Вам также может понравиться
- Econ ML3Документ5 страницEcon ML3Josh LiОценок пока нет
- Econ ML2Документ6 страницEcon ML2Josh LiОценок пока нет
- Bar Plot - SHAP Latest DocumentationДокумент1 страницаBar Plot - SHAP Latest DocumentationTushita GОценок пока нет
- RANDOM FOREST (Binary Classification)Документ5 страницRANDOM FOREST (Binary Classification)Noor Ul HaqОценок пока нет
- Package Automl': R Topics DocumentedДокумент12 страницPackage Automl': R Topics DocumentedLESALINASОценок пока нет
- Areslab Adaptive Regression Splines Toolbox For Matlab/OctaveДокумент33 страницыAreslab Adaptive Regression Splines Toolbox For Matlab/OctaveSaujanya Kumar SahuОценок пока нет
- Locally Interpretable Model-Agnostic Explanations (Lime) : Solfinder ResearchДокумент11 страницLocally Interpretable Model-Agnostic Explanations (Lime) : Solfinder ResearchPrateekОценок пока нет
- Introduction To MATLAB: Done By: Eng. Shima' Abed Rabbo Eng. Arwa AqelДокумент59 страницIntroduction To MATLAB: Done By: Eng. Shima' Abed Rabbo Eng. Arwa AqelAhmad Abu SaifОценок пока нет
- SDETДокумент6 страницSDETgunaОценок пока нет
- Apply, Lapply, Sapply, Tapply Function in R With ExamplesДокумент10 страницApply, Lapply, Sapply, Tapply Function in R With Examplesicen00bОценок пока нет
- Table of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingДокумент15 страницTable of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingsgОценок пока нет
- Simple Guide To Optuna For Hyperparameters OptimizationTuningДокумент29 страницSimple Guide To Optuna For Hyperparameters OptimizationTuningRadha KilariОценок пока нет
- Project - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Документ38 страницProject - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Ravi KotharuОценок пока нет
- BES - R Lab 1Документ4 страницыBES - R Lab 1Viem AnhОценок пока нет
- Experiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaДокумент55 страницExperiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaJayesh bansalОценок пока нет
- CO-367 Machine Learning Lab File: Submitted To: Submitted byДокумент12 страницCO-367 Machine Learning Lab File: Submitted To: Submitted byShubham AnandОценок пока нет
- Maxbox Starter60 Machine LearningДокумент8 страницMaxbox Starter60 Machine LearningMax KleinerОценок пока нет
- Explain Machine Learning Model Using SHAPДокумент28 страницExplain Machine Learning Model Using SHAPsediha5178Оценок пока нет
- Advanced Machine Learning and Feature Engineering: StackingДокумент7 страницAdvanced Machine Learning and Feature Engineering: StackingAtmuri GaneshОценок пока нет
- KT 01 Intro2KerasДокумент24 страницыKT 01 Intro2KerasBalaji VenkateswaranОценок пока нет
- EE2211 CheatSheetДокумент15 страницEE2211 CheatSheetAditiОценок пока нет
- Data Mining Exercise 3Документ11 страницData Mining Exercise 3Mohamed BoukhariОценок пока нет
- Estimating DSGE Models With DynareДокумент45 страницEstimating DSGE Models With DynareGilbert ADJASSOUОценок пока нет
- Utf 8''week4Документ15 страницUtf 8''week4devendra416Оценок пока нет
- Intro To ForecastingДокумент15 страницIntro To ForecastingtrickledowntheroadОценок пока нет
