Вам также может понравиться
- a496c1leT590ZklR2 PDFДокумент17 страницa496c1leT590ZklR2 PDFPatrice Ngazanga AyissiОценок пока нет
- Administration Système Partie 1Документ41 страницаAdministration Système Partie 1Khabila Muphasa y'EnghongОценок пока нет
- Chapitre II STRДокумент12 страницChapitre II STRmi doОценок пока нет
- Deploiement de LogicielsДокумент26 страницDeploiement de LogicielsLassissi AfissouОценок пока нет
- Chap1 IntroductionДокумент10 страницChap1 IntroductionHalima DOUIBIОценок пока нет
- Ch1+Ch2+Ch3 Systèmes D'exploitation Génie CivilДокумент33 страницыCh1+Ch2+Ch3 Systèmes D'exploitation Génie CivilRealmak AweniОценок пока нет
- Partie1 IntroductionGLДокумент14 страницPartie1 IntroductionGLAmine GueraouchiОценок пока нет
- Camera Ready Belguidoum DagnatДокумент15 страницCamera Ready Belguidoum DagnatMohamed SelmaniОценок пока нет
- Cours-de-la-matière-Génie-logiciel Et UMLДокумент34 страницыCours-de-la-matière-Génie-logiciel Et UMLSonia KotelОценок пока нет
- Dossier de Suivi de ProjetДокумент3 страницыDossier de Suivi de ProjetSandrine Simo100% (1)
- Atelier - Solution DevOpsДокумент5 страницAtelier - Solution DevOpsJohnОценок пока нет
- Systeme Exploitation Linux2Документ151 страницаSysteme Exploitation Linux2isseu kaОценок пока нет
- Systeme Exploitation Linux1Документ106 страницSysteme Exploitation Linux1isseu kaОценок пока нет
- Architecture Logicielle - WikipédiaДокумент26 страницArchitecture Logicielle - WikipédiaPlamedi Kalema corneilleОценок пока нет
- Systeme Exploitation LinuxДокумент32 страницыSysteme Exploitation Linuxisseu kaОценок пока нет
- Systeme Exploitation Linux CompletДокумент194 страницыSysteme Exploitation Linux Completisseu kaОценок пока нет
- Chapitre I Introduction Aux Systèmes Temps Réel 2023Документ57 страницChapitre I Introduction Aux Systèmes Temps Réel 2023Ahmed Cherif BoulesnamОценок пока нет
- Resume UPДокумент9 страницResume UPmtaallah amalОценок пока нет
- Le Principe de Haute DisponibilitéДокумент9 страницLe Principe de Haute Disponibilitéeleuch raedОценок пока нет
- DefinitionДокумент4 страницыDefinitionDhalson KamdemОценок пока нет
- Suite logicielle: Révolutionner la vision par ordinateur avec la suite logicielle ultimeОт EverandSuite logicielle: Révolutionner la vision par ordinateur avec la suite logicielle ultimeОценок пока нет
- COURS Système ExploitationДокумент32 страницыCOURS Système ExploitationArmosОценок пока нет
- Cours de Génie LogicielДокумент30 страницCours de Génie LogicielMichel MuwalaОценок пока нет
- Cours DevopsДокумент160 страницCours Devopszineb lahibОценок пока нет
- CHAP1 - Cours Installation Et Maintenance Des LogicielsДокумент12 страницCHAP1 - Cours Installation Et Maintenance Des LogicielsjoelОценок пока нет
- Projet TutorielДокумент12 страницProjet TutorielGaetan FondjoОценок пока нет
- Chap - 1 - Planifier Une Stratégie de Déploiement Dun Système D'exploitationДокумент44 страницыChap - 1 - Planifier Une Stratégie de Déploiement Dun Système D'exploitationstanislas nabelewa100% (1)
- Introduction GénéraleДокумент6 страницIntroduction GénéraleNOMEDEMОценок пока нет
- GL by OpenAIДокумент10 страницGL by OpenAITanankemОценок пока нет
- Activité2.4 Jebli Khouloud PDFДокумент15 страницActivité2.4 Jebli Khouloud PDFyosraОценок пока нет
- Se CH2Документ13 страницSe CH2adriennikiema21Оценок пока нет
- Les Processus - La Programmation Système en C Sous Unix - OpenClassrooms PDFДокумент32 страницыLes Processus - La Programmation Système en C Sous Unix - OpenClassrooms PDFEdmond AdamouОценок пока нет
