Вам также может понравиться
- Learning Probability Distributions Generated by Finite-State MachinesДокумент53 страницыLearning Probability Distributions Generated by Finite-State MachinesKevin MondragonОценок пока нет
- A Lower Bound For Learning Distributions Generated by Probabilistic AutomataДокумент15 страницA Lower Bound For Learning Distributions Generated by Probabilistic AutomataKevin MondragonОценок пока нет
- I Cgi 08 ProceedingsДокумент14 страницI Cgi 08 ProceedingsKevin MondragonОценок пока нет
- Hardness of Approximating The Minimum Distance of A Linear CodeДокумент1 страницаHardness of Approximating The Minimum Distance of A Linear CodeasdasddsaОценок пока нет
- User-Friendly Clustering of Mixed-Type Data in RДокумент9 страницUser-Friendly Clustering of Mixed-Type Data in RJulián BuitragoОценок пока нет
- MMD GAN: Towards Deeper Understanding of Moment Matching NetworkДокумент17 страницMMD GAN: Towards Deeper Understanding of Moment Matching NetworkCarlos YeboahОценок пока нет
- Kullback-Leibler Divergence Estimation of Continuous DistributionsДокумент5 страницKullback-Leibler Divergence Estimation of Continuous DistributionsMilkha SinghОценок пока нет
- Discrete Optimisation Felzenszwalb-Huttenlocher2006 Article EfficientBeliefPropagaДокумент14 страницDiscrete Optimisation Felzenszwalb-Huttenlocher2006 Article EfficientBeliefPropagaSolveig ThrunОценок пока нет
- Markov Chain Monte Carlo and Variational Inference: Bridging The GapДокумент9 страницMarkov Chain Monte Carlo and Variational Inference: Bridging The GapnothardОценок пока нет
- Adaptive Gradient Methods With Dynamic Bound of Learning RateДокумент21 страницаAdaptive Gradient Methods With Dynamic Bound of Learning RateMuhammad JunaidОценок пока нет
- Bayesian Dark Knowledge: N N I 1 I I N I I N I 1 I D I N NДокумент9 страницBayesian Dark Knowledge: N N I 1 I I N I I N I 1 I D I N Nmehdaoui fatima ezzahraОценок пока нет
- University of Edinburgh College of Science and Engineering School of InformaticsДокумент5 страницUniversity of Edinburgh College of Science and Engineering School of InformaticsfusionОценок пока нет
- Alternative Probabilistic Models: Probability TheoryДокумент37 страницAlternative Probabilistic Models: Probability TheoryVishnuDhanabalan100% (1)
- AciidsДокумент16 страницAciidsTuấn Lưu MinhОценок пока нет
- Power Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolДокумент6 страницPower Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolKhalid AlHashemiОценок пока нет
- TR15 013Документ19 страницTR15 013K EОценок пока нет
- On The Overestimation of Widely Applicable Bayesian Information CriterionДокумент12 страницOn The Overestimation of Widely Applicable Bayesian Information CriterionGaston GBОценок пока нет
- Power Load Forecasting Based On Multi-Task Gaussian ProcessДокумент6 страницPower Load Forecasting Based On Multi-Task Gaussian ProcessKhalid AlHashemiОценок пока нет
- Learning PDFA With Asynchronous Transitions: 1 MotivationДокумент4 страницыLearning PDFA With Asynchronous Transitions: 1 MotivationKevin MondragonОценок пока нет
- ICANN19 Final ID 416Документ12 страницICANN19 Final ID 416Nico CavalcantiОценок пока нет
- A Piecewise Aggregate Approximation Lower-Bound Estimate For Posteriorgram-Based Dynamic Time WarpingДокумент4 страницыA Piecewise Aggregate Approximation Lower-Bound Estimate For Posteriorgram-Based Dynamic Time WarpingguminyulОценок пока нет
- A Brief Overview of Bayesian Model Averaging: Chris Sroka, Juhee Lee, Prasenjit Kapat, Xiuyun ZhangДокумент70 страницA Brief Overview of Bayesian Model Averaging: Chris Sroka, Juhee Lee, Prasenjit Kapat, Xiuyun ZhangmuralidharanОценок пока нет
- Opt AmsgradДокумент16 страницOpt Amsgradnada montasser gaberОценок пока нет
- A Review Constructing Priors That Penalizes The Complexity of Gaussian Random Fields - Fuglstad Et AlДокумент8 страницA Review Constructing Priors That Penalizes The Complexity of Gaussian Random Fields - Fuglstad Et AlfigueirapereiramarioОценок пока нет
