Вам также может понравиться
- Calculus: I. Limit and Continuity of FunctionsДокумент25 страницCalculus: I. Limit and Continuity of FunctionsALOK SHARMAОценок пока нет
- Summary Week 2Документ17 страницSummary Week 253199Оценок пока нет
- Experimental Methods: Department of Applied MechanicsДокумент8 страницExperimental Methods: Department of Applied MechanicsANSHU MISHRAОценок пока нет
- Experimental Methods: Department of Applied MechanicsДокумент12 страницExperimental Methods: Department of Applied MechanicsANSHU MISHRAОценок пока нет
- Advanced Topic3Документ111 страницAdvanced Topic3Huyền 可爱的公主 ĐỗОценок пока нет
- Econ 307: Two-Sample Inference and Chi-Square Test: Pasita Chaijaroen Pchaijaroen@wm - EduДокумент26 страницEcon 307: Two-Sample Inference and Chi-Square Test: Pasita Chaijaroen Pchaijaroen@wm - EduPaul LeeОценок пока нет
- Linear RegressionДокумент26 страницLinear RegressionPulkitОценок пока нет
- Rules 107QUAДокумент5 страницRules 107QUAx7kkhp45m7Оценок пока нет
- 8 HeteroscedasticityДокумент24 страницы8 HeteroscedasticityDavid AyalaОценок пока нет
- Minimum Variance Unbiased Estimation: ExampleДокумент4 страницыMinimum Variance Unbiased Estimation: ExampleÖmer Faruk DemirОценок пока нет
- Bilinear Transformation: Prof.G.K.Rajini Select, Vit University VelloreДокумент14 страницBilinear Transformation: Prof.G.K.Rajini Select, Vit University VelloreKrishna SrivathsaОценок пока нет
- AE 248: AI and Data Science: Prabhu Ramachandran 2024-03-01Документ8 страницAE 248: AI and Data Science: Prabhu Ramachandran 2024-03-01prasan0311dasОценок пока нет
- Statistics and ProbabilityДокумент6 страницStatistics and ProbabilityjieseljoyceoliliОценок пока нет
- Plackett BurmanДокумент46 страницPlackett BurmanalexОценок пока нет
- AB1202 Statistics and AnalysisДокумент16 страницAB1202 Statistics and AnalysisxtheleОценок пока нет
- AE 248: AI and Data Science: Prabhu Ramachandran 2024-03-01Документ3 страницыAE 248: AI and Data Science: Prabhu Ramachandran 2024-03-01prasan0311dasОценок пока нет
- Presentación - T71 - Diseño y Cálculo de Estructuras Metálicas I - CEДокумент66 страницPresentación - T71 - Diseño y Cálculo de Estructuras Metálicas I - CEKaren JimenezОценок пока нет
- Applied Statistics II-SLRДокумент23 страницыApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Calculus 5 - Derivatives ApplicationДокумент9 страницCalculus 5 - Derivatives ApplicationsaradsamundrachОценок пока нет
- CH4404 Lecture 07 NumericalIntegrationДокумент13 страницCH4404 Lecture 07 NumericalIntegrationRRОценок пока нет
- Module02 ANOVAДокумент28 страницModule02 ANOVAasdfОценок пока нет
- 课件1Документ17 страниц课件1Alex WangОценок пока нет
- 10 - Acceleration and Vibration Measurement - SensorsДокумент28 страниц10 - Acceleration and Vibration Measurement - SensorsKARTHIK S SОценок пока нет
- Stat2 2023 Syllabus B v1.0 Weeks 5-6-7Документ41 страницаStat2 2023 Syllabus B v1.0 Weeks 5-6-7Andrei PopaОценок пока нет
- EECM3724 Unit 9 ch14 Slides 2023Документ57 страницEECM3724 Unit 9 ch14 Slides 2023Lungile SitholeОценок пока нет
- Lecture 3-4 (With Ans)Документ20 страницLecture 3-4 (With Ans)劉泳Оценок пока нет
- Class32.04.03.2024 WNДокумент26 страницClass32.04.03.2024 WNEslam UsamaОценок пока нет
- 02 Hydro2023 ShareДокумент32 страницы02 Hydro2023 Sharedimas kukuhОценок пока нет
- Week 2 Slides White BackgroundДокумент93 страницыWeek 2 Slides White Backgroundhussienboss99Оценок пока нет