- Mypdf 3 RemovedДокумент4 страницыMypdf 3 RemovedManouher Ah-BakarОценок пока нет
- SEII - ch1 - PROCESSUSДокумент6 страницSEII - ch1 - PROCESSUSHoussam BoukhariОценок пока нет
- RTOSДокумент20 страницRTOSAlouani KacemОценок пока нет
- Support Du Cours D'architecture Des Systèmes D'exploitation - Nouveau Etudiants - 2022-2023Документ28 страницSupport Du Cours D'architecture Des Systèmes D'exploitation - Nouveau Etudiants - 2022-2023ayodeleprecieux02Оценок пока нет
- Chapitre 2 Pdef-1Документ28 страницChapitre 2 Pdef-1Docta Ndolo Jr.Оценок пока нет
- Conception Et Adaptation Des Solutions Applicatives 1Документ22 страницыConception Et Adaptation Des Solutions Applicatives 1Claude Clinson0% (1)
- Prises de Note 2023-2024 Genie LogicielДокумент21 страницаPrises de Note 2023-2024 Genie LogicielmamipoutaОценок пока нет
- Agile-Partie 2-1Документ18 страницAgile-Partie 2-1hamouda.khaoulaОценок пока нет
- IntroductionДокумент7 страницIntroductionakram el hadriОценок пока нет
- Année Universitaire: 2023-2024 Niveau: 2LISI & 2LSI & 2LIG Module: Programmation Orientée ObjetДокумент143 страницыAnnée Universitaire: 2023-2024 Niveau: 2LISI & 2LSI & 2LIG Module: Programmation Orientée Objetfarah.friwiОценок пока нет
- Architecture Logicielle - WikipédiaДокумент13 страницArchitecture Logicielle - WikipédiaMectardОценок пока нет
- Supervision Centralisee Infrastructures Distantes Reseaux Gestion Alarmes Notification AlertesДокумент96 страницSupervision Centralisee Infrastructures Distantes Reseaux Gestion Alarmes Notification Alertesأنيسة أباعبيدةОценок пока нет
- Glossaire UrbanisationДокумент2 страницыGlossaire Urbanisationlyricsmusic680Оценок пока нет
- Programmation Orientee ObjetДокумент105 страницProgrammation Orientee Objetaziz BouhremОценок пока нет
- Les Systèmes D'exploitationДокумент232 страницыLes Systèmes D'exploitationM_Ordinateur100% (14)
- Introduction GPOДокумент8 страницIntroduction GPOlima556Оценок пока нет
- Initiation Au Systeme D'exploitation PDFДокумент58 страницInitiation Au Systeme D'exploitation PDFBernard Kamona Kipili100% (2)
- Null 1Документ70 страницNull 1Justine DjuikomОценок пока нет
- Cours Linux (Unix) PDFДокумент76 страницCours Linux (Unix) PDFOmar NabilОценок пока нет
- Introduction Generale Aux Systemes Exploitations.805Документ6 страницIntroduction Generale Aux Systemes Exploitations.805Relaxing fati ChannelОценок пока нет
- Microsoft AzureДокумент7 страницMicrosoft AzureDesire gohoreОценок пока нет
- Techserv Chap04 PlanifДокумент8 страницTechserv Chap04 Planifggjaja.4242Оценок пока нет
- Chapitre I Balises Conceptuelles Et ThéoriquesДокумент23 страницыChapitre I Balises Conceptuelles Et ThéoriquesEl Seigneur Christian FelaОценок пока нет
- 05 - Les-Bonnes-Pratiques-Du-DevopsДокумент8 страниц05 - Les-Bonnes-Pratiques-Du-DevopsChristian BiboueОценок пока нет
- Add A HeadingДокумент10 страницAdd A HeadingYassine El jabriОценок пока нет
- Cours-Systeme D Exploitation SeДокумент50 страницCours-Systeme D Exploitation SemahrazaekОценок пока нет
- Génie Logiciel Et Conduite de Projet: Plan Du CoursДокумент29 страницGénie Logiciel Et Conduite de Projet: Plan Du Courschristbest682Оценок пока нет
- Chap 2 Intro Au GLДокумент3 страницыChap 2 Intro Au GLALFRED FOKOUNG DOUOОценок пока нет
- Module 15 BizoiДокумент32 страницыModule 15 BizoiYASSINOS1988Оценок пока нет
