Вам также может понравиться
- CS 229: Machine Learning Problem Set 0 summaryДокумент5 страницCS 229: Machine Learning Problem Set 0 summaryWilliamMaОценок пока нет
- Simple Linear Regression (Part 2) : 1 Software R and Regression AnalysisДокумент14 страницSimple Linear Regression (Part 2) : 1 Software R and Regression AnalysisMousumi Kayet100% (1)
- Differential and Integral Calculus 2 - Homework 3 SolutionДокумент6 страницDifferential and Integral Calculus 2 - Homework 3 SolutionDominikОценок пока нет
- Q5 Ass 3Документ4 страницыQ5 Ass 3Kay AОценок пока нет
- R300 - Summer 2018 Advanced Econometric Methods Study AidДокумент9 страницR300 - Summer 2018 Advanced Econometric Methods Study AidMarco BrolliОценок пока нет
- Spline Iterpolation: Problem FormulationДокумент7 страницSpline Iterpolation: Problem Formulationsegorin2Оценок пока нет
- MENGESTIMASI MODEL REGRESSI LINIER BERGANDAДокумент31 страницаMENGESTIMASI MODEL REGRESSI LINIER BERGANDAAssyaerati Inezia100% (1)
- An4 Ex2Документ2 страницыAn4 Ex2chaymaahamou2015Оценок пока нет
- Linear Regression Lecture NotesДокумент11 страницLinear Regression Lecture NotesbprtxrcqilmqsvsdhrОценок пока нет
- 10/36-702 Statistical Machine Learning Homework #2 SolutionsДокумент11 страниц10/36-702 Statistical Machine Learning Homework #2 SolutionsSОценок пока нет
- Cal3 TD1 (2021 22)Документ6 страницCal3 TD1 (2021 22)Tang PisethОценок пока нет
- SB2b HT 2017 - Problem Sheet 1 - solutionsДокумент5 страницSB2b HT 2017 - Problem Sheet 1 - solutionsJamie ChanОценок пока нет
- MnI LabДокумент29 страницMnI LabRohit SatputeОценок пока нет
- 4. General Logarithm and ExponentialДокумент9 страниц4. General Logarithm and Exponentialbouchrabell734Оценок пока нет
- Assignment 2Документ2 страницыAssignment 2utpal singhОценок пока нет
- HW 3 SolДокумент4 страницыHW 3 SolSuper NezhОценок пока нет
- Simple Linear Regression.: 29.1 Method of Least SquaresДокумент4 страницыSimple Linear Regression.: 29.1 Method of Least SquaresDebashis GuptaОценок пока нет
- 1 Probeklausur-Loesungen-SS04Документ6 страниц1 Probeklausur-Loesungen-SS04Universität BielefeldОценок пока нет
- Assignment II: (To Be Submitted in Tutorial Class by September 13, 2019)Документ2 страницыAssignment II: (To Be Submitted in Tutorial Class by September 13, 2019)AnantaRajОценок пока нет
- Þ 3.4 Hermite Interpolation: Find The) F (X), P' (X) F ' (X),, P (X) F (X) For All I 0, 1,, NДокумент8 страницÞ 3.4 Hermite Interpolation: Find The) F (X), P' (X) F ' (X),, P (X) F (X) For All I 0, 1,, NguyОценок пока нет
- Unit 5 - Partial Derivatives: Case-1: (A, B) (0, 0)Документ35 страницUnit 5 - Partial Derivatives: Case-1: (A, B) (0, 0)Rakesh KushwahaОценок пока нет
- TD1 (Cal3)Документ124 страницыTD1 (Cal3)Tang PisethОценок пока нет
- Pde As 2Документ7 страницPde As 2sahlewel weldemichaelОценок пока нет
- Assignment 1Документ1 страницаAssignment 1Roop KishorОценок пока нет
- Ross Elementary AnalysisДокумент26 страницRoss Elementary AnalysisVaibhav KumarОценок пока нет
- Serie 1Документ3 страницыSerie 1Meli RtaОценок пока нет
- Extreme Points and Basic SolutionsДокумент4 страницыExtreme Points and Basic SolutionsHillal TOUATIОценок пока нет
- Rad 1Документ11 страницRad 1digitalnapismenost2022Оценок пока нет
- FormulaeДокумент1 страницаFormulaeaioponeriОценок пока нет
- Assignment 8 To 14 of MTH101AДокумент5 страницAssignment 8 To 14 of MTH101AbbbbbbОценок пока нет
