Вам также может понравиться
- Comandos PythonДокумент5 страницComandos PythonCosme Dos SantosОценок пока нет
- IntroduçãoДокумент5 страницIntroduçãostu.320202001Оценок пока нет
- Primeiros Comandos MySQLДокумент7 страницPrimeiros Comandos MySQLRafael RabelloОценок пока нет
- PHP - Guia RápidoДокумент22 страницыPHP - Guia RápidoLeo DreezyОценок пока нет
- Fluxograma Linguagem R AtualizadoДокумент7 страницFluxograma Linguagem R AtualizadogameplayanonymousОценок пока нет
- Tryd ScriptДокумент62 страницыTryd ScriptÁtilaОценок пока нет
- Lista 01Документ2 страницыLista 01gecosifiОценок пока нет
- Trabalho de Estrutura de Dados em CДокумент7 страницTrabalho de Estrutura de Dados em CLevi AlvesОценок пока нет
- Custom Iza Ç Ão Data SetДокумент13 страницCustom Iza Ç Ão Data SetEberson PizzaiaОценок пока нет
- Comandos PandasДокумент4 страницыComandos PandasWaterloo Ferreira da SilvaОценок пока нет
- Dicas ProtheusДокумент7 страницDicas Protheusanon_305263336Оценок пока нет
- Slides Unidade1 PDFДокумент38 страницSlides Unidade1 PDFMaomé AmbrósioОценок пока нет
- Apostila MySQL - BasicoДокумент5 страницApostila MySQL - Basicosilviovaiano100% (1)
- LBD - Aula 05 - SQL - Strucure Query LanguageДокумент29 страницLBD - Aula 05 - SQL - Strucure Query LanguageVinicius VidalОценок пока нет
- Aula08-Persistência de DadosДокумент22 страницыAula08-Persistência de DadosJessé BezerraОценок пока нет
- 01 - Introdução A Bibliotecas Python para Análise de Dados - Comandos para Utilização Do PandasPythonДокумент9 страниц01 - Introdução A Bibliotecas Python para Análise de Dados - Comandos para Utilização Do PandasPythonAdriano ViannaОценок пока нет
- Lista ResolvidaДокумент12 страницLista ResolvidaJean C. CaffeoОценок пока нет
- Compilador Perl2exeДокумент9 страницCompilador Perl2exeFrank EinsteinОценок пока нет
- Passo A Passo No SpringBoot Com JPAДокумент6 страницPasso A Passo No SpringBoot Com JPACarol FariasОценок пока нет
- Lista6 - mc102Документ3 страницыLista6 - mc102Nani BarretoОценок пока нет
- Comandos DMLДокумент9 страницComandos DMLWallace AmorimОценок пока нет
- Guia de Referência SQLДокумент24 страницыGuia de Referência SQLmmmatrixОценок пока нет
- 3 - Lista de Exercícios - Estruturas de Dados Filas e PilhasДокумент7 страниц3 - Lista de Exercícios - Estruturas de Dados Filas e PilhasLUCAS ANTONIO LOPES NEVESОценок пока нет
- Exerci CioДокумент38 страницExerci Ciosergiolns100% (1)
- Apostila de SQLServerДокумент37 страницApostila de SQLServerAdriana SabinoОценок пока нет
- Análise de Dados em Python Com Pandas - Ebook - 02.01Документ12 страницAnálise de Dados em Python Com Pandas - Ebook - 02.01klovys santosОценок пока нет
- Protocolo (Exemplo) de Inclusão de Dados No MySQL Via Linguagem "C"Документ4 страницыProtocolo (Exemplo) de Inclusão de Dados No MySQL Via Linguagem "C"Ricardo GuilemondОценок пока нет
- Ponte Iros 1Документ11 страницPonte Iros 1Gilberto TamoyoОценок пока нет
- Gerenciando Banco de Dados Com MySQL 2Документ12 страницGerenciando Banco de Dados Com MySQL 2Fábio MagestОценок пока нет
- Livro - Estruturas de Madeira - Walter PfeilДокумент8 страницLivro - Estruturas de Madeira - Walter PfeilThallyta MottaОценок пока нет
- FWMsExcelEx PDFДокумент16 страницFWMsExcelEx PDFWagner Jose VicentinОценок пока нет
- Banco de Dados I: Prof. Diego BuchingerДокумент88 страницBanco de Dados I: Prof. Diego BuchingerOmar Cunha LopesОценок пока нет
- Tema2 - Sistemas de Gestão de Base de DadosДокумент44 страницыTema2 - Sistemas de Gestão de Base de DadosElton langaОценок пока нет
- Aula C# - Banco de DadosДокумент44 страницыAula C# - Banco de Dadoswendel100% (1)
- LP Aula08Документ36 страницLP Aula08Danilo RochaОценок пока нет
