Sistema UrbanoДокумент18 страницLinares, S. y Velázquez, G. (2012) - Capítulo 11. La Conformación Histórica Del Sistema UrbanoMaia HieseОценок пока нет
- Género, ciudadanía y derechos humanos en América LatinaДокумент4 страницыGénero, ciudadanía y derechos humanos en América LatinaAlicia IpiñaОценок пока нет
- Estratigrafía COДокумент6 страницEstratigrafía COCristina HerreraОценок пока нет
- Ejemplos de Campos GravitatoriosДокумент3 страницыEjemplos de Campos GravitatoriosCohorona RamiiroОценок пока нет
- Infografia Derechos Humanos Grupo 7Документ2 страницыInfografia Derechos Humanos Grupo 7MelanieОценок пока нет
- CampoДокумент8 страницCampoClaudio VasquezОценок пока нет
- Conversion de AccionДокумент10 страницConversion de AccionPaola NoyaОценок пока нет
- Sentidos PDFДокумент31 страницаSentidos PDFKely Stefania NARVAEZ GAVIRIAОценок пока нет
- Copia Simple LegalizadaДокумент2 страницыCopia Simple Legalizadaangel albertoОценок пока нет
- Enfermería, y Características de La Ciencia.Документ2 страницыEnfermería, y Características de La Ciencia.Miguel LópezОценок пока нет
- SNC, SNP y SNAДокумент24 страницыSNC, SNP y SNACristian Castillo MakkoukdjiОценок пока нет
- Porque Soy Un Pueblo CelosoДокумент34 страницыPorque Soy Un Pueblo CelosoraguerreОценок пока нет
- Analisis LoiДокумент2 страницыAnalisis LoiDaniel Vargas CeliОценок пока нет
- Teatro Político DefДокумент2 страницыTeatro Político DefGramscitoОценок пока нет
- Trading Vip Opciones VanillaДокумент3 страницыTrading Vip Opciones VanillaPaul VillalvaОценок пока нет
- Instituto Tecnológico Superior de Las ChoapasДокумент4 страницыInstituto Tecnológico Superior de Las Choapasrommel alfonso bolainaОценок пока нет
- Oferta Academica Senescyt 2018 para WebДокумент108 страницOferta Academica Senescyt 2018 para WebMadison MadisonОценок пока нет
- Casos Clinicos - Medicina IiДокумент45 страницCasos Clinicos - Medicina IiJhosep Quispe NuñuveroОценок пока нет
- Una Mirada de Fe PDFДокумент94 страницыUna Mirada de Fe PDFHarold Hernández CMОценок пока нет
- Folleto Tríptico Sida VihДокумент2 страницыFolleto Tríptico Sida VihLourdes M.Оценок пока нет
- 2016-12-14Документ128 страниц2016-12-14Libertad de Expresión YucatánОценок пока нет
- Zonificacion La Florida FinalДокумент38 страницZonificacion La Florida FinalLuciano Héctor AndradeОценок пока нет
- Apersonamiento en El Caso Violacion AgravadaДокумент1 страницаApersonamiento en El Caso Violacion Agravadasoledad ayala b.Оценок пока нет