Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Daikin LXE10E-A - Service Manual (TR 01-09B) PDFДокумент238 страницDaikin LXE10E-A - Service Manual (TR 01-09B) PDFmail4ksnОценок пока нет
- Development of Mmlps in India: Western DFC Eastern DFCДокумент2 страницыDevelopment of Mmlps in India: Western DFC Eastern DFCsdfg100% (2)
- Streets As Places - Un Habitat ReportДокумент168 страницStreets As Places - Un Habitat Reportrf88100% (7)
- Classification and Regression Trees (CART - I) : Dr. A. RameshДокумент34 страницыClassification and Regression Trees (CART - I) : Dr. A. RameshVaibhav GuptaОценок пока нет
- Classification and Regression Trees (CART - III) : DR A. RameshДокумент42 страницыClassification and Regression Trees (CART - III) : DR A. RameshVaibhav GuptaОценок пока нет
- Cashless Indian Economy (Merits and Demerits) : Presentation OnДокумент10 страницCashless Indian Economy (Merits and Demerits) : Presentation OnVaibhav GuptaОценок пока нет
- Optimization For Data ScienceДокумент18 страницOptimization For Data ScienceVaibhav GuptaОценок пока нет
- Industrial Instrumentation LabДокумент34 страницыIndustrial Instrumentation LabVaibhav GuptaОценок пока нет
- K - Nearest Neighbors Implementation in RДокумент22 страницыK - Nearest Neighbors Implementation in RVaibhav GuptaОценок пока нет
- 3 1 - Exam: 100 MarksДокумент1 страница3 1 - Exam: 100 MarksVaibhav GuptaОценок пока нет
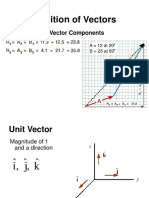
- Addition of Vectors: Combining Vector ComponentsДокумент10 страницAddition of Vectors: Combining Vector ComponentsVaibhav GuptaОценок пока нет
- ML Assignment v4Документ1 страницаML Assignment v4Vaibhav GuptaОценок пока нет
- Varignon's Theorem: F R F R F F RДокумент10 страницVarignon's Theorem: F R F R F F RVaibhav GuptaОценок пока нет
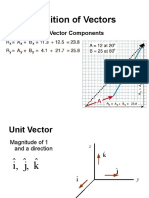
- Addition of Vectors: Combining Vector ComponentsДокумент10 страницAddition of Vectors: Combining Vector ComponentsVaibhav GuptaОценок пока нет
- Fragility Curves For Mixed Concrete-Steel Frames Subjected To SeismicДокумент5 страницFragility Curves For Mixed Concrete-Steel Frames Subjected To SeismicJulián PovedaОценок пока нет
- Jurnal Ari Maulana Ullum Sasmi 1801038Документ12 страницJurnal Ari Maulana Ullum Sasmi 180103803. Ari Maulana Ullum Sasmi / TD 2.10Оценок пока нет
- Pre Delivery Inspection Checklist For Home Oxygen ConcentratorДокумент2 страницыPre Delivery Inspection Checklist For Home Oxygen ConcentratorPranavKaisthaОценок пока нет
- 1 Ha Cabbages - May 2018 PDFДокумент1 страница1 Ha Cabbages - May 2018 PDFMwai EstherОценок пока нет
- Yuasa Technical Data Sheet: The World's Leading Battery ManufacturerДокумент1 страницаYuasa Technical Data Sheet: The World's Leading Battery ManufacturerAshraf Sayed ShabaanОценок пока нет
- Megger-Mjolner-600 Ds enДокумент5 страницMegger-Mjolner-600 Ds enAmit Kumar KandiОценок пока нет
- FWD Week 47 Learning Material For Alaric YeoДокумент7 страницFWD Week 47 Learning Material For Alaric YeoarielОценок пока нет
- Stylus - Pro - 4400 201 300 (067 100)Документ34 страницыStylus - Pro - 4400 201 300 (067 100)Joso CepuranОценок пока нет
- Intermed Products: International CatalogueДокумент12 страницIntermed Products: International CatalogueRicardo Bonetti TadenОценок пока нет
- Apple Witness ListДокумент30 страницApple Witness ListMikey CampbellОценок пока нет
- GRADE 8 3rd Quarter DLP in EnglishДокумент484 страницыGRADE 8 3rd Quarter DLP in EnglishJulius Salas100% (4)
- Unit 9: Cities of The World I. ObjectivesДокумент4 страницыUnit 9: Cities of The World I. ObjectivesTrang Hoang NguyenОценок пока нет
- Assignment-2: 1) Explain Classification With Logistic Regression and Sigmoid FunctionДокумент6 страницAssignment-2: 1) Explain Classification With Logistic Regression and Sigmoid FunctionpraneshОценок пока нет
- Digital Album On Prominent Social ScientistsДокумент10 страницDigital Album On Prominent Social ScientistsOliver Antony ThomasОценок пока нет
- ( (2004) Yamamuro & Wood) - Effect of Depositional Method On The Undrained Behavior and Microstructure of Sand With SiltДокумент10 страниц( (2004) Yamamuro & Wood) - Effect of Depositional Method On The Undrained Behavior and Microstructure of Sand With SiltLAM TRAN DONG KIEMОценок пока нет
- Chapter Two Sector Analysis: (MBAM)Документ23 страницыChapter Two Sector Analysis: (MBAM)Ferlyn PelayoОценок пока нет
- Prose 2 - Lost Spring - Important QAДокумент5 страницProse 2 - Lost Spring - Important QADangerous GamingОценок пока нет
- Chart and Compass (London Zetetic Society)Документ8 страницChart and Compass (London Zetetic Society)tjmigoto@hotmail.comОценок пока нет
- PSCADДокумент10 страницPSCADkaran976Оценок пока нет
- 48 Sociology: B.A./B.Sc.: Elective and OptionalДокумент4 страницы48 Sociology: B.A./B.Sc.: Elective and OptionalMОценок пока нет
- Komatsu Wheel Loaders Wa250pz 5 Shop ManualДокумент20 страницKomatsu Wheel Loaders Wa250pz 5 Shop Manualmarcia100% (48)
- DAC AnalysisДокумент19 страницDAC Analysisమురళీధర్ ఆది ఆంధ్రుడుОценок пока нет
- Solutions Tutorial 6Документ9 страницSolutions Tutorial 6Nur Aqilah Abdullah HashimОценок пока нет
- Most Essential Learning Competencies English 4: Dagundon Elementary SchoolДокумент6 страницMost Essential Learning Competencies English 4: Dagundon Elementary SchoolGhie DomingoОценок пока нет
- Life Evolution Universe Lecture Notes - AUCДокумент45 страницLife Evolution Universe Lecture Notes - AUCAlejandro VerdeОценок пока нет
- Ped 5 FTДокумент39 страницPed 5 FTJoy Grace TablanteОценок пока нет