Вам также может понравиться
- TNS - Troubleshooting TNSДокумент8 страницTNS - Troubleshooting TNSadeyemikОценок пока нет
- Oracle Managed ErrorsДокумент44 страницыOracle Managed ErrorsparyabОценок пока нет
- Tracing Bind Variables and Waits 20000507Документ5 страницTracing Bind Variables and Waits 20000507José Laurindo ChiappaОценок пока нет
- Important Oracle TipsДокумент8 страницImportant Oracle TipsRohit KumarОценок пока нет
- AWR Snapshot Troubleshooting and DiagnosticsДокумент8 страницAWR Snapshot Troubleshooting and DiagnosticsDev FitriadyОценок пока нет
- Measuring Storage Performance For Oracle Systems - Calibrating IOДокумент5 страницMeasuring Storage Performance For Oracle Systems - Calibrating IODev FitriadyОценок пока нет
- ORA-00600 Internal Error Code, Arguments 4191Документ3 страницыORA-00600 Internal Error Code, Arguments 4191Alberto Hernandez HernandezОценок пока нет
- SAP IDES 4.71 Installation With Oracle 9iДокумент200 страницSAP IDES 4.71 Installation With Oracle 9iAustin MarcosОценок пока нет
- PDF Translator 1693649449741Документ4 страницыPDF Translator 1693649449741kruemeL1969Оценок пока нет
- NetBackup 4 - 5 RMAN Backup Fails With Status 6 (Failed To Back Up The Requested File)Документ6 страницNetBackup 4 - 5 RMAN Backup Fails With Status 6 (Failed To Back Up The Requested File)amsreekuОценок пока нет
- DeadlocksДокумент4 страницыDeadlocksguru181818Оценок пока нет
- Assignment DDLJДокумент8 страницAssignment DDLJBabu ShaikhОценок пока нет
- Real Application TestingДокумент35 страницReal Application Testingsap hanaОценок пока нет
- Daily WorkДокумент68 страницDaily Workapi-3819698Оценок пока нет
- Oracle Recovery For Missing Archive LogДокумент3 страницыOracle Recovery For Missing Archive LogsayeedmhОценок пока нет
- Changing Character Set To UTF8 For Production DatabaseДокумент11 страницChanging Character Set To UTF8 For Production Databasepatrick_wangrui100% (1)
- 13Документ41 страница13Muhd QОценок пока нет
- Verilog Codes for Code Converters and ComparatorДокумент53 страницыVerilog Codes for Code Converters and Comparatorvenkata satishОценок пока нет
- Restore / Clone of A Database With A Different Name On The Same ServerДокумент34 страницыRestore / Clone of A Database With A Different Name On The Same ServeraasishОценок пока нет
- Database Survival Guide 2Документ6 страницDatabase Survival Guide 2ovidiu0702Оценок пока нет
- Database Hang Oracle SolutionДокумент15 страницDatabase Hang Oracle SolutionMelissa MillerОценок пока нет
- Recover Oracle Database Upon Losing All Control FiДокумент5 страницRecover Oracle Database Upon Losing All Control Fipatrick_wangruiОценок пока нет
- ADRCI - A Survival Guide For The DBAДокумент13 страницADRCI - A Survival Guide For The DBAIlarioОценок пока нет
- Point in Time Recovery Using RmanДокумент3 страницыPoint in Time Recovery Using RmanShantha KumarОценок пока нет
- EbsДокумент35 страницEbssarrojОценок пока нет
- Data Guard Failover Test Using SQLДокумент8 страницData Guard Failover Test Using SQLKrishna8765Оценок пока нет
- What Happens When The Database Is in Begin Backup ModeДокумент4 страницыWhat Happens When The Database Is in Begin Backup ModeEddie Gonzalez100% (1)
- PL SQL Exercise by UnswДокумент5 страницPL SQL Exercise by Unswnemo_11Оценок пока нет
- KB - DOC - Oracle BugДокумент6 страницKB - DOC - Oracle BugSrinathDОценок пока нет
- Advanced Replication Monitoring PresentationДокумент13 страницAdvanced Replication Monitoring PresentationOleksiy Kovyrin100% (1)
- Introduction To 600/7445 Internal Error Analysis (Doc ID 390293.1)Документ9 страницIntroduction To 600/7445 Internal Error Analysis (Doc ID 390293.1)ingjguedezОценок пока нет
- Document 988907.1Документ2 страницыDocument 988907.1segador2000Оценок пока нет
- Oracle DataGuard Physical Standby Installation Step by StepДокумент10 страницOracle DataGuard Physical Standby Installation Step by Stepknugroho1982Оценок пока нет
- Oracle Patch UpgradationДокумент2 страницыOracle Patch UpgradationRajesh VanapalliОценок пока нет
- Applying PSU Patch in A DataguardДокумент36 страницApplying PSU Patch in A Dataguardcharan817100% (1)