- Aya Raied Assignment 2Документ4 страницыAya Raied Assignment 2رمقالحياةОценок пока нет
- Dap Module5 (New 2024)Документ21 страницаDap Module5 (New 2024)Mahesha S N ReddyОценок пока нет
- Mat Lab IntroДокумент25 страницMat Lab IntroThahseen ThahirОценок пока нет
- Polynomial Interpolation SICLABДокумент16 страницPolynomial Interpolation SICLABAlexander Diaz AlvarezОценок пока нет
- Opening Black Boxes: How To Leverage Explainable Machine LearningДокумент11 страницOpening Black Boxes: How To Leverage Explainable Machine LearningSowrya ReganaОценок пока нет
- Modelling and Error AnalysisДокумент8 страницModelling and Error AnalysisAtmuri GaneshОценок пока нет
- Introduction To MATLABДокумент79 страницIntroduction To MATLABPrasanna LakshmiОценок пока нет
- Introduction To MatlabДокумент22 страницыIntroduction To MatlabarifmjОценок пока нет
- STAT 582: MATLAB Primer For Statistical AnalysisДокумент10 страницSTAT 582: MATLAB Primer For Statistical AnalysisJoséОценок пока нет
- Fsolve 1Документ16 страницFsolve 1mrloadmovieОценок пока нет
- M5 Prime LabДокумент10 страницM5 Prime LabpinkkittyjadeОценок пока нет
- Matlab FileДокумент22 страницыMatlab FileVyomОценок пока нет
- Lab 00 IntroMATLAB1 PDFДокумент25 страницLab 00 IntroMATLAB1 PDF'Jph Flores BmxОценок пока нет
- Unit 1 MatlabДокумент21 страницаUnit 1 MatlabJ. Beryl GraciaОценок пока нет
- Data Visualization - Introduction To Matplotlib Cheatsheet - CodecademyДокумент3 страницыData Visualization - Introduction To Matplotlib Cheatsheet - CodecademyUtsav SoiОценок пока нет
- Clustsig RДокумент7 страницClustsig RSeverodvinsk MasterskayaОценок пока нет
- Experiment #3Документ9 страницExperiment #3Jhustine CañeteОценок пока нет
- SciLab For DummiesДокумент34 страницыSciLab For Dummiesnarendra133100% (4)
- RapidMiner Data TypesДокумент4 страницыRapidMiner Data TypesSatyajeet GaurОценок пока нет
- Python Solve CAT2Документ17 страницPython Solve CAT2Er Sachin ShandilyaОценок пока нет
- XAI FinalДокумент18 страницXAI FinalRomil MehlaОценок пока нет
- Lec 1 Matlab Quick GuideДокумент103 страницыLec 1 Matlab Quick GuideZulfiqar Ali100% (1)
- Matlab IntroДокумент25 страницMatlab IntroGlan DevadhasОценок пока нет
- Data Fitting Using ScilabДокумент15 страницData Fitting Using Scilabsiva_ksrОценок пока нет
- UntitledДокумент15 страницUntitledrahardian hОценок пока нет
- Control Systems Lab Manual in Sci LabДокумент28 страницControl Systems Lab Manual in Sci LabJames Matthew WongОценок пока нет
- ML NBs TutДокумент3 страницыML NBs TutKereshlin MichaelОценок пока нет
- Introduction To Spatstat: Adrian Baddeley and Rolf Turner Spatstat Version 1.8-6Документ43 страницыIntroduction To Spatstat: Adrian Baddeley and Rolf Turner Spatstat Version 1.8-6Lintang PrasastiОценок пока нет
- Slide 8Документ6 страницSlide 8RJ RajpootОценок пока нет
- Regression Linaire Python Tome IIДокумент10 страницRegression Linaire Python Tome IIElisée TEGUEОценок пока нет
- 16.java8 FeaturesДокумент6 страниц16.java8 FeaturesVignesh VickyОценок пока нет
- KerasДокумент3 страницыKerasmagas32862Оценок пока нет
- 2MBI100N-060: 600V / 100A 2 in One-PackageДокумент4 страницы2MBI100N-060: 600V / 100A 2 in One-PackageAmc Forklift ElektrikОценок пока нет