- Introduction À La Critique de La Raison Pure de KantДокумент6 страницIntroduction À La Critique de La Raison Pure de KantisabelleОценок пока нет
- Methode Commentaire Series GeneralesДокумент3 страницыMethode Commentaire Series GeneralesrodrigueОценок пока нет
- TD N°1 Mecii SMP 14 15 PDFДокумент5 страницTD N°1 Mecii SMP 14 15 PDFTàHa SamihОценок пока нет
- GR 04 Trait S N°2Документ48 страницGR 04 Trait S N°2Salma SIRAJ-SANIОценок пока нет
- Genese 7Документ6 страницGenese 7Muriel Angele Sire JulesОценок пока нет
- Un Commentaire Mystique Du CoranДокумент7 страницUn Commentaire Mystique Du CoranSo' FineОценок пока нет
- Démasquer PerversitéДокумент25 страницDémasquer PerversitépsyncoenligneОценок пока нет
- L'asymétrie Des Membranes BiologiquesДокумент14 страницL'asymétrie Des Membranes Biologiquessafiadjili100% (2)
- Rapport 2020 MRC Droits de Lhomme Et GouvernanceДокумент71 страницаRapport 2020 MRC Droits de Lhomme Et Gouvernancedingue delleОценок пока нет
- Mechanisme de LectureДокумент51 страницаMechanisme de Lectureismail39 orthoОценок пока нет
- Etude de La Contamination Des Cathéters Isolés Des Hôpitaux de Bejaia Et de Jijel PDFДокумент38 страницEtude de La Contamination Des Cathéters Isolés Des Hôpitaux de Bejaia Et de Jijel PDFfadelaОценок пока нет
- Une Si Longue Lettre 34Документ5 страницUne Si Longue Lettre 34Sokhna maï GueyeОценок пока нет
- Deficits Immunitaires-210314-Def Luc MouthonДокумент41 страницаDeficits Immunitaires-210314-Def Luc MouthonLeonel TamaОценок пока нет
- Formation A La Technique Des Ventouses Cupping Therapy HijamaДокумент3 страницыFormation A La Technique Des Ventouses Cupping Therapy HijamasoffiaОценок пока нет
- Les Images Classificatrices (J.-C. Schmitt)Документ32 страницыLes Images Classificatrices (J.-C. Schmitt)AdsoОценок пока нет
- Monuments en TunisieДокумент5 страницMonuments en Tunisielibrary rahalОценок пока нет
- Alchimie Occidentale Et Alchimie Chinoise (Article)Документ15 страницAlchimie Occidentale Et Alchimie Chinoise (Article)drago_rosso100% (2)
- Dialoghi Dei Morti Di LucianoДокумент130 страницDialoghi Dei Morti Di LucianoPiero MancusoОценок пока нет
- Juste La Fin GT Pour DissertДокумент2 страницыJuste La Fin GT Pour DissertnoelladelironОценок пока нет
- Dialnet LaLitteratureCommeVoieDaccesALaCulture 5634878Документ29 страницDialnet LaLitteratureCommeVoieDaccesALaCulture 5634878Scoala Gimnaziala MargineniОценок пока нет
- ANAËL - 19 Juin 2010 - Autres DimensionsДокумент5 страницANAËL - 19 Juin 2010 - Autres DimensionsAndré MAОценок пока нет
- Langage Ecole Maternelle BouysseДокумент11 страницLangage Ecole Maternelle BouysseTheLookinesisОценок пока нет
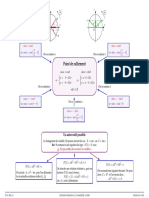
- Point de Ralliement: Cos A Sin B Sin A Cos BДокумент1 страницаPoint de Ralliement: Cos A Sin B Sin A Cos BMoūhvmĕd MūstfaОценок пока нет
- Algebre Lineaire Et Geometrie Des Polyno PDFДокумент11 страницAlgebre Lineaire Et Geometrie Des Polyno PDFSat KoosОценок пока нет
- Vers L'abîme ?, D'edgar MorinДокумент9 страницVers L'abîme ?, D'edgar MorinHerne Editions100% (2)
- Effet Hypoglycémiant Des Feuilles de Papaye Carica Chez Les Rats DiabétiquesДокумент13 страницEffet Hypoglycémiant Des Feuilles de Papaye Carica Chez Les Rats DiabétiquesNawel Baz100% (3)
- Études Sur Marx Et Hegel by Jean HyppoliteДокумент203 страницыÉtudes Sur Marx Et Hegel by Jean HyppoliteAl IochaОценок пока нет
- Fondements de SécuritéДокумент18 страницFondements de SécuritéYassine Brahmi100% (1)