Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- InsuranceДокумент2 страницыInsuranceAbhishekОценок пока нет
- HiveДокумент13 страницHiveAbhishekОценок пока нет
- InsuranceДокумент2 страницыInsuranceAbhishekОценок пока нет
- Porter's Five ForcesДокумент32 страницыPorter's Five Forceslaucapela100% (1)
- Strategy Cheat SheetДокумент2 страницыStrategy Cheat SheetAbhishekОценок пока нет
- Transportation ModelДокумент41 страницаTransportation ModelAbhishek0% (1)
- NCFM TestlocationsДокумент12 страницNCFM TestlocationsAbhishekОценок пока нет
- Hypothesis Testing - UT Austin PDFДокумент23 страницыHypothesis Testing - UT Austin PDFArpit AroraОценок пока нет
- FRA Assignment 4Документ6 страницFRA Assignment 4AbhishekОценок пока нет
- The Assignment Problem The Hungarian MethodДокумент31 страницаThe Assignment Problem The Hungarian MethodYinghui LiuОценок пока нет
- Microeconomics 8th Edition Pindyck Solutions Chapter 4: Chapter 4 As With Ease As Evaluation Them Wherever You Are NowДокумент1 страницаMicroeconomics 8th Edition Pindyck Solutions Chapter 4: Chapter 4 As With Ease As Evaluation Them Wherever You Are NowAbhishekОценок пока нет
- Operations Research g1Документ7 страницOperations Research g1AbhishekОценок пока нет
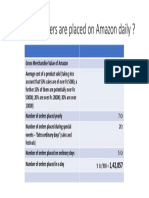
- How Many Orders Are Placed On Amazon DailyДокумент1 страницаHow Many Orders Are Placed On Amazon DailyAbhishekОценок пока нет
- FRA Assignment 4Документ6 страницFRA Assignment 4AbhishekОценок пока нет
- FRA Assignment 4Документ6 страницFRA Assignment 4AbhishekОценок пока нет
- Case Study Notes - Tylenol's ReboundДокумент5 страницCase Study Notes - Tylenol's ReboundAbhishekОценок пока нет
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Arma 1Документ4 страницыArma 1Lâm Anh VũОценок пока нет
- EFA GuideДокумент28 страницEFA GuideSoni RathiОценок пока нет
- Bluman Stats Brief 6e CH01 (Jang)Документ23 страницыBluman Stats Brief 6e CH01 (Jang)Das ChimeraОценок пока нет
- What's New in Econometrics? Difference-in-Differences EstimationДокумент31 страницаWhat's New in Econometrics? Difference-in-Differences EstimationBrian T. KimОценок пока нет
- Lampiran 14: Uji Normalitas Data: One-Sample Kolmogorov-Smirnov TestДокумент3 страницыLampiran 14: Uji Normalitas Data: One-Sample Kolmogorov-Smirnov Testhijir simbitiОценок пока нет
- Mini DictionaryДокумент2 страницыMini DictionaryJames Clarenze VarronОценок пока нет
- Role of Value Added Tax (VAT) On The Economic Growth of BangladeshДокумент17 страницRole of Value Added Tax (VAT) On The Economic Growth of Bangladeshmirza nokibОценок пока нет
- Lme4 - MorfometriaДокумент113 страницLme4 - MorfometriaMónica HernándezОценок пока нет
- New Global Vision College: Addis Ababa CampusДокумент5 страницNew Global Vision College: Addis Ababa CampusMarkonal MulukenОценок пока нет
- True ExperimentДокумент8 страницTrue Experimentkeira nizaОценок пока нет
- DOE - Inner-Outer ArraysДокумент13 страницDOE - Inner-Outer Arrayschit catОценок пока нет
- Question Bank StatisticsДокумент20 страницQuestion Bank StatisticsBishal DasОценок пока нет
- Statistics 5.4Документ12 страницStatistics 5.4Ysabel Grace BelenОценок пока нет
- Handnote Chapter 4 Measures of DispersioДокумент45 страницHandnote Chapter 4 Measures of DispersioKim NamjoonneОценок пока нет
- ClassworkДокумент2 страницыClassworkambrosialnectarОценок пока нет
- Output Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiДокумент5 страницOutput Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiDetdet343Оценок пока нет
- ECO242Документ1 страницаECO242cibeneche07Оценок пока нет
- The University of NottinghamДокумент6 страницThe University of Nottinghammeettoavi059Оценок пока нет
- How To Calculate OutliersДокумент7 страницHow To Calculate OutliersCelina BorilloОценок пока нет
- Week 2 TliДокумент11 страницWeek 2 TliGracia Mae GaciasОценок пока нет
- Lecture 9 Hypothesis TestingДокумент31 страницаLecture 9 Hypothesis Testingaashna.singh3008Оценок пока нет
- Proposed New Syllabus For B. Com From The Academic Session 2020 - 21Документ4 страницыProposed New Syllabus For B. Com From The Academic Session 2020 - 21DEEPAK DINESH VANSUTREОценок пока нет
- 11.hypothesis Test For Means - BiostatisticsДокумент2 страницы11.hypothesis Test For Means - BiostatisticsRein BulahaoОценок пока нет
- Dependent T Test Paired SampleДокумент2 страницыDependent T Test Paired SampleShuzumiОценок пока нет
- Tugas ANOVA 1 Faktor 2 TMMA 2023 - 085022Документ5 страницTugas ANOVA 1 Faktor 2 TMMA 2023 - 085022Luthfi Maulana AlviantoОценок пока нет
- Correlation and Hypothesis TestingДокумент39 страницCorrelation and Hypothesis TestingBhavesh ChauhanОценок пока нет
- Assignment Question Bum2413 Sem 2 2223Документ8 страницAssignment Question Bum2413 Sem 2 2223Hatta RahmanОценок пока нет
- JurnalДокумент16 страницJurnalRizky KurniaОценок пока нет
- Marketing Research: Analysis of Variance and CovarianceДокумент17 страницMarketing Research: Analysis of Variance and Covariancesamiha jahanОценок пока нет
- An Introduction To Anatomical ROI-based fMRI Classification AnalysisДокумент12 страницAn Introduction To Anatomical ROI-based fMRI Classification AnalysisFridRachmanОценок пока нет