Вам также может понравиться
- Not For Sale: (Grade 8 Regular)Документ148 страницNot For Sale: (Grade 8 Regular)Nathaniel MungcalОценок пока нет
- Telecom Based Inventory ManagementДокумент7 страницTelecom Based Inventory ManagementEly DalimanОценок пока нет
- Connected Vehicle Market - 01 Mar 2021Документ15 страницConnected Vehicle Market - 01 Mar 2021SUBHADEEP CHAKRABORTYОценок пока нет
- 10 Coding Principles PDFДокумент6 страниц10 Coding Principles PDFnarendra_mahajanОценок пока нет
- ML PDFДокумент237 страницML PDFKomi David ABOTSITSE100% (1)
- SARAL - Terms and ConditionsДокумент5 страницSARAL - Terms and ConditionsOneindiaОценок пока нет
- Programming On Parallel MachinesДокумент344 страницыProgramming On Parallel MachinesDlu114100% (1)
- Shiny Application - From Package Development To Server DeploymentДокумент34 страницыShiny Application - From Package Development To Server DeploymentnexrothОценок пока нет
- Weather Forecasting and Prediction Using Hybrid C5.0Документ14 страницWeather Forecasting and Prediction Using Hybrid C5.0Logan Paul100% (1)
- Machine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewДокумент6 страницMachine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewIJRASETPublications100% (1)
- Machine Learning Methods To Weather Forecasting To Predict Apparent TemperatureДокумент11 страницMachine Learning Methods To Weather Forecasting To Predict Apparent TemperatureIJRASETPublications100% (1)
- AWS Serverless MicroservicesДокумент264 страницыAWS Serverless Microservicesluis eduardo melendez campisОценок пока нет
- Financial Analytics With PythonДокумент40 страницFinancial Analytics With PythonHarshit Singh100% (1)
- Blank SGVU Assignment Response SheetДокумент16 страницBlank SGVU Assignment Response SheetSamirHayatKhanОценок пока нет
- AdaBoost Classifier in Python (Article) - DataCampДокумент9 страницAdaBoost Classifier in Python (Article) - DataCampenghoss77100% (1)
- Ensemble Learning: Wisdom of The CrowdДокумент12 страницEnsemble Learning: Wisdom of The CrowdRavi Verma100% (1)
- Telling Stories With DataДокумент1 страницаTelling Stories With DataAhmad Ibrahim Makki Maruf100% (1)
- Scikit-Learn-Exercises - Jupyter NotebookДокумент28 страницScikit-Learn-Exercises - Jupyter NotebookSharil nadzimuddin johari100% (1)
- 8 Best Python Cheat Sheets For Beginners and Intermediate LearnersДокумент13 страниц8 Best Python Cheat Sheets For Beginners and Intermediate LearnersJoseph Jung100% (1)
- Ensemble Learning MethodsДокумент24 страницыEnsemble Learning Methodskhatri81100% (1)
- K Mean Clustering 1Документ12 страницK Mean Clustering 1HykaVirtasari100% (1)
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Документ11 страницML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Introduction To Scikit LearnДокумент108 страницIntroduction To Scikit LearnRaiyan Zannat100% (1)
- PublishedPaperNo.8 2022Документ14 страницPublishedPaperNo.8 2022Sushmitha Thulasimani100% (1)
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionДокумент22 страницыMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceДокумент28 страницSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- ML0101EN Clas Logistic Reg Churn Py v1Документ13 страницML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- ML Module 5 2022 PDFДокумент31 страницаML Module 5 2022 PDFjanuary100% (1)
- Weather Forecasting Application Using Python: A Machine Learning ApproachДокумент10 страницWeather Forecasting Application Using Python: A Machine Learning ApproachLoser To Winner100% (1)
- Classification Models: An Overview of Ensemble Learning TechniquesДокумент40 страницClassification Models: An Overview of Ensemble Learning TechniquesFriday Jones100% (1)