- Lesson 2 Statistical InferenceДокумент45 страницLesson 2 Statistical InferencemaartenwildersОценок пока нет
- RegressionДокумент17 страницRegressionRenhe SONGОценок пока нет
- AB1202 Lect 05Документ17 страницAB1202 Lect 05xtheleОценок пока нет
- Z TransformДокумент37 страницZ Transformعلي كامل الاسديОценок пока нет
- Super Regenerative ReceiversДокумент21 страницаSuper Regenerative ReceiversAyoub KamalОценок пока нет
- Convolutional Neural NetworksДокумент46 страницConvolutional Neural NetworksLamis Ahmad100% (1)
- Sample Correlation Coefficient: X Value and Is Called The Simple Regression EquationДокумент1 страницаSample Correlation Coefficient: X Value and Is Called The Simple Regression EquationaaxdhpОценок пока нет
- Formulas SheetДокумент2 страницыFormulas Sheetsaleemlaiba17Оценок пока нет
- L4 Random Signals and Noise PDFДокумент55 страницL4 Random Signals and Noise PDFcriscab12345Оценок пока нет
- 5-CL305-More Than One Indpt VariablesДокумент20 страниц5-CL305-More Than One Indpt Variablesshivurkolli07Оценок пока нет
- Inverters: Eng. Ibrahim Mahmoud IbrahimДокумент9 страницInverters: Eng. Ibrahim Mahmoud IbrahimMahmoud A. AboulhasanОценок пока нет
- First Order Differential EquationДокумент17 страницFirst Order Differential EquationJENIE BABE MANIAGOОценок пока нет
- Calculate Flow Rate Through Control Valve For Incompressible Fluids When There Is No Flow MeterДокумент26 страницCalculate Flow Rate Through Control Valve For Incompressible Fluids When There Is No Flow MeterHadi VeyseОценок пока нет
- SM025 Overview (Chapter 06 To 10)Документ26 страницSM025 Overview (Chapter 06 To 10)William Franklyn Miller WilliamОценок пока нет
- Chapter 3. Linear RegressionДокумент41 страницаChapter 3. Linear RegressionNguyễn Quang TrườngОценок пока нет
- Design of Sections For Flexural Part 1Документ9 страницDesign of Sections For Flexural Part 1ismailwajeh09Оценок пока нет
- Quality MidsemДокумент179 страницQuality MidsemHEMANTH KAJULURIОценок пока нет
- Lecture 4Документ22 страницыLecture 4khaddamoazОценок пока нет
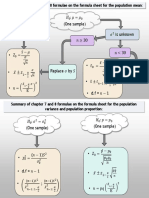
- Summary of Formulae For Chapter 7 and 8Документ2 страницыSummary of Formulae For Chapter 7 and 8Darian ChettyОценок пока нет
- AP ECON 2500 Session 2Документ22 страницыAP ECON 2500 Session 2Thuỳ DungОценок пока нет
- Continuous Probability Distribution: Business Statistics Prepared By: Ikram-E-KhudaДокумент31 страницаContinuous Probability Distribution: Business Statistics Prepared By: Ikram-E-KhudaAsharОценок пока нет
- Data Science Formula - Very ImpДокумент6 страницData Science Formula - Very Impcoloringcraft318Оценок пока нет
- Statistical Inference of Two Samples InkДокумент22 страницыStatistical Inference of Two Samples InkNishikata ManipolОценок пока нет
- Simple Linear RegressionclassroomДокумент37 страницSimple Linear RegressionclassroomNishikata ManipolОценок пока нет
- GCSE Maths Revision: Cheeky Revision ShortcutsОт EverandGCSE Maths Revision: Cheeky Revision ShortcutsРейтинг: 3.5 из 5 звезд3.5/5 (2)
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsОт EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsРейтинг: 5 из 5 звезд5/5 (1)
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankОт EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankОценок пока нет
- Roaming SettingsДокумент7 страницRoaming SettingsxtheleОценок пока нет
