Вам также может понравиться
- OFDM Simulation EE810Документ18 страницOFDM Simulation EE810Ashique Mahmood100% (1)
- Lets Discuss (How, What and Why) : 16 QAM Simulation in MATLABДокумент7 страницLets Discuss (How, What and Why) : 16 QAM Simulation in MATLABpreetik917Оценок пока нет
- JPEG Compression: CSC361/661 Spring 2002 Burg/WongДокумент16 страницJPEG Compression: CSC361/661 Spring 2002 Burg/Wongmahajan777Оценок пока нет
- Tornado Codes and Luby Transform Codes PDFДокумент12 страницTornado Codes and Luby Transform Codes PDFpathmakerpkОценок пока нет
- Convolution CodesДокумент14 страницConvolution CodeskrishnaОценок пока нет
- Multimedia Assignment2Документ5 страницMultimedia Assignment2bandishtiОценок пока нет
- Matlab PDFДокумент2 страницыMatlab PDFpathmakerpkОценок пока нет
- Channel Coding: Version 2 ECE IIT, KharagpurДокумент8 страницChannel Coding: Version 2 ECE IIT, KharagpurHarshaОценок пока нет
- Jpeg PDFДокумент9 страницJpeg PDFAvinashKumarОценок пока нет
- HasanДокумент8 страницHasansumeiranОценок пока нет
- Software-Defined Radio Lab 2: Data Modulation and TransmissionДокумент8 страницSoftware-Defined Radio Lab 2: Data Modulation and TransmissionpaulCGОценок пока нет
- VLSI ImageCompression EncryptionReadДокумент5 страницVLSI ImageCompression EncryptionReadqsashutoshОценок пока нет
- Codes Decoding: Design and Analysis: Feng Lu Chuan Heng Foh, Jianfei Cai and Liang-Tien ChiaДокумент5 страницCodes Decoding: Design and Analysis: Feng Lu Chuan Heng Foh, Jianfei Cai and Liang-Tien ChiaViet Tuan NguyenОценок пока нет
- Chapter 8-b Lossy Compression AlgorithmsДокумент18 страницChapter 8-b Lossy Compression AlgorithmsfarshoukhОценок пока нет
- Sistem Multimedia: Kompresi Data: Risnandar, Ph.D. Fakultas Ilmu Komputer Upn Veteran JakartaДокумент72 страницыSistem Multimedia: Kompresi Data: Risnandar, Ph.D. Fakultas Ilmu Komputer Upn Veteran JakartaRafid AmmarОценок пока нет
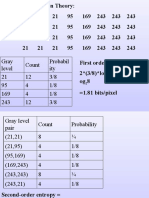
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Документ51 страницаGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaОценок пока нет
- Img CompressionДокумент15 страницImg CompressionchinthaladhanalaxmiОценок пока нет
- LDPC - Low Density Parity Check CodesДокумент6 страницLDPC - Low Density Parity Check CodespandyakaviОценок пока нет
- 3.multimedia Compression AlgorithmsДокумент23 страницы3.multimedia Compression Algorithmsaishu sillОценок пока нет
- An Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003Документ5 страницAn Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003Arini PartiwiОценок пока нет
- New SlideДокумент41 страницаNew SlideShekhar chanderОценок пока нет
- Rawan Ashraf 2019 - 13921 Comm. Lab5Документ17 страницRawan Ashraf 2019 - 13921 Comm. Lab5Rawan Ashraf Mohamed SolimanОценок пока нет
- Development of Wimax Physical Layer Building BlocksДокумент5 страницDevelopment of Wimax Physical Layer Building BlocksSandeep Kaur BhullarОценок пока нет
- Ece4001 Lab (1-11) 19bec1382Документ67 страницEce4001 Lab (1-11) 19bec1382Rishi ChanderОценок пока нет
- Source and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Документ17 страницSource and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Adarsh AnchiОценок пока нет
- Illuminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic CodesДокумент6 страницIlluminating The Structure Code and Decoder Parallel Concatenated Recursive Systematic Codessinne4Оценок пока нет
- Modulation Doping For Iterative Demapping of Bit-Interleaved Coded ModulationДокумент3 страницыModulation Doping For Iterative Demapping of Bit-Interleaved Coded ModulationabdulsahibОценок пока нет
- UWBin Fading ChannelsДокумент10 страницUWBin Fading Channelsneek4uОценок пока нет
- Lecture 7 JPEG CompressionДокумент28 страницLecture 7 JPEG CompressiondaveОценок пока нет