- Comandos e Funções PHP e MySQLДокумент10 страницComandos e Funções PHP e MySQLMateus Macedo Dos AnjosОценок пока нет
- Mapeamento Objeto-Relacional Usando o TMS Aurelius PDFДокумент11 страницMapeamento Objeto-Relacional Usando o TMS Aurelius PDFlauroviniciusОценок пока нет
- ALGORITMOS & ESTRUTURAS de DADOSДокумент62 страницыALGORITMOS & ESTRUTURAS de DADOSDiogoAlcantaraFerreiraОценок пока нет
- Cadastro de Funções ADVPLДокумент4 страницыCadastro de Funções ADVPLlotssudОценок пока нет
- Anotações Curso - C# Programação Orientada A Objetos + ProjetosДокумент51 страницаAnotações Curso - C# Programação Orientada A Objetos + ProjetosNoellen SamaraОценок пока нет
- Anotações Aula 5Документ31 страницаAnotações Aula 5Eduardo AlfaiatariaОценок пока нет
- Lista de Comandos de CMD O Símbolo Del SistemaДокумент7 страницLista de Comandos de CMD O Símbolo Del SistemaEdgar Uriel Sánchez CastañedaОценок пока нет
- Introdução A Classes e Métodos em PythonДокумент44 страницыIntrodução A Classes e Métodos em Pythonwilson.junior870Оценок пока нет
- IntroduçãoДокумент7 страницIntroduçãostu.320202001Оценок пока нет
- Guia Pandas PythonДокумент9 страницGuia Pandas PythonAlefeОценок пока нет
- TLP-12-INFORMÁTICA - Aula 1 - SGBD MySQLДокумент18 страницTLP-12-INFORMÁTICA - Aula 1 - SGBD MySQLmarciosiga3Оценок пока нет
- DDL e DML - LINGUAGEM DE DEFINIÇÃO DE DADOS e LINGUAGEM DE DEFINIÇÃO DE DADOSДокумент10 страницDDL e DML - LINGUAGEM DE DEFINIÇÃO DE DADOS e LINGUAGEM DE DEFINIÇÃO DE DADOSmariaquinoОценок пока нет
- Beginning XML With C# 7 XML Processing and Data Access For C# Developers ( (200-464)Документ265 страницBeginning XML With C# 7 XML Processing and Data Access For C# Developers ( (200-464)Jurdmar Dos Santos JurdmarОценок пока нет
- PostgreSQL - Comandos SQL (Resumido)Документ10 страницPostgreSQL - Comandos SQL (Resumido)alexandrecamelo2009Оценок пока нет
- Linguagem C - MatrizesДокумент15 страницLinguagem C - MatrizesCONTECSULОценок пока нет
- ProgramaçãoДокумент3 страницыProgramaçãojpsantostrajanoОценок пока нет
- Resumo de Comandos Linguagem CДокумент12 страницResumo de Comandos Linguagem Creprega&1279Оценок пока нет
- Eel470 Lista1 NovaДокумент19 страницEel470 Lista1 NovaLuiz CarlosОценок пока нет
- Apresentacao TreportДокумент11 страницApresentacao TreportEdson BorgesОценок пока нет
- Manipulação Base de Dados - ADVPLДокумент23 страницыManipulação Base de Dados - ADVPLMarusan JuniorОценок пока нет
- Vim 010Документ27 страницVim 010Domani PinattiОценок пока нет
- Anotacoes PythonДокумент4 страницыAnotacoes PythonCarlosОценок пока нет
- Fastify - Validation-and-Serialization - MD at Master Fastify - Fastify GitHubДокумент16 страницFastify - Validation-and-Serialization - MD at Master Fastify - Fastify GitHubHenrique LimaОценок пока нет
- PremioДокумент335 страницPremioCosme Dos SantosОценок пока нет
- 02 SlidesMod02Документ72 страницы02 SlidesMod02Cosme Dos SantosОценок пока нет
- Apresentação - Desafios Da Precificação de Riscos em Saúde - Rosana Neves - ANSДокумент28 страницApresentação - Desafios Da Precificação de Riscos em Saúde - Rosana Neves - ANSCosme Dos SantosОценок пока нет
- Apresentação - Tendências Da Regulação de Solvência Na Saúde - Washington Alves - ANSДокумент21 страницаApresentação - Tendências Da Regulação de Solvência Na Saúde - Washington Alves - ANSCosme Dos SantosОценок пока нет
- PremioДокумент335 страницPremioCosme Dos SantosОценок пока нет
- Excel - Macros e Visual BasicДокумент122 страницыExcel - Macros e Visual BasicExcelly100% (7)
- Analise de Dados em Python - Comando - BasicoДокумент4 страницыAnalise de Dados em Python - Comando - BasicoCosme Dos SantosОценок пока нет
- Apostila de Geografia FisicaДокумент22 страницыApostila de Geografia FisicaCassiomichel100% (1)
