Вам также может понравиться
- Google Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformОт EverandGoogle Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformРейтинг: 5 из 5 звезд5/5 (1)
- Paarallell Computing (Iit Delhi)Документ47 страницPaarallell Computing (Iit Delhi)Ayush kumar singhОценок пока нет
- Par CompДокумент94 страницыPar CompPrasad GowdaОценок пока нет
- Clustering Grocery ItemsДокумент40 страницClustering Grocery ItemsNarige RishiОценок пока нет
- Design of 32 Bit Vedic Multiplier Using Carry Look Ahead AdderДокумент5 страницDesign of 32 Bit Vedic Multiplier Using Carry Look Ahead AdderGRD JournalsОценок пока нет
- ERP and EDIДокумент23 страницыERP and EDIIzhan AОценок пока нет
- Real Time SystemДокумент1 страницаReal Time SystemSupervis0rОценок пока нет
- Data Analysis Nirvana: Excel 2013 Business Intelligence FeaturesДокумент27 страницData Analysis Nirvana: Excel 2013 Business Intelligence FeaturesOmar Jamanca Shuan100% (1)
- Enterprise Architecture PlanningДокумент28 страницEnterprise Architecture PlanningWazzupdude101Оценок пока нет
- Naukri KishorDattatrayaMohite (16y 0m)Документ6 страницNaukri KishorDattatrayaMohite (16y 0m)Shubha S SОценок пока нет
- Introduction To Software EngineeringДокумент23 страницыIntroduction To Software EngineeringyamkelaОценок пока нет
- SQL Server Database Development Best Practices: Grant Fritchey, Red Gate SoftwareДокумент21 страницаSQL Server Database Development Best Practices: Grant Fritchey, Red Gate SoftwareAlaa IslamОценок пока нет
- WH 7 Cls 12Документ33 страницыWH 7 Cls 12Veronica GavanОценок пока нет
- Tapmi IT For Business and HRIS (HRS6600) Session 3Документ16 страницTapmi IT For Business and HRIS (HRS6600) Session 3Tv21 OrgОценок пока нет
- Certified Artificial Intelligence Practitioner 1Документ43 страницыCertified Artificial Intelligence Practitioner 1MIresh RsОценок пока нет
- Javaone - J2ee Platform Design Patterns For Enterprise AppliДокумент48 страницJavaone - J2ee Platform Design Patterns For Enterprise Appliapi-3770339100% (1)
- Sumit - Template (4) - 1Документ1 страницаSumit - Template (4) - 1Sumit KumarОценок пока нет
- Managing The Digital Firm: Chapter (6) CNT'D Introduction To BIДокумент21 страницаManaging The Digital Firm: Chapter (6) CNT'D Introduction To BIAhmad YasserОценок пока нет
- SEC Spring2022 Lecture#1Документ47 страницSEC Spring2022 Lecture#1WaleedОценок пока нет
- Software Engineering: NIIT LTD, AgraДокумент20 страницSoftware Engineering: NIIT LTD, AgraHARSHA100% (2)
- BDA Module1Документ64 страницыBDA Module1Nidhi SrivastavaОценок пока нет
- Data Engineering Questions Answers 1679109980Документ26 страницData Engineering Questions Answers 1679109980Suzana GomesОценок пока нет
- Lecture 2 Big DataДокумент15 страницLecture 2 Big DatafarheenОценок пока нет
- SE IntroductionДокумент30 страницSE IntroductionSandip UОценок пока нет
- Naukri NeerajKumar (2y 0m)Документ1 страницаNaukri NeerajKumar (2y 0m)rajendrasОценок пока нет
- Aryan Resume FinalДокумент1 страницаAryan Resume Finalpradyut.agrawal18Оценок пока нет
- Aryan Resume FinalДокумент1 страницаAryan Resume Finalpradyut.agrawal18Оценок пока нет
- Mtech Big Data Analytics SRMДокумент13 страницMtech Big Data Analytics SRMRoam SimenthyОценок пока нет
- Mapreduce: Simplified Data Analysis of Big Data: SciencedirectДокумент9 страницMapreduce: Simplified Data Analysis of Big Data: Sciencedirectmfs coreОценок пока нет
- Cloud Tutorial Part 1Документ86 страницCloud Tutorial Part 1durgasaraswathi9111Оценок пока нет
- Lecture 1.1 - Introduction To DEДокумент27 страницLecture 1.1 - Introduction To DEzakiamine97Оценок пока нет