- Comparison of Convolutional Codes With Block CodesДокумент5 страницComparison of Convolutional Codes With Block CodesEminent AymeeОценок пока нет
- Sequential Decoding by Stack AlgorithmДокумент9 страницSequential Decoding by Stack AlgorithmRam Chandram100% (1)
- NG - Argument Reduction For Huge Arguments: Good To The Last BitДокумент8 страницNG - Argument Reduction For Huge Arguments: Good To The Last BitDerek O'ConnorОценок пока нет
- Convolutional CodeДокумент15 страницConvolutional CodeDhivya LakshmiОценок пока нет
- A L D I S HW/SW C - D: Shun-Wen ChengДокумент6 страницA L D I S HW/SW C - D: Shun-Wen Chengmorvarid7980Оценок пока нет
- System Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsДокумент8 страницSystem Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsanchisanОценок пока нет
- Ece4001exp1 6Документ43 страницыEce4001exp1 6Dev MehtaОценок пока нет
- Spreading Codes in Cdma Detection: Eastern Mediterranean University July 2003Документ24 страницыSpreading Codes in Cdma Detection: Eastern Mediterranean University July 2003Alex BadeaОценок пока нет
- Performance Evaluation For Convolutional Codes Using Viterbi DecodingДокумент6 страницPerformance Evaluation For Convolutional Codes Using Viterbi Decodingbluemoon1172Оценок пока нет
- Convolution Codes: 1.0 PrologueДокумент26 страницConvolution Codes: 1.0 PrologueGourgobinda Satyabrata AcharyaОценок пока нет
- Error Control Coding3Документ24 страницыError Control Coding3DuongMinhSOnОценок пока нет
- Viterbi DecodingДокумент4 страницыViterbi DecodingGaurav NavalОценок пока нет
- Efficient Implementation of Low Power 2-D DCT ArchitectureДокумент6 страницEfficient Implementation of Low Power 2-D DCT ArchitectureIJMERОценок пока нет
- JPEGДокумент29 страницJPEGRakesh InaniОценок пока нет
- 3D Turbo CodesДокумент13 страниц3D Turbo Codestvrpolicemobilemissing0Оценок пока нет
- Kufa Journal of Engineering, Vol.3, No.2, 2012Документ16 страницKufa Journal of Engineering, Vol.3, No.2, 2012Ali JaberОценок пока нет
- Convolutional Codes Turbo Codes LDPC CodesДокумент49 страницConvolutional Codes Turbo Codes LDPC CodesveerutheprinceОценок пока нет
- DSP Lab Manual-Msc2Документ103 страницыDSP Lab Manual-Msc2AswathyPrasadОценок пока нет
- Low-Complexity Low-Latency Architecture For Identical of Data Encoded With Hard Systematic Error-Correcting CodesДокумент104 страницыLow-Complexity Low-Latency Architecture For Identical of Data Encoded With Hard Systematic Error-Correcting CodesJaya SwaroopОценок пока нет
- Comparative Study of Turbo Codes in AWGN Channel Using MAP and SOVA DecodingДокумент14 страницComparative Study of Turbo Codes in AWGN Channel Using MAP and SOVA Decodingyemineniraj33Оценок пока нет
- Amil NIS: Department of Radioelectronics Faculty of Electrical Engineering Czech Tech. University in PragueДокумент30 страницAmil NIS: Department of Radioelectronics Faculty of Electrical Engineering Czech Tech. University in PragueAr FatimzahraОценок пока нет
- Turbo Codes For Deep-Space Communications: January 1994Документ12 страницTurbo Codes For Deep-Space Communications: January 1994Abdallah BalahaОценок пока нет
- TG10 2Документ5 страницTG10 2m0hmdОценок пока нет
- Experimental Verification of Linear Block Codes and Hamming Codes Using Matlab CodingДокумент17 страницExperimental Verification of Linear Block Codes and Hamming Codes Using Matlab CodingBhavani KandruОценок пока нет
- Compression IIДокумент51 страницаCompression IIJagadeesh NaniОценок пока нет
- Novel Image Compression Using Modified DCT: Telagarapu PrabhakarДокумент5 страницNovel Image Compression Using Modified DCT: Telagarapu PrabhakarPrabhakarОценок пока нет
- Channel Coding Techniques in TetraДокумент12 страницChannel Coding Techniques in TetraAdnan Shehzad100% (1)