- NotesДокумент9 страницNoteshu jackОценок пока нет
- SYSID2009 Saint MaloДокумент6 страницSYSID2009 Saint MaloMarcioОценок пока нет
- WWW Cs MQ Edu au252F25257Eigor252FEC DSA Pdf252fnguyen00insecurityДокумент16 страницWWW Cs MQ Edu au252F25257Eigor252FEC DSA Pdf252fnguyen00insecurityasena visionОценок пока нет
- Existence and Uniqueness Results For Fractional PДокумент15 страницExistence and Uniqueness Results For Fractional PBoutiara AbdellatifОценок пока нет
- Determining Soil Property Values from SPT TestsДокумент8 страницDetermining Soil Property Values from SPT TestsSeraj S. JebrilОценок пока нет
- Particlefilter EqualizationДокумент4 страницыParticlefilter Equalizationnguyentai325Оценок пока нет
- Bayesian Online Changepoint DetectionДокумент7 страницBayesian Online Changepoint DetectionChikh YassineОценок пока нет
- Matteo Scalperf 2017Документ31 страницаMatteo Scalperf 2017ceccarellomОценок пока нет
- Multiple Object Tracking Using Variational InferenceДокумент6 страницMultiple Object Tracking Using Variational InferenceArthas8890Оценок пока нет
- 12 2 4 PDFДокумент4 страницы12 2 4 PDFDyanaHottest-GirlDavidsonОценок пока нет
- Lez 12Документ12 страницLez 12Dino Dwi JayantoОценок пока нет
- Naive Bayes & Introduction To GaussiansДокумент10 страницNaive Bayes & Introduction To GaussiansMafer ReveloОценок пока нет
- Quantization of Discrete Probability Distributions: Qualcomm Inc. 5775 Morehouse Drive, San Diego, CA 92121Документ6 страницQuantization of Discrete Probability Distributions: Qualcomm Inc. 5775 Morehouse Drive, San Diego, CA 92121Anonymous BWVVQpxОценок пока нет
- The Insecurity of Nyberg-Rueppel and Other DSA-Like Signature Schemes With Partially Known NoncesДокумент17 страницThe Insecurity of Nyberg-Rueppel and Other DSA-Like Signature Schemes With Partially Known Nonces2013scribd001Оценок пока нет
- 16 Aap1257Документ43 страницы16 Aap1257Guifré Sánchez SerraОценок пока нет
- Graphical Models OverviewДокумент135 страницGraphical Models OverviewjoseluismbОценок пока нет
- Petri Nets With Marking-Dependent Arc Cardinality: Properties and AnalysisДокумент20 страницPetri Nets With Marking-Dependent Arc Cardinality: Properties and AnalysisssfofoОценок пока нет
- Limitations of Markov Chain Monte Carlo Algorithms For Bayesian Inference of PhylogenyДокумент20 страницLimitations of Markov Chain Monte Carlo Algorithms For Bayesian Inference of Phylogenysimran agrawalОценок пока нет
- 4.power Mumford NicholsДокумент34 страницы4.power Mumford NicholsPalraj KОценок пока нет
- Quantized Compressive Learning 2019Документ11 страницQuantized Compressive Learning 2019Jacob EveristОценок пока нет
- A Majorcan Algebrist in King RNA's CourtДокумент41 страницаA Majorcan Algebrist in King RNA's CourtCesc RosselloОценок пока нет
- Presentation NishantДокумент42 страницыPresentation NishantNishant PandaОценок пока нет
- Multi Target Tracking of Ground TargetsДокумент7 страницMulti Target Tracking of Ground TargetsAlexandru MatasaruОценок пока нет
- Exploration in Contextual Bandits: Reedy ReedyДокумент16 страницExploration in Contextual Bandits: Reedy ReedyNo12n533Оценок пока нет
- Small Sample Size Performance of The Energy DetectorДокумент4 страницыSmall Sample Size Performance of The Energy Detectorsuchi87Оценок пока нет
- Pattern Classification: All Materials in These Slides Were Taken FromДокумент18 страницPattern Classification: All Materials in These Slides Were Taken FromavivroОценок пока нет
- KMeansPP SodaДокумент9 страницKMeansPP Sodaalanpicard2303Оценок пока нет
- 5 On Diagonal Approximations ToДокумент14 страниц5 On Diagonal Approximations ToAKİF BARBAROS DİKMENОценок пока нет
- Proposal of An Intelligent Speech Recognition System: November 2012Документ7 страницProposal of An Intelligent Speech Recognition System: November 2012Beenish YousafОценок пока нет
- Reduction Using Semi Correlation FactorДокумент10 страницReduction Using Semi Correlation FactorTamer MedhatОценок пока нет