- Gps Motorcycle Tracker Gps + GSM + Sms / GPRS: User ManualДокумент11 страницGps Motorcycle Tracker Gps + GSM + Sms / GPRS: User ManualAmc Forklift ElektrikОценок пока нет
- Gps Motorcycle Tracker Gps + GSM + Sms / GPRS: User ManualДокумент11 страницGps Motorcycle Tracker Gps + GSM + Sms / GPRS: User ManualAmc Forklift ElektrikОценок пока нет
- TCM F Series Service Manual PDFДокумент145 страницTCM F Series Service Manual PDFAmc Forklift Elektrik100% (7)
- Noblelift CS1546M Parts Manual PDFДокумент51 страницаNoblelift CS1546M Parts Manual PDFAmc Forklift ElektrikОценок пока нет
- Sumitomo 1-1,8 Ton Reach Forklift Truck Brochure PDFДокумент2 страницыSumitomo 1-1,8 Ton Reach Forklift Truck Brochure PDFAmc Forklift ElektrikОценок пока нет
- Sumitomo 1-1,8 Ton Reach Forklift Truck BrochureДокумент2 страницыSumitomo 1-1,8 Ton Reach Forklift Truck BrochureAmc Forklift ElektrikОценок пока нет
- Conductive Sensors Level Probes Types VT, VTI: Product Description Ordering Key Vti 4Документ1 страницаConductive Sensors Level Probes Types VT, VTI: Product Description Ordering Key Vti 4Amc Forklift ElektrikОценок пока нет
- PTC Thermistors For Overcurrent Protection: Leaded Disks, Coated, 230 VДокумент17 страницPTC Thermistors For Overcurrent Protection: Leaded Disks, Coated, 230 VAmc Forklift Elektrik100% (1)
- Vehicle Alarm System 'E50': 1. Technical SpecificationsДокумент4 страницыVehicle Alarm System 'E50': 1. Technical SpecificationsAmc Forklift ElektrikОценок пока нет
- MDD4N20YДокумент6 страницMDD4N20YAmc Forklift ElektrikОценок пока нет
- PDF Controller: HTML To Postscript For TYPO3Документ42 страницыPDF Controller: HTML To Postscript For TYPO3Amc Forklift ElektrikОценок пока нет
- TSOP382.., TSOP384..: Vishay SemiconductorsДокумент7 страницTSOP382.., TSOP384..: Vishay SemiconductorsAmc Forklift ElektrikОценок пока нет
- 24+4g-Port Layer 2/layer 3 Gigabit Modular Managed Ethernet SwitchesДокумент6 страниц24+4g-Port Layer 2/layer 3 Gigabit Modular Managed Ethernet SwitchesAmc Forklift ElektrikОценок пока нет
- Content://com Opera Mini Native Operafile/?o file:///storage/emulated/0/Download/72PINEERENGB2Документ12 страницContent://com Opera Mini Native Operafile/?o file:///storage/emulated/0/Download/72PINEERENGB2Amc Forklift ElektrikОценок пока нет
- MDD1902 PDFДокумент6 страницMDD1902 PDFAmc Forklift ElektrikОценок пока нет
- NPN BD136 - BD138 - BD140 Silicon Planar Epitaxial Power TransistorsДокумент3 страницыNPN BD136 - BD138 - BD140 Silicon Planar Epitaxial Power TransistorsAmc Forklift ElektrikОценок пока нет
- Função de GudermannДокумент3 страницыFunção de GudermannElaine MoratoОценок пока нет
- Lecture Notes 8 Other Transcendental FunctionsДокумент8 страницLecture Notes 8 Other Transcendental FunctionsJustin Paul TumaliuanОценок пока нет
- ErrtДокумент101 страницаErrtMadhav KumarОценок пока нет
- Some General Families of The Hurwitz-Lerch Zeta Functions and Their Applications: Recent Developments and Directions For Further ResearchesДокумент36 страницSome General Families of The Hurwitz-Lerch Zeta Functions and Their Applications: Recent Developments and Directions For Further ResearchesInforma.azОценок пока нет
