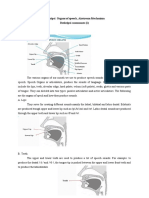
Вам также может понравиться
- Consonant SoundsДокумент8 страницConsonant SoundsKhairul Nizam HamzahОценок пока нет
- Ibn Tofail University LevelДокумент23 страницыIbn Tofail University LevelImad Es SaouabiОценок пока нет
- ngữ âm vị họcДокумент5 страницngữ âm vị họcThảo Min'ssОценок пока нет
- Topic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsДокумент8 страницTopic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsLaura Irina Lara SánchezОценок пока нет
- Assignment 2, Manners of ArticulationДокумент5 страницAssignment 2, Manners of ArticulationChris DavisОценок пока нет
- Sounds ClassificationДокумент4 страницыSounds ClassificationSantiago Etcheverry FeelyОценок пока нет
- Chapter 4 & 5 - Special TopicsДокумент15 страницChapter 4 & 5 - Special TopicsBearish PaleroОценок пока нет
- English ConsonantsДокумент3 страницыEnglish ConsonantsKashif Farid0% (1)
- The Distinctive CompositionДокумент5 страницThe Distinctive Compositionsofija manaievaОценок пока нет
- English ConsonantsДокумент28 страницEnglish ConsonantsIzzati AzmanОценок пока нет
- Consonants and Vowels Distinguish Between Consonants and Vowels and Describe How Consonants Are ClassifiedДокумент3 страницыConsonants and Vowels Distinguish Between Consonants and Vowels and Describe How Consonants Are ClassifiedThiên ThanhОценок пока нет
- Speech and Theater ExamДокумент22 страницыSpeech and Theater ExamCres Jules ArdoОценок пока нет
- Articulatory Phonetics: 1) VoiceДокумент3 страницыArticulatory Phonetics: 1) VoiceDorepeОценок пока нет
- Paper 6 (Descriptive Linguistics) DiphthongsДокумент5 страницPaper 6 (Descriptive Linguistics) DiphthongsZIA UR REHMANОценок пока нет
- Phonetics: The Sounds of LanguageДокумент42 страницыPhonetics: The Sounds of LanguageZahwa Khotrunnada JannahОценок пока нет
- Manner of Articulation: ExercisesДокумент1 страницаManner of Articulation: ExercisesHomero Apeña CarranzaОценок пока нет
- Phonetics: The Sounds of Languag EДокумент35 страницPhonetics: The Sounds of Languag Edini khanafiОценок пока нет
- Organs of SpeechДокумент5 страницOrgans of SpeechMohd Shahrin BasniОценок пока нет
- Phonetic and PhonologyДокумент8 страницPhonetic and PhonologyIzha AshariОценок пока нет
- CONSONANTAL SOUNDS Lez 7Документ7 страницCONSONANTAL SOUNDS Lez 7silviasОценок пока нет
- GHL #02Документ8 страницGHL #02esha khanОценок пока нет
- Nama: Muhammad Irwan Phonology NIM: 17111024210002Документ5 страницNama: Muhammad Irwan Phonology NIM: 17111024210002Roby Pandu PradanaОценок пока нет
- Articulatory PhoneticsДокумент3 страницыArticulatory PhoneticszelindaaОценок пока нет
- Phonetics and PhonologyДокумент22 страницыPhonetics and PhonologyYulia DeaОценок пока нет
- النظام الصوتي المرحلة الاولى الملف الكاملДокумент48 страницالنظام الصوتي المرحلة الاولى الملف الكاملjyx9sbghgvОценок пока нет
- A Course in Phonetics by Peter Ladefoged PDFДокумент15 страницA Course in Phonetics by Peter Ladefoged PDFPralay SutradharОценок пока нет
- Speech OrgansДокумент5 страницSpeech OrgansprivateceeОценок пока нет
- Ingilis Dili MühazirəДокумент567 страницIngilis Dili Mühazirəbagirovanar26Оценок пока нет
- Ling Ass 1Документ5 страницLing Ass 1Xiaoyu LiuОценок пока нет
- Uas Alrino Ode MasimuДокумент10 страницUas Alrino Ode MasimuArif FlouncxОценок пока нет
- Types of Phonemes Definitions PDFДокумент3 страницыTypes of Phonemes Definitions PDFLovely FinuliarОценок пока нет
- Questions For RevisionДокумент12 страницQuestions For RevisionChi ChiiОценок пока нет
