Вам также может понравиться
- Présentation ProcДокумент26 страницPrésentation ProcNezha BENICHOU100% (1)
- Chapitre2 Calcul Parallèle de La Performance Chap 2 - EtudiantsДокумент28 страницChapitre2 Calcul Parallèle de La Performance Chap 2 - Etudiantsoumayma.benkhalifa.kmfОценок пока нет
- Cours Tests P1Документ56 страницCours Tests P1Hadil AyariОценок пока нет
- P0 Introduction PIДокумент19 страницP0 Introduction PIHajar RztОценок пока нет
- Tpinfo741 ArduinoitДокумент2 страницыTpinfo741 ArduinoitKARKAR NORAОценок пока нет
- CR tp3 GleyzeДокумент11 страницCR tp3 Gleyzegleyze.carelОценок пока нет
- Introduction A La Programmation Temps Reel Avec Labview 4.1Документ27 страницIntroduction A La Programmation Temps Reel Avec Labview 4.1Hmz OussamaОценок пока нет
- IFC 2022 AS ProgrammeДокумент1 страницаIFC 2022 AS Programmekheliddalila156Оценок пока нет
- Performance Des Entrées-Sorties: Temps D'exécution D'une InstructionДокумент6 страницPerformance Des Entrées-Sorties: Temps D'exécution D'une InstructionAMADOU OUATTARAОценок пока нет
- Uml Erraha Final Ensa3 2023Документ223 страницыUml Erraha Final Ensa3 2023Manal LahmidiОценок пока нет
- MOCN TournageДокумент2 страницыMOCN Tournageʚĩɞ Wã Fãã ʚĩɞОценок пока нет
- Introduction À Extreme ProgrammingДокумент24 страницыIntroduction À Extreme ProgrammingSamy DahmaniОценок пока нет
- Revision SE1 1 2 3 4Документ7 страницRevision SE1 1 2 3 4Ilyes The KingОценок пока нет
- Presentation de Tableau de Bord Industriel Pour La Mesure de La PerformanceДокумент16 страницPresentation de Tableau de Bord Industriel Pour La Mesure de La Performanceyosra hammamiОценок пока нет
- OTT Outillage Des Tests Cours 1 1Документ163 страницыOTT Outillage Des Tests Cours 1 1Amine Besrour100% (1)
- Intro UMS SMI S5 PDFДокумент82 страницыIntro UMS SMI S5 PDFFaty FatyОценок пока нет
- Cours 8 ProcesseursUsageGeneralДокумент48 страницCours 8 ProcesseursUsageGeneralAnass OkhitaОценок пока нет
- Process and Project MetricsДокумент30 страницProcess and Project MetricsRihem DridiОценок пока нет
- Presentation Du Projet Mac Seance 1Документ20 страницPresentation Du Projet Mac Seance 1Babacar SowОценок пока нет
- Microcontrolleurs C1Документ89 страницMicrocontrolleurs C1Coop ZkuberveitОценок пока нет
- Chapter 4 Partie1Документ43 страницыChapter 4 Partie1s.kouadriОценок пока нет
- Dossier-08-Thème-51-EL GOURARI Aya-2714Документ6 страницDossier-08-Thème-51-EL GOURARI Aya-2714azertyОценок пока нет
- Support Du Cours RO TL2020Документ153 страницыSupport Du Cours RO TL2020Abdelhay Hmitouch100% (1)
- COO Chapitre1 3IIRДокумент43 страницыCOO Chapitre1 3IIRMido BenОценок пока нет
- Cours Algorithmique 2Документ130 страницCours Algorithmique 2Yvanna TebeuОценок пока нет
- Algorithmique - Fonctions Et ProcéduresДокумент28 страницAlgorithmique - Fonctions Et ProcéduresOussama ElhajjamiОценок пока нет
- Lecon-1 GL IntroДокумент46 страницLecon-1 GL IntroLuc Mahop NgosОценок пока нет
- AGILE - Cours - GL - ISG PDFДокумент28 страницAGILE - Cours - GL - ISG PDFIntissar HidriОценок пока нет
- Technique de GestionДокумент3 страницыTechnique de GestionAne SmОценок пока нет
- TSTL SPCL Contrôler Un Moteur Pas À Pas Avec ArduinoДокумент6 страницTSTL SPCL Contrôler Un Moteur Pas À Pas Avec Arduinonew technologyОценок пока нет
