Вам также может понравиться
- Oracle RunbookДокумент198 страницOracle RunbookKoushikKc ChatterjeeОценок пока нет
- ELEKTROPOKRETAČДокумент18 страницELEKTROPOKRETAČNedim PeštekОценок пока нет
- Introduction To Thermal Sciences Thermodynamics Fluid Dynamics Heat Transfer 1984 PDFДокумент465 страницIntroduction To Thermal Sciences Thermodynamics Fluid Dynamics Heat Transfer 1984 PDFleonard1971100% (2)
- Gigold PDFДокумент61 страницаGigold PDFSurender SinghОценок пока нет
- Pakistan List of Approved Panel PhysicianssДокумент5 страницPakistan List of Approved Panel PhysicianssGulzar Ahmad RawnОценок пока нет
- Internship Report On Effects of Promotion System On Employee Job Satisfaction of Janata Bank Ltd.Документ57 страницInternship Report On Effects of Promotion System On Employee Job Satisfaction of Janata Bank Ltd.Tareq Alam100% (1)
- DRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!От EverandDRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!Оценок пока нет
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОт EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОценок пока нет
- Introduction To PostgresqlДокумент54 страницыIntroduction To PostgresqlTien Nguyen ManhОценок пока нет
- Cheatsheet: Postgresql Monitoring: More Info More InfoДокумент2 страницыCheatsheet: Postgresql Monitoring: More Info More InfoCheck ATОценок пока нет
- PT Vol1-3 PDFДокумент100 страницPT Vol1-3 PDFshafeeq1985gmailОценок пока нет
- Dba MatДокумент240 страницDba MatKranthi KumarОценок пока нет
- Dataguard - MyunderstandingДокумент3 страницыDataguard - Myunderstandingabdulgani11Оценок пока нет
- Build and Deploy ODM Container With DockerДокумент4 страницыBuild and Deploy ODM Container With DockerArnab Mukherjee0% (1)
- Analyzing Oracle TraceДокумент13 страницAnalyzing Oracle TraceChen XuОценок пока нет
- Consults DBAДокумент34 страницыConsults DBAMabu DbaОценок пока нет
- Oracle To Azure PostgreSQL Migration CookbookДокумент13 страницOracle To Azure PostgreSQL Migration CookbookErik CastroОценок пока нет
- SQL Select From V$SGAДокумент16 страницSQL Select From V$SGAsaravanand1983100% (2)
- Storing Non-Relational Data in AzureДокумент41 страницаStoring Non-Relational Data in AzuresunilchopseyОценок пока нет
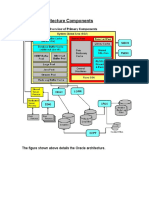
- 001 ArchitectureДокумент26 страниц001 ArchitecturechensuriyanОценок пока нет
- DWDM Unit-2 PDFДокумент149 страницDWDM Unit-2 PDFmayankОценок пока нет
- DataStorage ConsidirationsДокумент9 страницDataStorage ConsidirationsMadhavan EyunniОценок пока нет
- Edb - Bart - Qs - 7 Quick Start Guide For RHEL-CentOS 7Документ7 страницEdb - Bart - Qs - 7 Quick Start Guide For RHEL-CentOS 7AntonioОценок пока нет
- DBA - Oracle Golden Gate 12 - Bidirectional Replication - ActivДокумент14 страницDBA - Oracle Golden Gate 12 - Bidirectional Replication - Activwish_newОценок пока нет
- Refresh Test Database From Production Database ProcedureДокумент9 страницRefresh Test Database From Production Database ProcedureKarthik AquarisОценок пока нет
- Database Architecture Oracle DbaДокумент41 страницаDatabase Architecture Oracle DbaImran ShaikhОценок пока нет
- Oracle DBA Faq'sДокумент67 страницOracle DBA Faq'sdeepakkacholeОценок пока нет
- How To Stabilize The Execution Plan Using SQL PLAN BaselineДокумент3 страницыHow To Stabilize The Execution Plan Using SQL PLAN BaselinenizamОценок пока нет
- Backup and Recovery ScriptsДокумент4 страницыBackup and Recovery ScriptsSHAHID FAROOQ100% (1)
- Rman TutorialДокумент20 страницRman TutorialRama Krishna PasupulettiОценок пока нет
- OGG HandsOnLabДокумент11 страницOGG HandsOnLabnt29Оценок пока нет