- PDE Steebs Partial PDFДокумент139 страницPDE Steebs Partial PDFThumper KatesОценок пока нет
- Metric Spaces PDFДокумент33 страницыMetric Spaces PDFmatty20113Оценок пока нет
- MH2100 Tutorial 2 PDFДокумент3 страницыMH2100 Tutorial 2 PDFGabriel JosephОценок пока нет
- Isi JRF Stat 07Документ10 страницIsi JRF Stat 07api-26401608Оценок пока нет
- Script 2Документ62 страницыScript 2michaelОценок пока нет
- Probability - Full TextbookДокумент176 страницProbability - Full Textbookhmtnfbnh4nОценок пока нет
- Sr. No. of Question Paper 6697 Your Roll No ...............Документ2 страницыSr. No. of Question Paper 6697 Your Roll No ...............JgjbfhbbgbОценок пока нет
- FRM 2023Документ4 страницыFRM 2023olemas1984Оценок пока нет
- Solutions Quantum Mechanics 2 PDFДокумент43 страницыSolutions Quantum Mechanics 2 PDFAfrah MirОценок пока нет
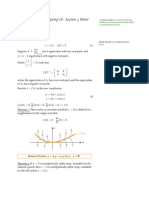
- EE C222/ME C237 - Spring'18 - Lecture 5 Notes: Murat Arcak January 31 2018Документ6 страницEE C222/ME C237 - Spring'18 - Lecture 5 Notes: Murat Arcak January 31 2018SBОценок пока нет
- Inference in Regression Analysis: Dr. Frank WoodДокумент32 страницыInference in Regression Analysis: Dr. Frank WoodLady AntasaОценок пока нет
- Tutorial Sheet 2: Indian Institute of Technology Gandhinagar - MA 102 Mathematics IIДокумент2 страницыTutorial Sheet 2: Indian Institute of Technology Gandhinagar - MA 102 Mathematics IIFaheem ShanavasОценок пока нет
- Nbody DissipativeДокумент10 страницNbody DissipativeFulana SchlemihlОценок пока нет
- (Calculus Oxford) Problem Sheet 04Документ2 страницы(Calculus Oxford) Problem Sheet 04AnyОценок пока нет
- Wa0001Документ3 страницыWa0001Sympathy BumhiraОценок пока нет
- The Mothod of Least Squares: Satya Mandal, KU March 26, 2007Документ5 страницThe Mothod of Least Squares: Satya Mandal, KU March 26, 2007ইশতিয়াক হোসেন সিদ্দিকীОценок пока нет
- Hw4-Vision14 Solution3Документ2 страницыHw4-Vision14 Solution3Mohiuddin AhmadОценок пока нет
- MIT2 25F13 Solution6.4 PDFДокумент5 страницMIT2 25F13 Solution6.4 PDFfunk singhОценок пока нет
- Tutorial Sheet 6multivariate CalculusДокумент2 страницыTutorial Sheet 6multivariate Calculuspremranjanv784Оценок пока нет
- Linear equations and sequencesДокумент19 страницLinear equations and sequencesJaehun JeongОценок пока нет
- Week 2, OLSДокумент83 страницыWeek 2, OLSAbdoulaye SakoОценок пока нет
- Note Chapter 8 Part 1Документ1 страницаNote Chapter 8 Part 1Hafzal GaniОценок пока нет
- Quadratic Function MinimizationДокумент5 страницQuadratic Function MinimizationAbiyОценок пока нет
- MidtermДокумент1 страницаMidterm3dd2ef652ed6f7Оценок пока нет
- FormulasДокумент1 страницаFormulaswincrestОценок пока нет
- Curve Fitting For Gtu AmeeДокумент20 страницCurve Fitting For Gtu AmeeMohsin AnsariОценок пока нет
- Putnam 1986 Solutions: Evan O'Dorney MATH 191, Prof. Alexander Givental September 12, 2009Документ2 страницыPutnam 1986 Solutions: Evan O'Dorney MATH 191, Prof. Alexander Givental September 12, 2009Anonymous zzINNSt1Оценок пока нет
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesОт EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesОценок пока нет
- Nonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970От EverandNonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Louis B. RallОценок пока нет
- Transformation of Axes (Geometry) Mathematics Question BankОт EverandTransformation of Axes (Geometry) Mathematics Question BankРейтинг: 3 из 5 звезд3/5 (1)