- By: Akshat Singhai Arpit Sharma Bhuwan Chandra Gaurav JindalДокумент14 страницBy: Akshat Singhai Arpit Sharma Bhuwan Chandra Gaurav JindalArpit SharmaОценок пока нет
- IT615 Aut 2022 Requirements Collection & AnalysisДокумент23 страницыIT615 Aut 2022 Requirements Collection & AnalysisAkash AichОценок пока нет
- Edge IntelligenceДокумент16 страницEdge IntelligenceVaraprasad DОценок пока нет
- Future of Data Sciences With Respect To HCIДокумент35 страницFuture of Data Sciences With Respect To HCIFatima ArifОценок пока нет
- LECT-standard For Data ExchДокумент20 страницLECT-standard For Data ExchReilyОценок пока нет
- Curriculum INSOFEДокумент4 страницыCurriculum INSOFEKishan hariОценок пока нет
- Gig As Paces DataGrid OGF Oct07Документ46 страницGig As Paces DataGrid OGF Oct07MuralidharОценок пока нет
- ECE 462/562 Computer Architecture and Design: T-TH 12:30-1:45 in HARV210 WWW - Ece.arizona - Edu/ Ece462Документ39 страницECE 462/562 Computer Architecture and Design: T-TH 12:30-1:45 in HARV210 WWW - Ece.arizona - Edu/ Ece462muthurajkumarssОценок пока нет
- Dco Introduction PPДокумент46 страницDco Introduction PPSHIVANG PANDEYОценок пока нет
- Grid Computing: G.VenkataramanaДокумент15 страницGrid Computing: G.VenkataramanaSeethamani PalanivelОценок пока нет
- Introduction To Parallel Computing: Ananth Grama, Anshul Gupta, George Karypis, and Vipin KumarДокумент15 страницIntroduction To Parallel Computing: Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumarsatish161188Оценок пока нет
- Survey On Clustering Techniques in Data Mining For So Ware EngineeringДокумент7 страницSurvey On Clustering Techniques in Data Mining For So Ware Engineeringmamudu francisОценок пока нет
- Ankit ResumeДокумент1 страницаAnkit ResumeAman NegiОценок пока нет
- PoM-4.7 - IDA-Scale, Complexity, Computing, ProcessДокумент10 страницPoM-4.7 - IDA-Scale, Complexity, Computing, ProcessDhiraj SharmaОценок пока нет
- Databricks Lakehouse OverviewДокумент148 страницDatabricks Lakehouse OverviewA NoraznizamОценок пока нет
- L1 - Course IntroДокумент22 страницыL1 - Course Introchowsaj9Оценок пока нет
- Rapid Decision For JD Edwards 20081Документ8 страницRapid Decision For JD Edwards 20081SursarovarОценок пока нет
- Jde Iot Orchestrator 2889921 PDFДокумент3 страницыJde Iot Orchestrator 2889921 PDFkcmkcmОценок пока нет
- Big DataДокумент37 страницBig DataHaggy TomtomОценок пока нет
- Guddu UpadateResumeДокумент1 страницаGuddu UpadateResumeGuddu Kumar SinghОценок пока нет
- 128 Sandeep HebbarДокумент2 страницы128 Sandeep HebbarSai CharanОценок пока нет
- Presentation 2Документ25 страницPresentation 2Iftikhar AhmedОценок пока нет
- Resume of Keerthi Kiran.V.J Confidential Page 1 of 3Документ3 страницыResume of Keerthi Kiran.V.J Confidential Page 1 of 3Goldie KapurОценок пока нет
- Main PDFДокумент2 страницыMain PDFziya mohammedОценок пока нет
- Grid ComputingДокумент15 страницGrid ComputingUpender UprОценок пока нет
- Object Oriented Software Engineering Solved Question Paper by MCA Scholar's GroupДокумент23 страницыObject Oriented Software Engineering Solved Question Paper by MCA Scholar's GroupAkshad JaiswalОценок пока нет
- Graph Technology Buyers Guide EN A4Документ34 страницыGraph Technology Buyers Guide EN A4mona_mi8202Оценок пока нет
- Ashish Kedia ResumeДокумент2 страницыAshish Kedia Resumeadi chopra75% (4)
- Sample Quality Control KPIs For Construction ProjectДокумент2 страницыSample Quality Control KPIs For Construction ProjectNavneet Soni100% (3)
- Conventional Shuttering Planning Calculations: C-Type Building (3no's)Документ2 страницыConventional Shuttering Planning Calculations: C-Type Building (3no's)Navneet SoniОценок пока нет