- Construisez Des Applications Autonomes Et Fiables Avec LabVIEW Real TimeДокумент26 страницConstruisez Des Applications Autonomes Et Fiables Avec LabVIEW Real TimeEL AFOUОценок пока нет
- Automatisation Dun Systeme de CaissiersДокумент15 страницAutomatisation Dun Systeme de Caissiersrabia elmaakouliОценок пока нет
- Ex Temps ReelДокумент2 страницыEx Temps ReelChristian HaddadОценок пока нет
- TP 3 Initiation À ArenaДокумент8 страницTP 3 Initiation À ArenaNesrine MannaiОценок пока нет
- Test Logiciel: Pr. Aimad QAZDARДокумент71 страницаTest Logiciel: Pr. Aimad QAZDARHamza HaОценок пока нет
- API Chapitre 1Документ16 страницAPI Chapitre 1aimad.missi2005Оценок пока нет
- Cours Sur MERISEДокумент130 страницCours Sur MERISEMoussa Diouf DIALLOОценок пока нет
- coursGenieLogicielchap1 Chap3Документ91 страницаcoursGenieLogicielchap1 Chap3Bilel SedghianiОценок пока нет
- Intro Gestion Projet 2022Документ11 страницIntro Gestion Projet 2022fauxcompte262Оценок пока нет
- Chapitre 1-Introduction3Документ81 страницаChapitre 1-Introduction3nourОценок пока нет
- PE Operateur Micro - Informatique 03 03 14Документ46 страницPE Operateur Micro - Informatique 03 03 14أحمد ولد ميلودОценок пока нет
- Cours Algo Septembre 2018 Partie1 EttalbiДокумент112 страницCours Algo Septembre 2018 Partie1 EttalbiYassin BtОценок пока нет
- PFF Avancée2Документ30 страницPFF Avancée2ahmed ben rejebОценок пока нет
- Tableaux de Bord Dynamique en VBAДокумент11 страницTableaux de Bord Dynamique en VBAihssane najmiОценок пока нет
- Controle MAG 2021Документ4 страницыControle MAG 2021wassim.boukahilОценок пока нет
- Seance5 Log3410Документ53 страницыSeance5 Log3410ZayNabОценок пока нет
- Projet Intégration TIC2Документ24 страницыProjet Intégration TIC2Samira BaderОценок пока нет
- 8-Interfacage LabVIEW SolidWorksДокумент19 страниц8-Interfacage LabVIEW SolidWorksMahrez Zaafouri100% (2)
- Supervision: La Refonte Du Système de Formation Initiale Des EnseignantsДокумент30 страницSupervision: La Refonte Du Système de Formation Initiale Des Enseignantssimo jinОценок пока нет
- Amdec MPДокумент29 страницAmdec MPKamal BeidenОценок пока нет
- Chapitre 1 2Документ38 страницChapitre 1 2MeryОценок пока нет
- Cours D'algo - MSP1 Cursus Ing. Oct. 2022Документ29 страницCours D'algo - MSP1 Cursus Ing. Oct. 2022Yoan Miguel TsangОценок пока нет
- Chapitre 1 Suite - Modeles de Cycles de Vie Des Logiciels - SlidesДокумент32 страницыChapitre 1 Suite - Modeles de Cycles de Vie Des Logiciels - SlidesIndigo LandОценок пока нет
- Expression de BesoinДокумент4 страницыExpression de BesoinAli YayeОценок пока нет
- Assurance Qualité de Logiciel-1Документ50 страницAssurance Qualité de Logiciel-1zaydОценок пока нет
- Projet Planificateur de TachesДокумент1 страницаProjet Planificateur de TachesKhammal AdilОценок пока нет
- TD06 TGPLДокумент2 страницыTD06 TGPLelhadj.mohamadiОценок пока нет
- TD1 - 2021Документ2 страницыTD1 - 2021scar lightОценок пока нет
- Qualification Et Optimisation de ProcessusДокумент41 страницаQualification Et Optimisation de Processusfrancois.barreauОценок пока нет
- Orga Resume Chapitre 3Документ7 страницOrga Resume Chapitre 3idemОценок пока нет