- Aq TM Process in Oracle Initialization Parameter FileДокумент5 страницAq TM Process in Oracle Initialization Parameter FileAijaz Sabir HussainОценок пока нет
- Cloud Control 12c ALL InstallationsДокумент19 страницCloud Control 12c ALL InstallationsMaliha KhanОценок пока нет
- Troubleshooting Cisco Callmanager Crashes: Document Id: 44366Документ7 страницTroubleshooting Cisco Callmanager Crashes: Document Id: 44366Kishore NunnaОценок пока нет
- Restore ControlfileДокумент3 страницыRestore ControlfilePradip MistryОценок пока нет
- Qs 21-25Документ5 страницQs 21-25api-248569118Оценок пока нет
- Art of Writing TestBenchesДокумент14 страницArt of Writing TestBenchesShrinivas SaptalakarОценок пока нет
- Best Practices For Oracle Databases: Alexander KornbrustДокумент33 страницыBest Practices For Oracle Databases: Alexander KornbrustPedro PerezОценок пока нет
- (.NET) Decrypt Confuser 1.9 MethodsДокумент18 страниц(.NET) Decrypt Confuser 1.9 Methodshayokuma_super83% (6)
- Control File CreationДокумент7 страницControl File CreationAtul SharmaОценок пока нет
- Ora-13013 1Документ6 страницOra-13013 1Yulin LiuОценок пока нет
- Nexus 7000 Supervisor 2 2E Compact Flash PDFДокумент27 страницNexus 7000 Supervisor 2 2E Compact Flash PDFnelsonjedОценок пока нет
- Oracle Schema Statistics and Concurrent Manager IssuesДокумент26 страницOracle Schema Statistics and Concurrent Manager IssuesVinay ReddyОценок пока нет
- Interview Questions From Oracle High AvailabilityДокумент18 страницInterview Questions From Oracle High AvailabilitypashaapiОценок пока нет
- Project LockdownДокумент71 страницаProject LockdownDaniel NelsonОценок пока нет
- Ebsom Dbim PDFДокумент15 страницEbsom Dbim PDFCuong Nguyen TanОценок пока нет
- Archive Gap Detection and Resolution in DG Environment PDFДокумент20 страницArchive Gap Detection and Resolution in DG Environment PDFG.R.THIYAGU ; Oracle DBA78% (9)
- Psu Patch On DGДокумент14 страницPsu Patch On DGThota Mahesh DbaОценок пока нет
- Obiee: Call Sapurgeallcache : Here HereДокумент8 страницObiee: Call Sapurgeallcache : Here HereVikram ReddyОценок пока нет
- DOAG2016 Hacking Oracles Memory About Internals Troubleshooting PDFДокумент21 страницаDOAG2016 Hacking Oracles Memory About Internals Troubleshooting PDFjlc19670% (1)
- Oracle Database Security Interview Questions, Answers, and Explanations: Oracle Database Security Certification ReviewОт EverandOracle Database Security Interview Questions, Answers, and Explanations: Oracle Database Security Certification ReviewОценок пока нет
- LNX Storage 3Документ12 страницLNX Storage 3Yulin LiuОценок пока нет
- LNX Storage 2Документ7 страницLNX Storage 2Yulin LiuОценок пока нет
- LNX Storage 1bДокумент12 страницLNX Storage 1bYulin LiuОценок пока нет
- Ora Net 0cДокумент13 страницOra Net 0cYulin LiuОценок пока нет
- Ora Net 2aДокумент8 страницOra Net 2aYulin LiuОценок пока нет
- LNX Storage 1aДокумент12 страницLNX Storage 1aYulin LiuОценок пока нет
- LNX Storage 0Документ10 страницLNX Storage 0Yulin LiuОценок пока нет
- Ora Net 1aДокумент12 страницOra Net 1aYulin LiuОценок пока нет
- RAC SCAN and HAIP configurationДокумент12 страницRAC SCAN and HAIP configurationYulin LiuОценок пока нет
- Ora Net 1bДокумент7 страницOra Net 1bYulin LiuОценок пока нет
- Ora Net 0aДокумент13 страницOra Net 0aYulin LiuОценок пока нет
- Verify network and name resolution setup for Oracle Grid Infrastructure and RACДокумент12 страницVerify network and name resolution setup for Oracle Grid Infrastructure and RACYulin LiuОценок пока нет
- AIX HW Wikis 0Документ11 страницAIX HW Wikis 0Yulin LiuОценок пока нет
- Ora Net 1bДокумент13 страницOra Net 1bYulin LiuОценок пока нет
- Verify network and name resolution setup for Oracle Grid Infrastructure and RACДокумент12 страницVerify network and name resolution setup for Oracle Grid Infrastructure and RACYulin LiuОценок пока нет
- Ora-13013 1Документ6 страницOra-13013 1Yulin LiuОценок пока нет
- Ora Net 1cДокумент12 страницOra Net 1cYulin LiuОценок пока нет