- PM Online CoursesДокумент1 страницаPM Online CoursesNavneet SoniОценок пока нет
- Project Management: Interview Questions With AnswersДокумент6 страницProject Management: Interview Questions With AnswersNavneet Soni100% (1)
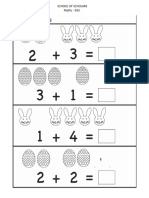
- MathsKG II 1 - 1Документ1 страницаMathsKG II 1 - 1Navneet SoniОценок пока нет
- Sample WBS EPC ProjectДокумент7 страницSample WBS EPC ProjectNavneet Soni100% (1)
- Project Evaluation & Review Techniques: CPM Du Pont Corporation and Remington-Rand)Документ87 страницProject Evaluation & Review Techniques: CPM Du Pont Corporation and Remington-Rand)Navneet SoniОценок пока нет
- Bidding StrategiesДокумент17 страницBidding StrategiesNavneet Soni100% (1)
- Interview Email TemplateДокумент7 страницInterview Email TemplateNavneet SoniОценок пока нет
- Igbc Test PaperДокумент16 страницIgbc Test PaperSupriya Sain RanaОценок пока нет
- Catalu PDFДокумент17 страницCatalu PDFNavneet SoniОценок пока нет
- Safety Plan: A) Personal Protective Equipment (Ppe)Документ4 страницыSafety Plan: A) Personal Protective Equipment (Ppe)Navneet SoniОценок пока нет
- Nsplan PDFДокумент1 страницаNsplan PDFNavneet SoniОценок пока нет
- Heading 1Документ15 страницHeading 1Navneet SoniОценок пока нет
- Environmental Initiatives in Nagpur Metro - IricenДокумент10 страницEnvironmental Initiatives in Nagpur Metro - IricenNavneet SoniОценок пока нет
- Judgement That Changed IndiaДокумент14 страницJudgement That Changed IndiaNavneet SoniОценок пока нет
- CH 4Документ22 страницыCH 4Manprita BasumataryОценок пока нет
- Excel KolwanДокумент2 страницыExcel KolwanNavneet SoniОценок пока нет
- Stunning Floral Inspired Religious Building-Lotus TempleДокумент7 страницStunning Floral Inspired Religious Building-Lotus TempleNavneet SoniОценок пока нет
- Ma Slows Hierarchy of NeedДокумент36 страницMa Slows Hierarchy of NeedNavneet SoniОценок пока нет
- TQM Review Lecture 2010Документ97 страницTQM Review Lecture 2010Vicky de ChavezОценок пока нет
- TQM Review Lecture 2010Документ97 страницTQM Review Lecture 2010Vicky de ChavezОценок пока нет
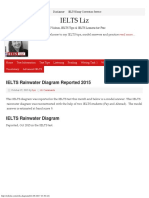
- IELTS Rainwater Diagram Reported 2015 PDFДокумент20 страницIELTS Rainwater Diagram Reported 2015 PDFNavneet SoniОценок пока нет
- Academic Calender Ay: 2017-18: Undergraduate, Postgraduate & PHD ProgramsДокумент4 страницыAcademic Calender Ay: 2017-18: Undergraduate, Postgraduate & PHD ProgramsPratik KothariОценок пока нет
- G 12Документ1 страницаG 12Navneet SoniОценок пока нет
- Construction Quality Management (GROUP - 6) : Project: Gravity Dam Material: Reinforcement Steel Kaizen TechnologyДокумент43 страницыConstruction Quality Management (GROUP - 6) : Project: Gravity Dam Material: Reinforcement Steel Kaizen TechnologyNavneet SoniОценок пока нет
- Reinforcement SteelДокумент7 страницReinforcement SteelNavneet SoniОценок пока нет
- IELTS Rainwater Diagram Reported 2015 PDFДокумент20 страницIELTS Rainwater Diagram Reported 2015 PDFNavneet SoniОценок пока нет
- Details of Linear Aspects in Drainge Network Analysis of Study AreaДокумент2 страницыDetails of Linear Aspects in Drainge Network Analysis of Study AreaNavneet SoniОценок пока нет
- Form IEPF 2 - 2012 2013FДокумент2 350 страницForm IEPF 2 - 2012 2013FYam ServínОценок пока нет
- VSL Synchron Pianos Changelog en 1.1.1386Документ4 страницыVSL Synchron Pianos Changelog en 1.1.1386RdWingОценок пока нет
- Antonov 225 - The Largest - Airliner in The WorldДокумент63 страницыAntonov 225 - The Largest - Airliner in The WorldFridayFunStuffОценок пока нет