- BE2601 Course Assessments S1 AY 2019-20 (SOFV)Документ24 страницыBE2601 Course Assessments S1 AY 2019-20 (SOFV)xtheleОценок пока нет
- Rhetoric and Persuasion: Effectiveness Is EnhancedДокумент2 страницыRhetoric and Persuasion: Effectiveness Is EnhancedxtheleОценок пока нет
- Travel Insurance Policy ContractДокумент49 страницTravel Insurance Policy ContractxtheleОценок пока нет
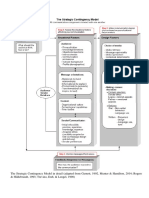
- The Strategic Contingency Model PDFДокумент1 страницаThe Strategic Contingency Model PDFxtheleОценок пока нет
- Class11-Revenue MGT - Before ClassДокумент37 страницClass11-Revenue MGT - Before ClassxtheleОценок пока нет
- WK 11-Tut 10 - Model Building ScriptsДокумент11 страницWK 11-Tut 10 - Model Building ScriptsxtheleОценок пока нет
- AB1202 Statistics and AnalysisДокумент18 страницAB1202 Statistics and AnalysisxtheleОценок пока нет
- Consent Form (Interview) Evidence Based Reflective Learning ReportДокумент2 страницыConsent Form (Interview) Evidence Based Reflective Learning ReportxtheleОценок пока нет
- AB1202 Statistics and Analysis: Model BuildingДокумент20 страницAB1202 Statistics and Analysis: Model BuildingxtheleОценок пока нет
- AB1202 Statistics and AnalysisДокумент16 страницAB1202 Statistics and AnalysisxtheleОценок пока нет
- AB1202 Lect 05Документ17 страницAB1202 Lect 05xtheleОценок пока нет
- AB1202 Statistics and Analysis: Time Series Predictive ModelsДокумент15 страницAB1202 Statistics and Analysis: Time Series Predictive ModelsxtheleОценок пока нет
- AB1202 Lect 06Документ14 страницAB1202 Lect 06xtheleОценок пока нет
- AB1202 Statistics and Analysis: Sampling Distributions and Confidence IntervalsДокумент15 страницAB1202 Statistics and Analysis: Sampling Distributions and Confidence IntervalsxtheleОценок пока нет
- Tourism & Hospitality Case Challenge 2017: Semi-Finals Case QuestionДокумент6 страницTourism & Hospitality Case Challenge 2017: Semi-Finals Case QuestionxtheleОценок пока нет
- Tourism & Hospitality Case Challenge 2017: Preliminary Round Case QuestionДокумент5 страницTourism & Hospitality Case Challenge 2017: Preliminary Round Case QuestionxtheleОценок пока нет
- AB1202 Statistics and Analysis: (Part 1 of 2) Concepts of ProbabilityДокумент17 страницAB1202 Statistics and Analysis: (Part 1 of 2) Concepts of ProbabilityxtheleОценок пока нет
- Risk Intelligence Challenge 2017: Information SessionДокумент12 страницRisk Intelligence Challenge 2017: Information SessionxtheleОценок пока нет
- Team Alpha +: Case Study: UberДокумент12 страницTeam Alpha +: Case Study: UberxtheleОценок пока нет
- Portfolio Selection Problems in Practice: A Comparison Between Linear and Quadratic Optimization ModelsДокумент28 страницPortfolio Selection Problems in Practice: A Comparison Between Linear and Quadratic Optimization ModelsxtheleОценок пока нет
- Syzygy Super ComputingДокумент3 страницыSyzygy Super ComputingxtheleОценок пока нет
- Philosophy Reviewer Lesson 1 4Документ10 страницPhilosophy Reviewer Lesson 1 4Ethan Dwayn H. ContrevidaОценок пока нет
- The Chi-Squared Test With TI-Nspire IB10Документ5 страницThe Chi-Squared Test With TI-Nspire IB10p_gyftopoulosОценок пока нет
- 179 1089 1 PBДокумент10 страниц179 1089 1 PBTarunaОценок пока нет
- Regression Model 1: Square Footage: Variables Entered/RemovedДокумент4 страницыRegression Model 1: Square Footage: Variables Entered/RemovedsamikhanОценок пока нет