- To Pattern Recognition: CSE555, Fall 2021 Chapter 1, DHSДокумент39 страницTo Pattern Recognition: CSE555, Fall 2021 Chapter 1, DHSNikhil Gupta100% (1)
- Weather Forecasting BasepaperДокумент14 страницWeather Forecasting Basepapersrihemabiccavolu100% (1)
- Logistic RegressionДокумент10 страницLogistic RegressionChichi Jnr100% (1)
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryДокумент16 страницMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- D3.js Tutorial: Download The Code Examples!Документ110 страницD3.js Tutorial: Download The Code Examples!Christopher RiceОценок пока нет
- Stock Data Pivoted into DataFrames for AnalysisДокумент4 страницыStock Data Pivoted into DataFrames for Analysisyogesh patil100% (1)
- XGBoost for Online Payment Fraud DetectionДокумент8 страницXGBoost for Online Payment Fraud DetectionMaliha Mirza100% (1)
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsДокумент38 страницC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Data Science - Unit IIДокумент173 страницыData Science - Unit IIDHEEVIKA SURESH100% (1)
- Data ScienceДокумент38 страницData ScienceSiwo Honkai100% (1)
- XG Boost PDFДокумент3 страницыXG Boost PDFIVAN ALVARO TORRES ROBLES100% (1)
- Basic Ensemble Learning Algorithms ExplainedДокумент8 страницBasic Ensemble Learning Algorithms ExplainedLuciano100% (1)
- Scikit - Notes MLДокумент12 страницScikit - Notes MLVulli Leela Venkata Phanindra100% (1)
- Teleco Cutomer ChurnДокумент5 страницTeleco Cutomer ChurnMCV101100% (1)
- ML Unit1 PDFДокумент36 страницML Unit1 PDFMohanraj Pramanathan100% (1)
- ML0101EN Clus K Means Customer Seg Py v1Документ8 страницML0101EN Clus K Means Customer Seg Py v1Rajat Solanki100% (1)
- Lec 18Документ34 страницыLec 18ABHIRAJ E100% (1)
- Fnal+Report Advance+StatisticsДокумент44 страницыFnal+Report Advance+StatisticsPranav Viswanathan100% (1)
- Saurabh Verma 9919102005Документ11 страницSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Ensemble Learning Combines ModelsДокумент57 страницEnsemble Learning Combines ModelsYASH GAIKWAD100% (1)
- Project 1 - Radio Link Failure PredictionДокумент8 страницProject 1 - Radio Link Failure PredictionAhmed Belhadj100% (1)
- Chapter 3Документ17 страницChapter 3Rajachandra Voodiga100% (1)
- Data Analytics Time Table V2Документ6 страницData Analytics Time Table V2Hussain100% (1)
- Peer Review Assignment 4: InstructionsДокумент17 страницPeer Review Assignment 4: Instructionshamza omar100% (1)
- A) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsДокумент6 страницA) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsHassan Saddiqui100% (1)
- SQL Cheat SheetДокумент44 страницыSQL Cheat Sheetviany lepro100% (1)
- Heart Disease Prediction Using Machine Learning ModelsДокумент73 страницыHeart Disease Prediction Using Machine Learning Modelsaditya b100% (1)
- EXTRACTING KNOWLEDGE FROM DATA WITH DATAMINING TECHNIQUESДокумент28 страницEXTRACTING KNOWLEDGE FROM DATA WITH DATAMINING TECHNIQUESvineesha28100% (1)
- Outliers, Hypothesis and Natural Language ProcessingДокумент7 страницOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- Outlines: Statements of Problems Objectives Bagging Random Forest Boosting AdaboostДокумент14 страницOutlines: Statements of Problems Objectives Bagging Random Forest Boosting Adaboostendale100% (1)
- BookДокумент480 страницBookNaorem Sing100% (1)
- 3 Confussion Matrix Hasil Modelling OKДокумент8 страниц3 Confussion Matrix Hasil Modelling OKArman Maulana Muhtar100% (1)
- ML Lect1Документ51 страницаML Lect1physics lover100% (1)
- Applied Data Science Camp - InfoДокумент12 страницApplied Data Science Camp - InfoAdnan100% (1)