- On Zadeh's Compositional Rule of Inference: Robert Full Er Hans-J Urgen ZimmermannДокумент6 страницOn Zadeh's Compositional Rule of Inference: Robert Full Er Hans-J Urgen ZimmermannSamir PandaОценок пока нет
- Push Down Automata (PDA) : Non-Deterministic PDA Deterministic PDAДокумент20 страницPush Down Automata (PDA) : Non-Deterministic PDA Deterministic PDAMiku21Оценок пока нет
- Fast Solutions For DNA Code Words Test: January 2006Документ14 страницFast Solutions For DNA Code Words Test: January 2006Diego AlmeidaОценок пока нет
- A Family of Projective Two-Weight Linear CodesДокумент9 страницA Family of Projective Two-Weight Linear CodesTudor MicuОценок пока нет
- Learning probability distributions from finite-state machinesДокумент29 страницLearning probability distributions from finite-state machinesKevin MondragonОценок пока нет
- Size-Depth Tradeoffs For Boolean Formulae: Maria Luisa Bonet Samuel R. BussДокумент9 страницSize-Depth Tradeoffs For Boolean Formulae: Maria Luisa Bonet Samuel R. BussKevin MondragonОценок пока нет
- 011-Math 111 Graphical Problem FlowchartДокумент1 страница011-Math 111 Graphical Problem FlowchartKevin MondragonОценок пока нет
- TvuДокумент1 страницаTvuKevin MondragonОценок пока нет
- Mean-Payoff Games and The Max-Atom ProblemДокумент10 страницMean-Payoff Games and The Max-Atom ProblemKevin MondragonОценок пока нет
- 009 ExtraProblem1Документ1 страница009 ExtraProblem1Kevin MondragonОценок пока нет
- Equivalence-Query Algorithms To PAC AlgorithmsДокумент8 страницEquivalence-Query Algorithms To PAC AlgorithmsKevin MondragonОценок пока нет
- Miri Seminar 2016Документ2 страницыMiri Seminar 2016Kevin MondragonОценок пока нет
- ReviewДокумент9 страницReviewKevin MondragonОценок пока нет
- Automatic Detection and Banning of Content Stealing Bots For E-CommerceДокумент2 страницыAutomatic Detection and Banning of Content Stealing Bots For E-CommerceKevin MondragonОценок пока нет
- Notions of Average-Case Complexity For Random 3-SATДокумент5 страницNotions of Average-Case Complexity For Random 3-SATKevin MondragonОценок пока нет
- Salambominer: A Biomedical Literature Mining Tool For Inferring The Genetics of Complex DiseasesДокумент4 страницыSalambominer: A Biomedical Literature Mining Tool For Inferring The Genetics of Complex DiseasesKevin MondragonОценок пока нет
- Speed and Conversion Challenge ProblemДокумент1 страницаSpeed and Conversion Challenge ProblemKevin MondragonОценок пока нет
- Notions of Average-Case Complexity For Random 3-SATДокумент5 страницNotions of Average-Case Complexity For Random 3-SATKevin MondragonОценок пока нет
- Adaptive XML Tree Mining On Evolving Data Streams: Presented at ILP-MLG-SRL, Leuven, Belgium, 2009Документ3 страницыAdaptive XML Tree Mining On Evolving Data Streams: Presented at ILP-MLG-SRL, Leuven, Belgium, 2009Kevin MondragonОценок пока нет
- Salambominer: A Biomedical Literature Mining Tool For Inferring The Genetics of Complex DiseasesДокумент4 страницыSalambominer: A Biomedical Literature Mining Tool For Inferring The Genetics of Complex DiseasesKevin MondragonОценок пока нет
- 014-9 3mixingДокумент3 страницы014-9 3mixingKevin MondragonОценок пока нет
- 004 As02Документ1 страница004 As02Kevin MondragonОценок пока нет
- 012 AreaДокумент2 страницы012 AreaKevin MondragonОценок пока нет
- 006 Day1motionДокумент1 страница006 Day1motionKevin MondragonОценок пока нет
- 007 FinalReviewДокумент1 страница007 FinalReviewKevin MondragonОценок пока нет
- 010 IntSymbReviewДокумент1 страница010 IntSymbReviewKevin MondragonОценок пока нет
- 008 4 9BasicAntiderivativesДокумент1 страница008 4 9BasicAntiderivativesKevin MondragonОценок пока нет
- 005-Summer Math SyllabusДокумент4 страницы005-Summer Math SyllabusKevin MondragonОценок пока нет
- 002-hw5 Plot2Документ1 страница002-hw5 Plot2Kevin MondragonОценок пока нет
- 003-Guidelines For CMPДокумент1 страница003-Guidelines For CMPKevin MondragonОценок пока нет
- Assignment 3 (Due Wednesday at The Beginning of Class)Документ1 страницаAssignment 3 (Due Wednesday at The Beginning of Class)Kevin MondragonОценок пока нет