- Methods of Research Chapter 4. Research at Paradigm LevelДокумент26 страницMethods of Research Chapter 4. Research at Paradigm LevellornfateОценок пока нет
- Part 1: Regression Model With Dummy VariablesДокумент16 страницPart 1: Regression Model With Dummy VariablestoancaoОценок пока нет
- Stats Lab Exp-4 PDFДокумент5 страницStats Lab Exp-4 PDFHUSSAIN MUSTAFA LALОценок пока нет
- Chapter 4 Hypothesis Testing1Документ43 страницыChapter 4 Hypothesis Testing1Mohd NajibОценок пока нет
- Hypothesis Testing Z and T Tests (CHAPTER 8)Документ11 страницHypothesis Testing Z and T Tests (CHAPTER 8)Hilda Nur Indah LestariОценок пока нет
- Quiz On Ztest and TtestДокумент3 страницыQuiz On Ztest and TtestApril Joy JomocanОценок пока нет
- Mariano La FinalsДокумент2 страницыMariano La FinalsMARIANO, AIRA MAE A.100% (1)
- Practical Research 1: Quarter 3 - Module 14: Literature Review: Elements and EthicsДокумент24 страницыPractical Research 1: Quarter 3 - Module 14: Literature Review: Elements and EthicsRemar Jhon Paine100% (2)
- Hypothesis Testing For One PopulationДокумент57 страницHypothesis Testing For One PopulationFarah CakeyОценок пока нет
- Ects1 Buzea Stefania GeorgianaДокумент82 страницыEcts1 Buzea Stefania GeorgianaPirtac Vladut-MihaiОценок пока нет
- 1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 1 30Документ30 страниц1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 1 30AlvaroОценок пока нет
- Quartarly Data For Car Sales Year Quarter Sales (1000s) Year 1Документ11 страницQuartarly Data For Car Sales Year Quarter Sales (1000s) Year 1Alreem rsxr1Оценок пока нет
- A Book On The Incompleteness of Knowledge and The Effects of The High-Impact UncertaintyДокумент70 страницA Book On The Incompleteness of Knowledge and The Effects of The High-Impact UncertaintyRabih SouaidОценок пока нет
- MMW - Sample OBE Syllabus - RevisedДокумент9 страницMMW - Sample OBE Syllabus - Revisedjescy pauloОценок пока нет
- Journal of Information Science: The Knowledge Pyramid: A Critique of The DIKW HierarchyДокумент13 страницJournal of Information Science: The Knowledge Pyramid: A Critique of The DIKW Hierarchyjrg3k5Оценок пока нет
- Wilcoxon Rank Sum TestДокумент11 страницWilcoxon Rank Sum TestveniОценок пока нет
- Fire and Arson InvestigationДокумент74 страницыFire and Arson InvestigationPolgadas L. SamОценок пока нет
- The Core of Design Thinking' and Its Application: Rowe, 1987Документ12 страницThe Core of Design Thinking' and Its Application: Rowe, 1987janne nadyaОценок пока нет
- EDA-HYPOTHESIS-TESTING-FOR-TWO-SAMPLE (With Answers)Документ6 страницEDA-HYPOTHESIS-TESTING-FOR-TWO-SAMPLE (With Answers)Maryang DescartesОценок пока нет
- Statistics For Business and Economics: Anderson Sweeney WilliamsДокумент25 страницStatistics For Business and Economics: Anderson Sweeney WilliamsBrenda BernardОценок пока нет
- DID PrincetonДокумент38 страницDID PrincetoningОценок пока нет
- PAIRED T TEST Note and Example1Документ25 страницPAIRED T TEST Note and Example1Zul ZhafranОценок пока нет
- PurCom Quiz Week7-8Документ3 страницыPurCom Quiz Week7-8Y JОценок пока нет
- Module 1.4 Argumentation and Problem SolvingДокумент44 страницыModule 1.4 Argumentation and Problem SolvingEdel AdolfoОценок пока нет
- Case Assignment 7 Data Spring 2023Документ2 033 страницыCase Assignment 7 Data Spring 2023api-700897746Оценок пока нет