- Topic 3 - Analyzing The Marketing EnvironmentДокумент28 страницTopic 3 - Analyzing The Marketing Environmentmelissa chlОценок пока нет
- Haematology Test Name Results Biological Reference Interval Units Specimen Test Method CBC - Complete Blood CountДокумент8 страницHaematology Test Name Results Biological Reference Interval Units Specimen Test Method CBC - Complete Blood CountArun DheekshahОценок пока нет
- rOCKY Dem Manual (010-057)Документ48 страницrOCKY Dem Manual (010-057)eduardo huancaОценок пока нет
- W1 - V1 MultipleWorksheets SolnДокумент3 страницыW1 - V1 MultipleWorksheets SolnAKHIL RAJ SОценок пока нет
- Topic 3 Module 2 Simple Annuity (Savings Annuity and Payout Annuity)Документ8 страницTopic 3 Module 2 Simple Annuity (Savings Annuity and Payout Annuity)millerОценок пока нет
- Software Requirements SpecificationДокумент9 страницSoftware Requirements SpecificationSu-kEm Tech LabОценок пока нет
- Ingredients EnsaymadaДокумент3 страницыIngredients Ensaymadajessie OcsОценок пока нет
- Digital-To-Analog Converter - Wikipedia, The Free EncyclopediaДокумент8 страницDigital-To-Analog Converter - Wikipedia, The Free EncyclopediaAnilkumar KubasadОценок пока нет
- TLE-Carpentry7 Q4M4Week4 PASSED NoAKДокумент12 страницTLE-Carpentry7 Q4M4Week4 PASSED NoAKAmelita Benignos OsorioОценок пока нет
- Physiology of Eye. Physiology of VisionДокумент27 страницPhysiology of Eye. Physiology of VisionSmartcool So100% (1)
- CFA L1 Ethics Questions and AnswersДокумент94 страницыCFA L1 Ethics Questions and AnswersMaulik PatelОценок пока нет
- Comparativa Microplex F40 Printronix P8220 enДокумент1 страницаComparativa Microplex F40 Printronix P8220 enangel ricaОценок пока нет
- Problem Solving Questions: Solutions (Including Comments)Документ25 страницProblem Solving Questions: Solutions (Including Comments)Narendrn KanaesonОценок пока нет
- Chapter 1Документ20 страницChapter 1Li YuОценок пока нет
- PCI Secure Software Standard v1 - 0Документ67 страницPCI Secure Software Standard v1 - 0Antonio ClimaОценок пока нет
- Dur MalappuramДокумент114 страницDur MalappuramSabareesh RaveendranОценок пока нет
- Lesson Plan Cot1Документ9 страницLesson Plan Cot1Paglinawan Al KimОценок пока нет
- Journal of Power Sources: Binyu Xiong, Jiyun Zhao, Zhongbao Wei, Maria Skyllas-KazacosДокумент12 страницJournal of Power Sources: Binyu Xiong, Jiyun Zhao, Zhongbao Wei, Maria Skyllas-KazacosjayashreeОценок пока нет
- Comparison of Offline and Online Partial Discharge For Large Mot PDFДокумент4 страницыComparison of Offline and Online Partial Discharge For Large Mot PDFcubarturОценок пока нет
- Understand Fox Behaviour - Discover WildlifeДокумент1 страницаUnderstand Fox Behaviour - Discover WildlifeChris V.Оценок пока нет
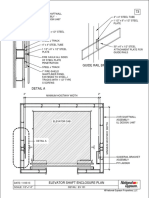
- Guide Rail Bracket AssemblyДокумент1 страницаGuide Rail Bracket AssemblyPrasanth VarrierОценок пока нет
- Where Business Happens Where Happens: SupportДокумент19 страницWhere Business Happens Where Happens: SupportRahul RamtekkarОценок пока нет
- Windows Server 2016 Technical Preview NIC and Switch Embedded Teaming User GuideДокумент61 страницаWindows Server 2016 Technical Preview NIC and Switch Embedded Teaming User GuidenetvistaОценок пока нет
- APPSC GR I Initial Key Paper IIДокумент52 страницыAPPSC GR I Initial Key Paper IIdarimaduguОценок пока нет
- SITXWHS001 - Participate in Safe Work Practices Student GuideДокумент42 страницыSITXWHS001 - Participate in Safe Work Practices Student GuideMarianne FernandoОценок пока нет
- Painting: 22.1 Types of PaintsДокумент8 страницPainting: 22.1 Types of PaintsRosy RoseОценок пока нет
- Filtomat M300Документ4 страницыFiltomat M300Sasa Jadrovski100% (1)