- Ielts InformationДокумент8 страницIelts InformationJoy BaruaОценок пока нет
- Vocabulary List PDFДокумент42 страницыVocabulary List PDFGatoneneОценок пока нет
- A2 Ket Vocabulary List PDFДокумент33 страницыA2 Ket Vocabulary List PDFAdriana BialisОценок пока нет
- Iiscw 10Документ10 страницIiscw 10Kevin MondragonОценок пока нет
- Recursion: Data Structures and Algorithms in Java 1/25Документ25 страницRecursion: Data Structures and Algorithms in Java 1/25Tryer0% (1)
- Absolute Difference of Square Sum and Sum Mean Prime Labeling of Some Snake GraphsДокумент3 страницыAbsolute Difference of Square Sum and Sum Mean Prime Labeling of Some Snake GraphsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Louis Braiotta Jr. - The Audit Committee HandbookДокумент6 страницLouis Braiotta Jr. - The Audit Committee HandbookShaneОценок пока нет
- BBDNIIT Digital Electronics Previous Year QuestionsДокумент5 страницBBDNIIT Digital Electronics Previous Year QuestionsShubhi AgarwalОценок пока нет
- Signal Flow GraphДокумент29 страницSignal Flow GraphAhsan MoinОценок пока нет
- Awesome Advanced BooksДокумент10 страницAwesome Advanced BooksSammyJayОценок пока нет
- GROUP 2015 BASIC ADVANCE ALGEBRAДокумент8 страницGROUP 2015 BASIC ADVANCE ALGEBRAMeliza AdvinculaОценок пока нет
- 2014 TF JamesKraft Intro To NumberTheory PDFДокумент2 страницы2014 TF JamesKraft Intro To NumberTheory PDFDannyОценок пока нет
- IGMO 2023 Round 1 PaperДокумент6 страницIGMO 2023 Round 1 PaperGabriel GohОценок пока нет
- Comilla University: Department of Computer Science & Engineering Presentation On: Data StructureДокумент23 страницыComilla University: Department of Computer Science & Engineering Presentation On: Data StructureEaib Aminul IslamОценок пока нет
- Revision Questions Yr7Документ10 страницRevision Questions Yr7vanithasarasu532Оценок пока нет
- Implementation of Stack Using ArrayДокумент4 страницыImplementation of Stack Using ArrayMeghna Raj CОценок пока нет
- Scheme of Study For Bachelor of Science in Computer Science Bs (CS)Документ20 страницScheme of Study For Bachelor of Science in Computer Science Bs (CS)Nouman ArshadОценок пока нет
- Tricky QuestionsДокумент5 страницTricky QuestionsSajid AzfarОценок пока нет
- C Programming Examples for BeginnersДокумент3 страницыC Programming Examples for Beginnersbishwash neupaneОценок пока нет
- Natural and Whole Numbers. Assignment-1Документ2 страницыNatural and Whole Numbers. Assignment-1RichaBhardwajBhatia100% (2)
- Introduction To Algorithms Md. Asif Bin KhaledДокумент26 страницIntroduction To Algorithms Md. Asif Bin KhaledSharmin Islam ShroddhaОценок пока нет
- Mthematical Library MethodsДокумент30 страницMthematical Library MethodsAshwini KSОценок пока нет
- OpMan LPДокумент11 страницOpMan LPprincess_camarilloОценок пока нет
- Rmo Question PaperДокумент2 страницыRmo Question Papermsinghal_me100% (1)
- RF Review Center Weekly Exam 1Документ2 страницыRF Review Center Weekly Exam 1Hary KrizОценок пока нет
- Exercises of Design & AnalysisДокумент7 страницExercises of Design & AnalysisAndyTrinh100% (1)
- Generalized addition chains for arbitrary fixed gДокумент13 страницGeneralized addition chains for arbitrary fixed gIan G. WalkerОценок пока нет
- Computational Complexity: CSD-202 Data Structure and AlgorithmsДокумент29 страницComputational Complexity: CSD-202 Data Structure and AlgorithmsMaDDYОценок пока нет
- ERA2010 Conference ListДокумент136 страницERA2010 Conference Listasif1253Оценок пока нет
- Ada PracticalДокумент59 страницAda PracticalREEYA50% (2)
- Lab 3Документ2 страницыLab 3Ashish KarkiОценок пока нет
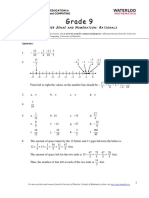
- Answers:: Umber Ense and Umeration AtionalsДокумент4 страницыAnswers:: Umber Ense and Umeration AtionalsAryo WibisonoОценок пока нет
- DAA Unit Wise Importtant QuestionsДокумент2 страницыDAA Unit Wise Importtant QuestionsAditya Krishna100% (4)
- CH-1 MCQs Term - 1 Class X MathsДокумент9 страницCH-1 MCQs Term - 1 Class X MathsjjjdklcfjsdcfОценок пока нет