- Ora Net 1aДокумент12 страницOra Net 1aYulin LiuОценок пока нет
- Ora BBED 0bДокумент9 страницOra BBED 0bYulin LiuОценок пока нет
- LNX Storage 3Документ10 страницLNX Storage 3Yulin LiuОценок пока нет
- NBU TapeAlert 1Документ1 страницаNBU TapeAlert 1Yulin LiuОценок пока нет
- KDB PDFДокумент362 страницыKDB PDFYulin LiuОценок пока нет
- Ora ASM VTДокумент6 страницOra ASM VTYulin LiuОценок пока нет
- Ora BBED 0Документ12 страницOra BBED 0Yulin LiuОценок пока нет
- LNX Uek 0Документ7 страницLNX Uek 0Yulin LiuОценок пока нет
- Ora-6002 1Документ3 страницыOra-6002 1Yulin LiuОценок пока нет
- Ora Corruption 1Документ7 страницOra Corruption 1Yulin LiuОценок пока нет
- Ora Upd Seg 1Документ3 страницыOra Upd Seg 1Yulin LiuОценок пока нет
- Ora-8102 2Документ8 страницOra-8102 2Yulin LiuОценок пока нет
- COP ImprovementДокумент3 страницыCOP ImprovementMainak PaulОценок пока нет
- NX Advanced Simulation坐标系Документ12 страницNX Advanced Simulation坐标系jingyong123Оценок пока нет
- Ground Plane AntennaДокумент7 страницGround Plane AntennaarijeetdguyОценок пока нет
- Deep Glow v1.4.6 ManualДокумент6 страницDeep Glow v1.4.6 ManualWARRIOR FF100% (1)
- Lecture Antenna MiniaturizationДокумент34 страницыLecture Antenna MiniaturizationJuhi GargОценок пока нет
- Hikmayanto Hartawan PurchДокумент12 страницHikmayanto Hartawan PurchelinОценок пока нет
- Model SRX-101A: Operation ManualДокумент31 страницаModel SRX-101A: Operation ManualSebastian SamolewskiОценок пока нет
- Class XI Chemistry Question BankДокумент71 страницаClass XI Chemistry Question BankNirmalaОценок пока нет
- Quasi VarianceДокумент2 страницыQuasi Varianceharrison9Оценок пока нет
- Matematika BookДокумент335 страницMatematika BookDidit Gencar Laksana100% (1)
- Assignment 2Документ6 страницAssignment 2Umar ZahidОценок пока нет
- Analisis Matricial Mario Paz PDFДокумент326 страницAnalisis Matricial Mario Paz PDFLeonardo Chavarro Velandia100% (1)
- SP 5500 V5.1 1.0Документ17 страницSP 5500 V5.1 1.0Rama Tenis CopecОценок пока нет
- Manual Fuji TemperaturaДокумент40 страницManual Fuji TemperaturaMartínОценок пока нет
- Daily production planning and capacity analysisДокумент27 страницDaily production planning and capacity analysisahetОценок пока нет
- SUMMATIVE EXAM (G11) 2023 ExamДокумент3 страницыSUMMATIVE EXAM (G11) 2023 ExamDens Lister Mahilum100% (1)
- Breathing AND Exchange of Gases MCQs PDFДокумент78 страницBreathing AND Exchange of Gases MCQs PDFJatin SinglaОценок пока нет
- Effect of SR, Na, Ca & P On The Castability of Foundry Alloy A356.2Документ10 страницEffect of SR, Na, Ca & P On The Castability of Foundry Alloy A356.2jose.figueroa@foseco.comОценок пока нет
- Ab5 PDFДокумент93 страницыAb5 PDFbhavani nagavarapuОценок пока нет
- Reed - Camion - XT39R4 - 1003 - Technical Manual - Panel de Control PDFДокумент293 страницыReed - Camion - XT39R4 - 1003 - Technical Manual - Panel de Control PDFLuisEduardoHerreraCamargo100% (1)
- Reinforcement Detailing in BeamsДокумент9 страницReinforcement Detailing in Beamssaheed tijaniОценок пока нет
- Peabody y Movent ABCДокумент11 страницPeabody y Movent ABCIngrid BarkoОценок пока нет
- Petroleum GeomechanicsДокумент35 страницPetroleum GeomechanicsAnonymous y6UMzakPW100% (1)
- Limiting Reagents 1Документ17 страницLimiting Reagents 1Aldrin Jay Patungan100% (1)
- Lec11 Amortized Loans Homework SolutionsДокумент3 страницыLec11 Amortized Loans Homework SolutionsJerickson MauricioОценок пока нет
- LED Linear Highbay LightingДокумент7 страницLED Linear Highbay LightingMohammed YasarОценок пока нет
- EEE415 Digital Image Processing: Frequency Domain FilteringДокумент50 страницEEE415 Digital Image Processing: Frequency Domain FilteringFAISAL NAWABОценок пока нет
- User's Manual: Electrolyte AnalyzerДокумент25 страницUser's Manual: Electrolyte AnalyzerNghi NguyenОценок пока нет
- Grade 7 Spa ReviewerДокумент1 страницаGrade 7 Spa ReviewerLanie De la Torre100% (1)
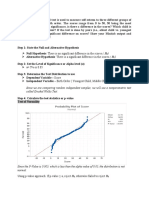
- Step 1: State The Null and Alternative HypothesisДокумент3 страницыStep 1: State The Null and Alternative HypothesisChristine Joyce BascoОценок пока нет