- A Short Note On P-Value Hacking: Nassim Nicholas Taleb Tandon School of EngineeringДокумент4 страницыA Short Note On P-Value Hacking: Nassim Nicholas Taleb Tandon School of Engineeringt435486Оценок пока нет
- Chapter 57: Heating and Convection On A Plate For Heat ExchangerДокумент12 страницChapter 57: Heating and Convection On A Plate For Heat ExchangerDan WolfОценок пока нет
- Find Courses by Course NumberДокумент1 страницаFind Courses by Course NumberramureddygsОценок пока нет
- Applications of Linear Systems: Ryan C. DailedaДокумент23 страницыApplications of Linear Systems: Ryan C. DailedaRadish KumarОценок пока нет
- Geometry of Projective Algebraic CurvesДокумент429 страницGeometry of Projective Algebraic CurvesluisufspaiandreОценок пока нет
- 9th Math Chapter-WiseДокумент18 страниц9th Math Chapter-WiseDarkhshanday RanaОценок пока нет
- Properties of Rational Numbers With ExamplesДокумент4 страницыProperties of Rational Numbers With Examplestutorciecle123Оценок пока нет
- Min/Max Problems and InequalitiesДокумент3 страницыMin/Max Problems and InequalitiesOtávio José Dezem Bertozzi Jr.Оценок пока нет
- Intermediate Value Theorem: ContinuousДокумент16 страницIntermediate Value Theorem: ContinuousmasyatiОценок пока нет
- MA5155-Applied Mathematics For Electrical Engineers-QBДокумент21 страницаMA5155-Applied Mathematics For Electrical Engineers-QBantoabi43% (7)
- SEAM-Maths1-1.2 SD-Trigonometric Functions 28-8-19 SPCEДокумент13 страницSEAM-Maths1-1.2 SD-Trigonometric Functions 28-8-19 SPCESatish BarotОценок пока нет
- Teacher Guide-Rational NumbersДокумент9 страницTeacher Guide-Rational NumbersPrasanthОценок пока нет
- Logan Applied Mathematics Solution ManualДокумент63 страницыLogan Applied Mathematics Solution Manualjd24680100% (2)
- Compact Expanded Synthetic Division - WikipediaДокумент2 страницыCompact Expanded Synthetic Division - WikipediaCupa no DensetsuОценок пока нет
- Ex# (3.1-3.2-3.4) First Year StepДокумент11 страницEx# (3.1-3.2-3.4) First Year StepAqeel AbbasОценок пока нет
- Probability and StatisticsДокумент415 страницProbability and StatisticstaylorОценок пока нет
- Assignment 1Документ4 страницыAssignment 1ngunasenaОценок пока нет
- LSTM PDFДокумент48 страницLSTM PDFAZEDDINEОценок пока нет
- Systems of Linear Equations and Matrices: Shirley HuangДокумент51 страницаSystems of Linear Equations and Matrices: Shirley HuangShu RunОценок пока нет
- Recurrent Problems: ITT9131 Konkreetne MatemaatikaДокумент87 страницRecurrent Problems: ITT9131 Konkreetne Matemaatika查人瑞Оценок пока нет
- INTRODUCTION TOnLINEAR PROGRAMMINGДокумент9 страницINTRODUCTION TOnLINEAR PROGRAMMINGPrincess Amber0% (2)
- 090 Robot Trajectory Generation enДокумент50 страниц090 Robot Trajectory Generation enbaboiu electricОценок пока нет
- AlgebraДокумент4 страницыAlgebravarchasva SharmaОценок пока нет
- Fundamentals of CFDДокумент276 страницFundamentals of CFDSainath SatishОценок пока нет
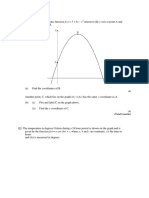
- Lecture 25Документ5 страницLecture 25Syeda Farkhanda Batool NaqviОценок пока нет
- Sadler-Specialist Mathematics-Unit 3A-Chapter 2-SolutionsДокумент17 страницSadler-Specialist Mathematics-Unit 3A-Chapter 2-SolutionsRolou15100% (1)