Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Training Manual A 319/320/321: ATA 30 Ice and Rain ProtectionДокумент46 страницTraining Manual A 319/320/321: ATA 30 Ice and Rain ProtectionHansraj Kayda100% (1)
- WCE2017 pp211-214 PDFДокумент4 страницыWCE2017 pp211-214 PDFVijaya Prakash RajanalaОценок пока нет
- Data Mining: Concepts and Techniques: - Chapter 10Документ50 страницData Mining: Concepts and Techniques: - Chapter 10Vijaya Prakash RajanalaОценок пока нет
- SearchingДокумент24 страницыSearchingVijaya Prakash RajanalaОценок пока нет
- SearchingДокумент24 страницыSearchingVijaya Prakash RajanalaОценок пока нет
- Graph Coloring - Wikipedia, The Free EncyclopediaДокумент17 страницGraph Coloring - Wikipedia, The Free EncyclopediaVijaya Prakash RajanalaОценок пока нет
- CoCubes The GenZ Employability Report v3Документ30 страницCoCubes The GenZ Employability Report v3Vijaya Prakash Rajanala100% (1)
- Why We Model?: Keng Siau University of Nebraska-LincolnДокумент8 страницWhy We Model?: Keng Siau University of Nebraska-LincolnVijaya Prakash RajanalaОценок пока нет
- T & PДокумент7 страницT & PVijaya Prakash RajanalaОценок пока нет
- Computer - Hardware: Arithmetic and Logic Unit Micro ProcessorДокумент24 страницыComputer - Hardware: Arithmetic and Logic Unit Micro Processorkris_gn54Оценок пока нет
- Aata 20110810Документ438 страницAata 20110810Tram VoОценок пока нет
- CH 22 - Problem Spaces and SearchДокумент18 страницCH 22 - Problem Spaces and SearchVijaya Prakash RajanalaОценок пока нет
- AI Chapter1Документ39 страницAI Chapter1Rahul RahulОценок пока нет
- Unit 1 JWFILES PDFДокумент52 страницыUnit 1 JWFILES PDFsrilakshmisiriОценок пока нет
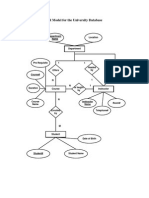
- ER Model For The University Database: Location Department NameДокумент1 страницаER Model For The University Database: Location Department NameVijaya Prakash RajanalaОценок пока нет
- NLP Starting PagesДокумент7 страницNLP Starting PagesVijaya Prakash RajanalaОценок пока нет
- JournalsДокумент1 страницаJournalsVijaya Prakash RajanalaОценок пока нет
- Unit 1 JWFILES PDFДокумент52 страницыUnit 1 JWFILES PDFsrilakshmisiriОценок пока нет
- CPDSДокумент63 страницыCPDSVijaya Prakash RajanalaОценок пока нет
- SQL Interview QuestionsДокумент2 страницыSQL Interview QuestionscourpediaОценок пока нет
- Experiment: Measurement of Power in Three Phase Balanced LoadДокумент2 страницыExperiment: Measurement of Power in Three Phase Balanced LoadTripti GuptaОценок пока нет
- Exploring Linux Build Systems - Buildroot Lab ManualДокумент38 страницExploring Linux Build Systems - Buildroot Lab Manualhamzamehboob103Оценок пока нет
- ET4117 Electrical Machines and Drives Lecture5Документ31 страницаET4117 Electrical Machines and Drives Lecture5farhan beighОценок пока нет
- Java MCQДокумент35 страницJava MCQSumit Tembhare100% (2)
- Manual Masina IndesitДокумент72 страницыManual Masina Indesitdangb84roОценок пока нет
- Busiess Analytics Data Mining Lecture 7Документ37 страницBusiess Analytics Data Mining Lecture 7utkarsh bhargavaОценок пока нет
- GOC & EAS CPP-II - PMDДокумент14 страницGOC & EAS CPP-II - PMDVansh sareenОценок пока нет
- Optimization Technique Group 1Документ60 страницOptimization Technique Group 1jmlafortezaОценок пока нет
- Paper Test For General PhysicsДокумент2 страницыPaper Test For General PhysicsJerrySemuelОценок пока нет
- A Study of Metro Manilas Public Transportation SeДокумент19 страницA Study of Metro Manilas Public Transportation Segundranken08Оценок пока нет
- Kroenke Dbp12e Appendix CДокумент13 страницKroenke Dbp12e Appendix CCarlos Alberto LeònОценок пока нет
- All About FTP Must ReadДокумент7 страницAll About FTP Must ReadPINOY EUTSECОценок пока нет
- Practical Exercise 02Документ17 страницPractical Exercise 02FeRro ReniОценок пока нет
- 2021 Nov HG 1st PBДокумент10 страниц2021 Nov HG 1st PBGlaiza MarieОценок пока нет
- Norma JIC 37Документ36 страницNorma JIC 37guguimirandaОценок пока нет
- Multilevel Converters - Dual Two-Level Inverter SchemeДокумент226 страницMultilevel Converters - Dual Two-Level Inverter Schemejuancho2222Оценок пока нет
- Georeferencing and Digitization in QGISДокумент82 страницыGeoreferencing and Digitization in QGISThanosОценок пока нет
- Babikian Et Al Historical Fuel Efficiencies 2002Документ12 страницBabikian Et Al Historical Fuel Efficiencies 2002irockdudeОценок пока нет
- Pronouns - Maurice PDFДокумент2 страницыPronouns - Maurice PDFSCRIBDBUUОценок пока нет
- Calculating Species Importance ValuesДокумент3 страницыCalculating Species Importance Valuesabraha gebruОценок пока нет
- Introduction To Fission and FusionДокумент19 страницIntroduction To Fission and FusionZubair Hassan100% (1)
- Analog Communications-Notes PDFДокумент110 страницAnalog Communications-Notes PDFjyothimunjam100% (1)
- A Simple Favor 2018 720p BluRay x264 - (YTS AM) mp4Документ2 страницыA Simple Favor 2018 720p BluRay x264 - (YTS AM) mp4Dewi SartikaОценок пока нет
- AN000042 SERCOS Troubleshooting Guide - ApplicationNote - En-Us - Revision1Документ14 страницAN000042 SERCOS Troubleshooting Guide - ApplicationNote - En-Us - Revision1uongquocvuОценок пока нет
- PumpsДокумент8 страницPumpskannagi198Оценок пока нет
- Power Amplifiers: Ranjith Office Level 4 - Building 193 - EEE BuildingДокумент19 страницPower Amplifiers: Ranjith Office Level 4 - Building 193 - EEE BuildingArambya Ankit KallurayaОценок пока нет
- Riedel Artist USДокумент22 страницыRiedel Artist UScliffforscribdОценок пока нет
- Branches of Science and Sub SciencesДокумент5 страницBranches of Science and Sub SciencesSha BtstaОценок пока нет