- Thread (Operating System)Документ17 страницThread (Operating System)hashimkainatОценок пока нет
- Airline Reservation SystemДокумент27 страницAirline Reservation SystemSwati GautamОценок пока нет
- M M The Publication of The Annotated C++ Reference Manual by Ellis and StroustrupДокумент6 страницM M The Publication of The Annotated C++ Reference Manual by Ellis and StroustrupHeena KapoorОценок пока нет
- C++ Cplusplus Cheat Sheet How To ProgramДокумент53 страницыC++ Cplusplus Cheat Sheet How To ProgrampetersonjrОценок пока нет
- Advanced PIC Microcontroller PIC 16F877Документ8 страницAdvanced PIC Microcontroller PIC 16F877Sinduja Balaji100% (1)
- 8051 Microcontroller Logical OperationsДокумент19 страниц8051 Microcontroller Logical OperationsAjins Aju0% (1)
- Oracle Database 12c Administration Workshop D78846GC10Документ5 страницOracle Database 12c Administration Workshop D78846GC10bugzbinnyОценок пока нет
- Spark2018eBook PDFДокумент194 страницыSpark2018eBook PDFAjay KumarОценок пока нет
- TFNSTRETEICT1100Документ49 страницTFNSTRETEICT1100Kamran MusaОценок пока нет
- 20762B ENU CompanionДокумент212 страниц20762B ENU Companionmiamikk2040% (1)
- Assignment 10Документ9 страницAssignment 10marina duttaОценок пока нет
- Steps of "Excel File Import To SPI"Документ4 страницыSteps of "Excel File Import To SPI"Bala MuruganОценок пока нет
- 8086 Microprocessor Complete: Bus Interface Unit (BIU)Документ10 страниц8086 Microprocessor Complete: Bus Interface Unit (BIU)Niroshan T AthaudaОценок пока нет
- E-learning resource locator software requirements specificationДокумент58 страницE-learning resource locator software requirements specificationjanajohnnyОценок пока нет
- Set SRDF pairs to async modeДокумент1 страницаSet SRDF pairs to async modeKrishna UppalaОценок пока нет
- Workbook-Essentials of Crestron ProgrammingДокумент100 страницWorkbook-Essentials of Crestron ProgrammingVenkatesh Babu Gudaru100% (1)
- Basic về query languageДокумент23 страницыBasic về query languageNguyen Khanh Hoa (TGV)Оценок пока нет
- Updating Firmware For Dell EqualLogic PS Series Storage Arrays and FS Series AppliancesДокумент46 страницUpdating Firmware For Dell EqualLogic PS Series Storage Arrays and FS Series AppliancesPaul Barham100% (1)
- Marikina Heights High School 1st Periodical Test in ICT Grade 8Документ3 страницыMarikina Heights High School 1st Periodical Test in ICT Grade 8Princess Torres100% (5)
- Lab 1Документ8 страницLab 1Ihtisham UddinОценок пока нет
- Digital Filters Lab ReportДокумент4 страницыDigital Filters Lab ReportAbhilash OSОценок пока нет
- Computer Assisted Audit Techniques CAATs PDFДокумент2 страницыComputer Assisted Audit Techniques CAATs PDFandika “RIEZ12” riez0% (1)
- 560 - SPL V2 For DevelopersДокумент255 страниц560 - SPL V2 For DevelopersAkash MathurОценок пока нет
- Lab 5Документ14 страницLab 5Barna Valentina GabrielaОценок пока нет
- Manage video surveillance operations over IP networksДокумент4 страницыManage video surveillance operations over IP networksVictor BitarОценок пока нет
- Net MikoДокумент16 страницNet Mikoaurumstar2000Оценок пока нет
- Bitmap Join IndexesДокумент15 страницBitmap Join Indexesrahul_mhatre_26Оценок пока нет
- Comp 2216 AndreaДокумент4 страницыComp 2216 AndreaAndreaОценок пока нет
- Numerical MethodДокумент84 страницыNumerical MethodShamit RathiОценок пока нет
- AngularJS Interview QuestionsДокумент14 страницAngularJS Interview QuestionsMahesh Reddy sayamollaОценок пока нет