Вам также может понравиться
- Save PDS HB Jassin: Social Movement For The Cultural HeritageДокумент7 страницSave PDS HB Jassin: Social Movement For The Cultural HeritageAhmad SubhanОценок пока нет
- Foundations of A Theory of BibliographyДокумент13 страницFoundations of A Theory of BibliographyAhmad Subhan100% (1)
- How The Bibliotheca Alexandrina Is Supporting The 2011 RevolutionДокумент2 страницыHow The Bibliotheca Alexandrina Is Supporting The 2011 RevolutionAhmad SubhanОценок пока нет
- Presentasi Peter Carey Di Sanata Dharma - 7 Maret 2012 - Metode Riset Sejarah - Membosankan Atau Mengasyikkan?Документ47 страницPresentasi Peter Carey Di Sanata Dharma - 7 Maret 2012 - Metode Riset Sejarah - Membosankan Atau Mengasyikkan?Ahmad SubhanОценок пока нет
- OneNote Notes (As PDFДокумент2 страницыOneNote Notes (As PDFWashington City PaperОценок пока нет
- Egyptians Find Their Power in Acces To InformationДокумент2 страницыEgyptians Find Their Power in Acces To InformationAhmad SubhanОценок пока нет
- Models of Embedded LibrarianshipДокумент195 страницModels of Embedded LibrarianshipAhmad SubhanОценок пока нет
- Librarians Embedded in ResearchДокумент4 страницыLibrarians Embedded in ResearchAhmad SubhanОценок пока нет
- Between Instrumentalization and Empowerment - How Ten Ghanaian Civil Society Organizations Produce and Disseminate Knowledge - Denise BeaulieuДокумент18 страницBetween Instrumentalization and Empowerment - How Ten Ghanaian Civil Society Organizations Produce and Disseminate Knowledge - Denise BeaulieuAhmad SubhanОценок пока нет
- Knowledge, Networks and NationsДокумент114 страницKnowledge, Networks and NationsJarvisОценок пока нет
- An Introduction To Copyright and How To Use ItДокумент52 страницыAn Introduction To Copyright and How To Use ItAhmad SubhanОценок пока нет
- Communicating Research - Influencing ChangeДокумент171 страницаCommunicating Research - Influencing ChangeAhmad SubhanОценок пока нет
- Knowledge Brokers and Think-TanksДокумент8 страницKnowledge Brokers and Think-TanksAhmad SubhanОценок пока нет
- World Social Science Report 2010Документ443 страницыWorld Social Science Report 2010Adriana GorgaОценок пока нет
- Localising Power in Post-Authoritarian Indonesia - A Southeast Asia Perspective - Vedi R. HadizДокумент7 страницLocalising Power in Post-Authoritarian Indonesia - A Southeast Asia Perspective - Vedi R. HadizAhmad SubhanОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Bio 104 Lab Manual 2010Документ236 страницBio 104 Lab Manual 2010Querrynithen100% (1)
- Evolution DBQДокумент4 страницыEvolution DBQCharles JordanОценок пока нет
- Report Painter GR55Документ17 страницReport Painter GR55Islam EldeebОценок пока нет
- Online Dynamic Security Assessment of Wind Integrated Power System UsingДокумент9 страницOnline Dynamic Security Assessment of Wind Integrated Power System UsingRizwan Ul HassanОценок пока нет
- AT ChapIДокумент48 страницAT ChapIvigneshwaranbeОценок пока нет
- Lic Nach MandateДокумент1 страницаLic Nach Mandatefibiro9231Оценок пока нет
- Question BankДокумент3 страницыQuestion BankHimanshu SharmaОценок пока нет
- The Role of Needs Analysis in Adult ESL Programme Design: Geoffrey BrindleyДокумент16 страницThe Role of Needs Analysis in Adult ESL Programme Design: Geoffrey Brindleydeise krieser100% (2)
- DLP - CO#1-for PandemicДокумент4 страницыDLP - CO#1-for PandemicEvelyn CanoneraОценок пока нет
- Classroom Debate Rubric Criteria 5 Points 4 Points 3 Points 2 Points 1 Point Total PointsДокумент1 страницаClassroom Debate Rubric Criteria 5 Points 4 Points 3 Points 2 Points 1 Point Total PointsKael PenalesОценок пока нет
- In Search of Begum Akhtar PDFДокумент42 страницыIn Search of Begum Akhtar PDFsreyas1273Оценок пока нет
- Pre Intermediate Talking ShopДокумент4 страницыPre Intermediate Talking ShopSindy LiОценок пока нет
- 3.15.E.V25 Pneumatic Control Valves DN125-150-EnДокумент3 страницы3.15.E.V25 Pneumatic Control Valves DN125-150-EnlesonspkОценок пока нет
- TMS320C67x Reference GuideДокумент465 страницTMS320C67x Reference Guideclenx0% (1)
- ZH210LC 5BДокумент24 страницыZH210LC 5BPHÁT NGUYỄN THẾ0% (1)
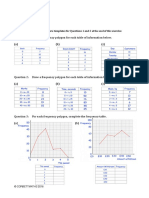
- Frequency Polygons pdf3Документ7 страницFrequency Polygons pdf3Nevine El shendidyОценок пока нет
- Each Life Raft Must Contain A Few ItemsДокумент2 страницыEach Life Raft Must Contain A Few ItemsMar SundayОценок пока нет
- ER288 090714 5082 CV OKP (089) Method Statement For Plate Baring TestДокумент3 страницыER288 090714 5082 CV OKP (089) Method Statement For Plate Baring TestWr ArОценок пока нет
- Business Statistics: Fourth Canadian EditionДокумент41 страницаBusiness Statistics: Fourth Canadian EditionTaron AhsanОценок пока нет
- 3.1 MuazuДокумент8 страниц3.1 MuazuMon CastrОценок пока нет
- Plane TrigonometryДокумент545 страницPlane Trigonometrygnavya680Оценок пока нет
- Catalog NeosetДокумент173 страницыCatalog NeosetCarmen Draghia100% (1)
- 9300AE 10-30kseis LDN 2005 PDFДокумент2 страницы9300AE 10-30kseis LDN 2005 PDFDoina ClichiciОценок пока нет
- Feasibility and Optimization of Dissimilar Laser Welding ComponentsДокумент366 страницFeasibility and Optimization of Dissimilar Laser Welding Componentskaliappan45490Оценок пока нет
- TOPIC: Movable and Immovable Property Under Section-3 of Transfer of Property ActДокумент10 страницTOPIC: Movable and Immovable Property Under Section-3 of Transfer of Property ActRishAbh DaidОценок пока нет
- Introduction To SCRДокумент19 страницIntroduction To SCRAlbin RobinОценок пока нет
- Watershed Conservation of Benguet VisДокумент2 страницыWatershed Conservation of Benguet VisInnah Agito-RamosОценок пока нет
- Activity 2Документ5 страницActivity 2DIOSAY, CHELZEYA A.Оценок пока нет
- SeparexgeneralbrochureДокумент4 страницыSeparexgeneralbrochurewwl1981Оценок пока нет
- Assignment 5 WarehousingДокумент4 страницыAssignment 5 WarehousingabbasОценок пока нет