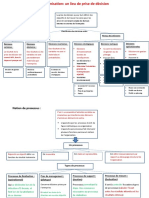
- La Décision COURSДокумент11 страницLa Décision COURSidemОценок пока нет
- Chapitre1 Evolution Des OrdinateursДокумент45 страницChapitre1 Evolution Des OrdinateursidemОценок пока нет
- Chapitre 3 - Hiérarchie MémoireДокумент61 страницаChapitre 3 - Hiérarchie MémoireidemОценок пока нет
- ApacheДокумент11 страницApachefehriОценок пока нет
- Method Es AgileДокумент13 страницMethod Es AgileMayssa RjaibiaОценок пока нет
- Comment Modifier Un Fichier PDF en Word GratuitДокумент2 страницыComment Modifier Un Fichier PDF en Word GratuitRebeccaОценок пока нет
- (Esr) Tp4 - HTMLДокумент3 страницы(Esr) Tp4 - HTMLSmart SharmОценок пока нет
- Exercice Fraction Cm1 PDFДокумент2 страницыExercice Fraction Cm1 PDFKelly0% (1)
- PRESENTATION DE SAGE ERP X3 OkДокумент12 страницPRESENTATION DE SAGE ERP X3 OkZacharie Nkanyou100% (2)
- CNED Preperation DELF-DALF PDFДокумент5 страницCNED Preperation DELF-DALF PDFeanicolasОценок пока нет
- Les Tests Unitaires en Java PDFДокумент30 страницLes Tests Unitaires en Java PDFSaid Boubker100% (1)
- TP Cao-1Документ13 страницTP Cao-1Babou khawlaОценок пока нет
- Administration en Ligne de Commande Indiquer QuellesДокумент3 страницыAdministration en Ligne de Commande Indiquer QuellesradouaneОценок пока нет
- Python Module IHM PyQtДокумент21 страницаPython Module IHM PyQtMONTCHO WesleyОценок пока нет
- Cours TwigДокумент30 страницCours TwigMoetaz BrayekОценок пока нет
- PHP 03 PHP MySQLДокумент34 страницыPHP 03 PHP MySQLdsn2008Оценок пока нет
- Cardiologie - Apprentissage Raisonnement Clinique PDFДокумент49 страницCardiologie - Apprentissage Raisonnement Clinique PDFBouhlalОценок пока нет
- 888 Catalogue 2011 Modicom m340Документ267 страниц888 Catalogue 2011 Modicom m340ChihebJmaa100% (1)
- CV Lettre Motivation EmilienДокумент2 страницыCV Lettre Motivation Emilienapi-510764744Оценок пока нет
- Profils Edition PiloteeДокумент4 страницыProfils Edition PiloteeSheva Chenko100% (1)
- Rapport de Stage Kaliem 2018Документ18 страницRapport de Stage Kaliem 2018Gig AssanОценок пока нет
- Inition Logiciel RДокумент53 страницыInition Logiciel Rousmane100% (1)
- Scrum 6Документ12 страницScrum 6api-299745725Оценок пока нет
- Exemple Etude ComparativeДокумент15 страницExemple Etude ComparativeSaliha LekniziОценок пока нет
- TP Arbre de DécisionsДокумент3 страницыTP Arbre de DécisionsSanae Chadi100% (1)
- TP 4 Bases de Données PDFДокумент2 страницыTP 4 Bases de Données PDFYassine KababОценок пока нет
- Securité ReseauxДокумент15 страницSecurité ReseauxAdel Sama100% (1)
- Gestion Des Fichiers .PST Dans Microsoft Outlook PDFДокумент6 страницGestion Des Fichiers .PST Dans Microsoft Outlook PDFMinistere EdificeОценок пока нет
- Bases de Donnees Avancees I - SGBDROДокумент35 страницBases de Donnees Avancees I - SGBDROFranck Lionel TchakounteОценок пока нет
- Rendre Un Virus IndetectableДокумент8 страницRendre Un Virus IndetectableJean-Yves RolandОценок пока нет
- TP C2i - 1Документ2 страницыTP C2i - 1Arfa RawiaОценок пока нет
- Bts Sio E6 Tableau Synthese Robin GuignerДокумент1 страницаBts Sio E6 Tableau Synthese Robin Guignerapi-373301626Оценок пока нет
- Chap3 Requêtes 2013 2Документ49 страницChap3 Requêtes 2013 2Khaled Ben AhmedОценок пока нет