- Data Guard Broker PDFДокумент370 страницData Guard Broker PDFjuberОценок пока нет
- QueriesДокумент31 страницаQueriesrajababhiОценок пока нет
- ORACLE-BASE - Materialized Views in OracleДокумент5 страницORACLE-BASE - Materialized Views in OracleRandall MayОценок пока нет
- Tuning The Redolog Buffer Cache and Resolving Redo Latch ContentionДокумент5 страницTuning The Redolog Buffer Cache and Resolving Redo Latch ContentionMelissa MillerОценок пока нет
- Golden Gate Oracle ReplicationДокумент3 страницыGolden Gate Oracle ReplicationCynthiaОценок пока нет
- EDB High Availability Scalability v1.0Документ23 страницыEDB High Availability Scalability v1.0Paohua ChuangОценок пока нет
- Data GardДокумент8 страницData GardPradeep ReddyОценок пока нет
- ODG 12cR2Документ176 страницODG 12cR2Rogério Pereira FalconeОценок пока нет
- Oracle Flashback TechnologyДокумент5 страницOracle Flashback TechnologymonsonОценок пока нет
- Cassandra Installation ReviewДокумент6 страницCassandra Installation ReviewjoiedevieОценок пока нет
- Active Dataguard Database Using RMAN DUPLICATEДокумент10 страницActive Dataguard Database Using RMAN DUPLICATEZakir HossenОценок пока нет
- Knowledge Transfer Data Redaction On EnterpriseDBДокумент19 страницKnowledge Transfer Data Redaction On EnterpriseDBGuntur KsОценок пока нет
- Joe Sack Performance Troubleshooting With Wait StatsДокумент56 страницJoe Sack Performance Troubleshooting With Wait StatsAamöd ThakürОценок пока нет
- Module 1 - Oracle ArchitectureДокумент110 страницModule 1 - Oracle ArchitectureKranthi KumarОценок пока нет
- AWS Database Migration Service: Done By, M.Manoj KlementДокумент27 страницAWS Database Migration Service: Done By, M.Manoj KlementRajaRamОценок пока нет
- Oracle QsДокумент6 страницOracle QshellopavaniОценок пока нет
- Lab9 Troubleshooting Snowpipe AWSДокумент2 страницыLab9 Troubleshooting Snowpipe AWSvr.sf99Оценок пока нет
- Create Three Node Replication SetДокумент9 страницCreate Three Node Replication SetRavindra MalwalОценок пока нет
- Golden Gate - Online Change Synchronization With The Initial Data LoadДокумент5 страницGolden Gate - Online Change Synchronization With The Initial Data LoadPujan Roy100% (1)
- Oracle Performance TuningДокумент9 страницOracle Performance TuningMSG1803Оценок пока нет
- Creating Single Instance Physical Standby For A RAC Primary - 12cДокумент14 страницCreating Single Instance Physical Standby For A RAC Primary - 12cKiranОценок пока нет
- Oracle DBAДокумент25 страницOracle DBAAvinash SinghОценок пока нет
- SqoopTutorial Ver 2.0Документ51 страницаSqoopTutorial Ver 2.0bujjijulyОценок пока нет
- PGSQL CheatSheet Mysql2psqlДокумент7 страницPGSQL CheatSheet Mysql2psqlkishore_m_kОценок пока нет
- ASM Interview QuestionsДокумент44 страницыASM Interview QuestionsKumar KОценок пока нет
- Apache Plug inДокумент25 страницApache Plug inKumar SwamyОценок пока нет
- DBA's Guide To Physical Dataguard IIДокумент43 страницыDBA's Guide To Physical Dataguard IIsantoshganjure@bluebottle.comОценок пока нет
- Select PDBДокумент9 страницSelect PDBoverloadОценок пока нет
- AWR RPT Reading PDFДокумент64 страницыAWR RPT Reading PDFharsshОценок пока нет
- RefreshДокумент5 страницRefreshKrishna GhantaОценок пока нет
- LVM Resizing Guide - Howto Resize Logical Volumes in Linux - LVM, Resizing, Lvresize, Vgdisplay, LvdisplayДокумент7 страницLVM Resizing Guide - Howto Resize Logical Volumes in Linux - LVM, Resizing, Lvresize, Vgdisplay, LvdisplayCrocodilicОценок пока нет
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesОт EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesОценок пока нет