- A Fiscalização Feita Pela CMV É Realizada PelaДокумент6 страницA Fiscalização Feita Pela CMV É Realizada PelaCosme Dos SantosОценок пока нет
- Pesquisa Ata 5Документ2 страницыPesquisa Ata 5Cosme Dos SantosОценок пока нет
- Python ResumoДокумент10 страницPython ResumoLuísaОценок пока нет
- Conceitos de Linguagens de Programação - Robert W. Sebesta - 9 Edição - Cap.8Документ58 страницConceitos de Linguagens de Programação - Robert W. Sebesta - 9 Edição - Cap.8Evandro LimaОценок пока нет
- Revisar Envio Do Teste ATIVIDADE TELEAULA II - ...Документ3 страницыRevisar Envio Do Teste ATIVIDADE TELEAULA II - ...alivitorОценок пока нет
- Apostila Delphi P1Документ181 страницаApostila Delphi P1Giovanni D' Assumpção MadeiraОценок пока нет
- LCpE ENG03049 V4 4Документ104 страницыLCpE ENG03049 V4 4Ian BauerОценок пока нет
- Matrizes e Vetores em Linguagem CДокумент3 страницыMatrizes e Vetores em Linguagem CSérgio Portari Jr67% (3)
- Tutoriais de Programação GIS Gratuitos - Aprenda Como Codificar - Geografia SIGДокумент7 страницTutoriais de Programação GIS Gratuitos - Aprenda Como Codificar - Geografia SIGgeobiankiniОценок пока нет
- 2.1.4.6 Packet Tracer - Navigating The IOSДокумент5 страниц2.1.4.6 Packet Tracer - Navigating The IOSVeronica RodriguesОценок пока нет
- SEF II - Manual CompletoДокумент133 страницыSEF II - Manual CompletoHitler Antonio de AlmeidaОценок пока нет
- Livro Compiladores PDFДокумент75 страницLivro Compiladores PDFLorraine PepeОценок пока нет
- Linguagem de ProgramacaoДокумент15 страницLinguagem de ProgramacaoJosé Carlos ModaОценок пока нет
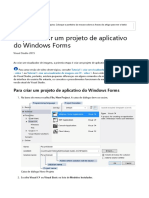
- Etapa 1 - Criar Um Projeto de Aplicativo Do Windows FormsДокумент3 страницыEtapa 1 - Criar Um Projeto de Aplicativo Do Windows FormsMarcilio MeiraОценок пока нет
- Comparação C# e JavaДокумент7 страницComparação C# e JavaWagner Sonoryt TranceОценок пока нет
- Lógica de Programação 2Документ4 страницыLógica de Programação 2Delvair vieira da silvaОценок пока нет
- Elevador Com Pic 18f4550Документ37 страницElevador Com Pic 18f4550Jovina NascimentoОценок пока нет
- Livro PDFДокумент248 страницLivro PDFRafael Coelho100% (4)
- Algoritmos e Estruturas de Dados II - Apostila IДокумент30 страницAlgoritmos e Estruturas de Dados II - Apostila IribuankaОценок пока нет
- Linguagem C C v5Документ148 страницLinguagem C C v5Thamiris OscarinoОценок пока нет
- Respostas Dos ExercíciosДокумент34 страницыRespostas Dos ExercíciosAnizio Peres da SilvaОценок пока нет
- Aula 3 - ARA0017 - Introdu o Linguagem em CДокумент72 страницыAula 3 - ARA0017 - Introdu o Linguagem em CUm cara sem nada pra fazerОценок пока нет
- Curso Completo de Java PDFДокумент170 страницCurso Completo de Java PDFTiago100% (1)
- Simulado - Algoritmos e Complexidade1Документ6 страницSimulado - Algoritmos e Complexidade1Targyson Silva100% (1)
- Projetec DF - Como Atualizar Os Preços Da Base de Dados SINAPI Da Caixa Econômica Federal PDFДокумент8 страницProjetec DF - Como Atualizar Os Preços Da Base de Dados SINAPI Da Caixa Econômica Federal PDFPlinio Sergio RodriguesОценок пока нет
- Microcontroladores Aula 2Документ23 страницыMicrocontroladores Aula 2pjqt1234Оценок пока нет
- Análise de Pontos de FunçãoДокумент100 страницAnálise de Pontos de FunçãoLeo.msОценок пока нет
- Começando A Programar em CДокумент19 страницComeçando A Programar em CassishpОценок пока нет
- Lista Exercicio 05Документ3 страницыLista Exercicio 05Ruth Souza BritoОценок пока нет
- Teste 222Документ3 страницыTeste 222wesleybsОценок пока нет
- Tutorial de Winsocket em CДокумент4 страницыTutorial de Winsocket em Cgui.srvОценок пока нет
- Aula 6-Estruturas de RepetiçãoДокумент24 страницыAula 6-Estruturas de RepetiçãoAdemir NetoОценок пока нет