- English Phonetics Lesson 3Документ14 страницEnglish Phonetics Lesson 3Doaa Fat-hyОценок пока нет
- Phonetics NotesДокумент5 страницPhonetics NotesYaya CasablancaОценок пока нет
- Lesson 4 Consonants1Документ8 страницLesson 4 Consonants1Lounis MustaphaОценок пока нет
- GROUP 4 - The Physiology Aspect of Language Phonetics and PhonologyДокумент28 страницGROUP 4 - The Physiology Aspect of Language Phonetics and PhonologyDavina AzhaarОценок пока нет
- English Phonetics and PhonologyДокумент31 страницаEnglish Phonetics and PhonologyIzzati AzmanОценок пока нет
- Hugo, Avegail P. Bsed-English 2-A1: Place of ArticulationДокумент5 страницHugo, Avegail P. Bsed-English 2-A1: Place of ArticulationVan DuranОценок пока нет
- Summary GimsonДокумент6 страницSummary GimsonsgambelluribeiroОценок пока нет
- Organ of SpeechДокумент10 страницOrgan of SpeechWinda Rizki Listia DamanikОценок пока нет
- Phonetic and PhonologyДокумент57 страницPhonetic and PhonologyjimmyОценок пока нет
- ENGLISH PHONOLOGY Materi 2Документ12 страницENGLISH PHONOLOGY Materi 2Agnes Nopita WidianiОценок пока нет
- Phonology SeptemberДокумент10 страницPhonology SeptemberaladeobashinaОценок пока нет
- Speech Organs Produce The Many Sounds Needed For LanguageДокумент7 страницSpeech Organs Produce The Many Sounds Needed For LanguageSherwin Ryan AvilaОценок пока нет
- Consonants of English: Presented by Marwa Mahmoud Abd El FattahДокумент8 страницConsonants of English: Presented by Marwa Mahmoud Abd El FattahSamar Saad100% (2)
- Human Speech OrgansДокумент5 страницHuman Speech OrgansLouise anasthasya altheaОценок пока нет
- Arif Hidayat English PhonologyДокумент54 страницыArif Hidayat English PhonologyArif FlouncxОценок пока нет
- Introduction To Linguistics: Phonetics: July 27, 2017Документ17 страницIntroduction To Linguistics: Phonetics: July 27, 2017zyanmktsdОценок пока нет
- Phonetics & Spoken EnglishДокумент12 страницPhonetics & Spoken EnglishCharanjit SinghОценок пока нет
- Nama: Yudha Septa Dias P NIM: 12203193120 Mata Kuliah: English Phonology Kelas: Tbi 1BДокумент9 страницNama: Yudha Septa Dias P NIM: 12203193120 Mata Kuliah: English Phonology Kelas: Tbi 1BInayah RizkyОценок пока нет
- Phonetics 3Документ13 страницPhonetics 3Lina MalekОценок пока нет
- Syllabification RulesДокумент9 страницSyllabification RulesSusarla SuryaОценок пока нет
- Chap.1 Production of ObstruentsДокумент41 страницаChap.1 Production of ObstruentsSaif Ur RahmanОценок пока нет
- PHONETICS: The Sounds of LanguageДокумент5 страницPHONETICS: The Sounds of LanguageMayMay Serpajuan-SablanОценок пока нет
- Place and Manner of Articulation PresentationДокумент14 страницPlace and Manner of Articulation PresentationBettina GomezОценок пока нет
- Phonetics and Phonology at A Glance 1: Articulatory PhoneticsДокумент6 страницPhonetics and Phonology at A Glance 1: Articulatory PhoneticsIva BasarОценок пока нет
- 2 PhonologyДокумент10 страниц2 PhonologyNaoufal FouadОценок пока нет
- English Vowels (Phonology Group Presentation) : PaperДокумент11 страницEnglish Vowels (Phonology Group Presentation) : PaperMega WijayaОценок пока нет
- Phonetic Handout 1Документ14 страницPhonetic Handout 1Wisten MárquezОценок пока нет
- The Pronunciation of English: A Reference and Practice BookОт EverandThe Pronunciation of English: A Reference and Practice BookРейтинг: 5 из 5 звезд5/5 (1)
- English Spelling Rules and Common MistakesДокумент5 страницEnglish Spelling Rules and Common MistakesPaul100% (1)