- Policy PDFДокумент3 страницыPolicy PDFAnurag SinghОценок пока нет
- Garima Resume1 2Документ2 страницыGarima Resume1 2Anurag SinghОценок пока нет
- Policy PDFДокумент3 страницыPolicy PDFAnurag SinghОценок пока нет
- Resume FormatДокумент4 страницыResume FormatAnurag SinghОценок пока нет
- Acknowledgement SlipДокумент1 страницаAcknowledgement SlipAnurag SinghОценок пока нет
- Valid ID & address proof documentsДокумент2 страницыValid ID & address proof documentsAnurag SinghОценок пока нет
- PDFДокумент2 страницыPDFAnurag SinghОценок пока нет
- Sbi New Dispute FormДокумент2 страницыSbi New Dispute FormAnurag SinghОценок пока нет
- Resume FormatДокумент4 страницыResume FormatAnurag SinghОценок пока нет
- Lec 5Документ40 страницLec 5Bilal RasoolОценок пока нет
- Mobile Computing Less1Документ74 страницыMobile Computing Less1rtyujkОценок пока нет
- ENOVIA Program Central Administrator's Guide (V6R2011)Документ136 страницENOVIA Program Central Administrator's Guide (V6R2011)蔡佳純Оценок пока нет
- Essential Skills Map for Digital Transformation TeamsДокумент7 страницEssential Skills Map for Digital Transformation Teamsarum2008100% (1)
- Resell Opportunities in Oracle Partnernetwork: Products Available For Partners To ResellДокумент1 страницаResell Opportunities in Oracle Partnernetwork: Products Available For Partners To ResellJoseph JosefОценок пока нет
- MEAN Ebook - CodeWithRandomДокумент524 страницыMEAN Ebook - CodeWithRandomweshine.dataentry14Оценок пока нет
- Third Year Sixth Semester CS6601 Distributed System 2 Mark With AnswerДокумент25 страницThird Year Sixth Semester CS6601 Distributed System 2 Mark With AnswerPRIYA RAJI86% (7)
- Computer Crime Final Assessment Test AnswersДокумент4 страницыComputer Crime Final Assessment Test AnswersOmar HaibaОценок пока нет
- File Structure Lab Program Student RecordsДокумент45 страницFile Structure Lab Program Student RecordsManvanth B CОценок пока нет
- OFF Grid Solar PCU Manual: India's First 5 Mode Solar InverterДокумент35 страницOFF Grid Solar PCU Manual: India's First 5 Mode Solar InverterV'nay KuMarОценок пока нет
- xc3000 Logic Cell Array FamilyДокумент8 страницxc3000 Logic Cell Array FamilyRemo NamОценок пока нет
- UntitledДокумент5 страницUntitledGladson MosesОценок пока нет
- SFF-Agenda 0211 ST v3Документ37 страницSFF-Agenda 0211 ST v3Patrick DeacostaОценок пока нет
- Sikhitothemax User Guide New FeaturesДокумент2 страницыSikhitothemax User Guide New FeaturesJagjot SinghОценок пока нет
- Ap Csa Van Slyke Pacing GuideДокумент2 страницыAp Csa Van Slyke Pacing Guideapi-377548294Оценок пока нет
- Red Hat Directory Server 10: Performance Tuning GuideДокумент56 страницRed Hat Directory Server 10: Performance Tuning GuideMunshi H HaqueОценок пока нет
- Experion PPC (Panel PC) : Connected PlantДокумент4 страницыExperion PPC (Panel PC) : Connected PlantAxl TovarОценок пока нет
- HU10293GYBДокумент8 страницHU10293GYBdaniela vegaОценок пока нет
- GLAMOS Manual ENДокумент18 страницGLAMOS Manual ENbagasОценок пока нет
- Demystifying Cyber Threat Intelligence - Debraj Dey Null - OWASP KolkataДокумент18 страницDemystifying Cyber Threat Intelligence - Debraj Dey Null - OWASP KolkataNull KolkataОценок пока нет
- Tarala Leizel Oracle Laboratory 4Документ8 страницTarala Leizel Oracle Laboratory 4Liezel Panganiban TaralaОценок пока нет
- Optiplex 7070 Spec SheetДокумент7 страницOptiplex 7070 Spec Sheetantonio jesusОценок пока нет
- Photoshop LessonДокумент4 страницыPhotoshop LessonXzyl BantoloОценок пока нет
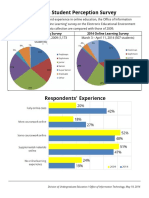
- Online Learning Survey 20092014Документ6 страницOnline Learning Survey 20092014Aeron Paul100% (1)