- 10 Meter Air Rifle Target A4Документ1 страница10 Meter Air Rifle Target A4leonard1971Оценок пока нет
- Some Error #2Документ1 страницаSome Error #2leonard1971Оценок пока нет
- Senzori U Motoru Automobil1Документ24 страницыSenzori U Motoru Automobil1leonard1971Оценок пока нет
- Python3 Tutorial PDFДокумент512 страницPython3 Tutorial PDFAriane AquinoОценок пока нет
- Precision t3610 Workstation Manual enДокумент65 страницPrecision t3610 Workstation Manual enleonard1971Оценок пока нет
- Dell Precision T3610 UEFI Secure BIOS ProblemiДокумент50 страницDell Precision T3610 UEFI Secure BIOS Problemileonard1971Оценок пока нет
- 9 Must Decisions in Desktop Application Development For WindowsДокумент16 страниц9 Must Decisions in Desktop Application Development For Windowsleonard1971Оценок пока нет
- HHGHJ KДокумент470 страницHHGHJ Kleonard1971Оценок пока нет
- I Havent Shut Down My Computer in Six Months It Is Always Either On or in Sleep Mode Does It Reduce The Lifespan of ComputerДокумент5 страницI Havent Shut Down My Computer in Six Months It Is Always Either On or in Sleep Mode Does It Reduce The Lifespan of Computerleonard1971Оценок пока нет
- Is Functional Programming Moving Away From Linked ListsДокумент2 страницыIs Functional Programming Moving Away From Linked Listsleonard1971Оценок пока нет
- Landauer's Principle - WikipediaДокумент4 страницыLandauer's Principle - Wikipedialeonard1971Оценок пока нет
- Digital Image Watermarking Theoretical and Computational Advances 2019Документ175 страницDigital Image Watermarking Theoretical and Computational Advances 2019leonard1971100% (1)
- Dell Precision T3610 Spec SheetДокумент2 страницыDell Precision T3610 Spec SheetKamineni JagathОценок пока нет
- 9 Must Decisions in Desktop Application Development For WindowsДокумент16 страниц9 Must Decisions in Desktop Application Development For Windowsleonard1971Оценок пока нет
- Simbad-Rc: Remotely Controlled Naval Mistral LauncherДокумент2 страницыSimbad-Rc: Remotely Controlled Naval Mistral Launcherleonard1971Оценок пока нет
- XCBCXДокумент21 страницаXCBCXleonard1971Оценок пока нет
- Swaroop - CH - A Byte of Python 115Документ124 страницыSwaroop - CH - A Byte of Python 115jisna687Оценок пока нет
- What Made The T 54/55 The Best Tank of Its Time?Документ11 страницWhat Made The T 54/55 The Best Tank of Its Time?leonard1971Оценок пока нет
- Business Process Modeling-A Comparative Analysis : Ut - Edu.au M.indulska@business - Uq.edu - AuДокумент32 страницыBusiness Process Modeling-A Comparative Analysis : Ut - Edu.au M.indulska@business - Uq.edu - Auleonard1971Оценок пока нет
- How To Calculate Force of ImpactДокумент2 страницыHow To Calculate Force of Impactleonard1971Оценок пока нет
- DF GFG DFGДокумент14 страницDF GFG DFGleonard1971Оценок пока нет
- Business Process Modeling Languages: A Comparative FrameworkДокумент10 страницBusiness Process Modeling Languages: A Comparative Frameworkleonard1971Оценок пока нет
- On The Use of Petri Nets For Business Process ModelingДокумент7 страницOn The Use of Petri Nets For Business Process Modelingleonard1971Оценок пока нет
- Domain Specific Languages For Business Process Management: A Case StudyДокумент7 страницDomain Specific Languages For Business Process Management: A Case Studyleonard1971Оценок пока нет
- Business Process Modelling Based On Petri NetsДокумент5 страницBusiness Process Modelling Based On Petri Netsleonard1971Оценок пока нет
- BUIS AcceptedmanuscriptДокумент36 страницBUIS Acceptedmanuscriptleonard1971Оценок пока нет