- R H Robins A Short History of Linguistic-Páginas-204-239 RecognizedДокумент36 страницR H Robins A Short History of Linguistic-Páginas-204-239 RecognizedalineОценок пока нет
- Revista RomanoslavicaДокумент207 страницRevista RomanoslavicaPrislopean gigelОценок пока нет
- IPA 1short VowelДокумент169 страницIPA 1short VowelJuliet ZhuОценок пока нет
- An 1 Sem 1 A Short Introduction To Phonetics and PhonologyДокумент153 страницыAn 1 Sem 1 A Short Introduction To Phonetics and PhonologyUKASY8100% (3)
- Pronunciation of Norwegian PDFДокумент233 страницыPronunciation of Norwegian PDFWolfzeit KateОценок пока нет
- Linguistics MonographДокумент51 страницаLinguistics MonographIrshad QazikhilОценок пока нет
- Makalah B.inggris Kelompok 5Документ9 страницMakalah B.inggris Kelompok 5antoniОценок пока нет
- CVC PatternДокумент35 страницCVC PatternLaidelyn Magboo Almonguera100% (1)
- Phonetic Alphabet Examples and Practice 2023Документ25 страницPhonetic Alphabet Examples and Practice 2023zoni alpdoОценок пока нет
- LPE2403 SDL Worksheet 1: English Phonetics: Answer All The Questions BelowДокумент8 страницLPE2403 SDL Worksheet 1: English Phonetics: Answer All The Questions BelowMUHAMMAD AMIRUL HAFIZ BIN AHMAD / UPMОценок пока нет
- George Grigore Gabriel Bițună. Common Features of North Mesopotamian Arabic Dialects Spoken in Turkey (Șirnak, Mardin, Siirt)Документ11 страницGeorge Grigore Gabriel Bițună. Common Features of North Mesopotamian Arabic Dialects Spoken in Turkey (Șirnak, Mardin, Siirt)RomarОценок пока нет
- Branches of LinguisticsДокумент16 страницBranches of LinguisticsMisaki BLОценок пока нет
- 7 FootДокумент8 страниц7 FootTaweem RouhiОценок пока нет
- 2024 - W2 - Phonetics and Phonology - StudentsДокумент24 страницы2024 - W2 - Phonetics and Phonology - Studentskienphu111003Оценок пока нет
- 3028-Article Text-5853-1-10-20201217Документ15 страниц3028-Article Text-5853-1-10-20201217Hammouddou ElhoucineОценок пока нет
- The Role of Phonemic Awareness in Learning To Read: Linnea C. Ehri and Simone R. NunesДокумент30 страницThe Role of Phonemic Awareness in Learning To Read: Linnea C. Ehri and Simone R. NunesLuthyGay VillamorОценок пока нет
- Jadi Buti Bazar Final IssueДокумент8 страницJadi Buti Bazar Final IssueJoseph EbertОценок пока нет
- Lesson2 SV WorkbookДокумент35 страницLesson2 SV WorkbookErik JimlopОценок пока нет
- Grammar Notes Lesson 5Документ7 страницGrammar Notes Lesson 5Rasec RodriguezОценок пока нет
- Bennett - Comparative Semitc Linguistics - A ManualДокумент284 страницыBennett - Comparative Semitc Linguistics - A ManualdwilmsenОценок пока нет
- Babatsouli (2019) A Phonological Assessment Test For Child GreekДокумент28 страницBabatsouli (2019) A Phonological Assessment Test For Child GreekElena BabatsouliОценок пока нет
- Consonant Sounds of American EnglishДокумент1 страницаConsonant Sounds of American EnglishRenataОценок пока нет
- 03 HebrewsДокумент12 страниц03 HebrewsLuis MelendezОценок пока нет
- IntonationДокумент8 страницIntonationWendell EspinalОценок пока нет
- 4 - Tongue Twister Initial Sounds (汉语声母与声调 - 绕口令)Документ31 страница4 - Tongue Twister Initial Sounds (汉语声母与声调 - 绕口令)Jaime SiaОценок пока нет
- Chapter 5Документ7 страницChapter 5HimaAboElmajdОценок пока нет
- English ProjectДокумент6 страницEnglish ProjectSiddhi WarkhadeОценок пока нет
- Hebrew Full VowelsДокумент1 страницаHebrew Full VowelsLuis Bravo100% (1)
- Write The Following Words in Phonetic SymbolsДокумент2 страницыWrite The Following Words in Phonetic Symbolscris.0690.23Оценок пока нет