- Beginners Guide To Business Process Modeling and NotationДокумент27 страницBeginners Guide To Business Process Modeling and Notationleonard1971Оценок пока нет
- How To Avoid The 10 Biggest Mistakes in Process ModelingДокумент5 страницHow To Avoid The 10 Biggest Mistakes in Process Modelingleonard1971Оценок пока нет
- Pace, ART 102, Week 6, Etruscan, Roman Arch. & SculpДокумент36 страницPace, ART 102, Week 6, Etruscan, Roman Arch. & SculpJason ByrdОценок пока нет
- Acidity (As Acetic Acid) On Undenatured and Denatured EthanolДокумент10 страницAcidity (As Acetic Acid) On Undenatured and Denatured EthanolVinh NguyenОценок пока нет
- 07 Lejano vs. People (95 PAGES!)Документ95 страниц07 Lejano vs. People (95 PAGES!)noonalawОценок пока нет
- 8 Powerful Methods People Use To Bounce Back From FailureДокумент7 страниц8 Powerful Methods People Use To Bounce Back From FailureGrego CentillasОценок пока нет
- Amor Vs FlorentinoДокумент17 страницAmor Vs FlorentinoJessica BernardoОценок пока нет
- Ubi Jus Ibi RemediumДокумент9 страницUbi Jus Ibi RemediumUtkarsh JaniОценок пока нет
- Final Paper IN MAJOR 14 EL 116 Life and Death: Fear Reflected in John Green's The Fault in Our StarsДокумент12 страницFinal Paper IN MAJOR 14 EL 116 Life and Death: Fear Reflected in John Green's The Fault in Our StarsMary Rose FragaОценок пока нет
- Eugène Burnouf: Legends of Indian Buddhism (1911)Документ136 страницEugène Burnouf: Legends of Indian Buddhism (1911)Levente Bakos100% (1)
- Mathematicaleconomics PDFДокумент84 страницыMathematicaleconomics PDFSayyid JifriОценок пока нет
- J of Cosmetic Dermatology - 2019 - Zhang - A Cream of Herbal Mixture To Improve MelasmaДокумент8 страницJ of Cosmetic Dermatology - 2019 - Zhang - A Cream of Herbal Mixture To Improve Melasmaemily emiОценок пока нет
- Oracle QuestДокумент521 страницаOracle Questprasanna ghareОценок пока нет
- Endocrine System Unit ExamДокумент3 страницыEndocrine System Unit ExamCHRISTINE JULIANEОценок пока нет
- I Wonder Lonely As A Cloud by W. Words WorthДокумент6 страницI Wonder Lonely As A Cloud by W. Words WorthGreen Bergen100% (1)
- Parwati DeviДокумент25 страницParwati DevikvntpcsktprОценок пока нет
- (Kre?Imir Petkovi?) Discourses On Violence andДокумент610 страниц(Kre?Imir Petkovi?) Discourses On Violence andGelazul100% (1)
- Engineering Road Note 9 - May 2012 - Uploaded To Main Roads Web SiteДокумент52 страницыEngineering Road Note 9 - May 2012 - Uploaded To Main Roads Web SiteRahma SariОценок пока нет
- TOEIC® Practice OnlineДокумент8 страницTOEIC® Practice OnlineCarlos Luis GonzalezОценок пока нет
- Managing Ambiguity and ChangeДокумент7 страницManaging Ambiguity and ChangeTracey FeboОценок пока нет
- JURDING (Corticosteroids Therapy in Combination With Antibiotics For Erysipelas)Документ21 страницаJURDING (Corticosteroids Therapy in Combination With Antibiotics For Erysipelas)Alif Putri YustikaОценок пока нет
- Financial Crisis Among UTHM StudentsДокумент7 страницFinancial Crisis Among UTHM StudentsPravin PeriasamyОценок пока нет
- Week9 Phylum NemathelminthesДокумент26 страницWeek9 Phylum NemathelminthesCzerinne Angela Justinne AlarillaОценок пока нет
- Appellees Brief CIVILДокумент7 страницAppellees Brief CIVILBenBulacОценок пока нет
- GST 101 Exam Past QuestionsДокумент6 страницGST 101 Exam Past QuestionsBenjamin Favour100% (2)
- Number SystemsДокумент165 страницNumber SystemsapamanОценок пока нет
- WHO CDS HIV 19.8 EngДокумент24 страницыWHO CDS HIV 19.8 EngMaykel MontesОценок пока нет
- 50 p7 Kids AvikdeДокумент2 страницы50 p7 Kids AvikdebankansОценок пока нет
- Gothic Revival ArchitectureДокумент19 страницGothic Revival ArchitectureAlexandra Maria NeaguОценок пока нет