Вам также может понравиться
- Hi-Fi Stereo Handbook - William F. BoyceДокумент401 страницаHi-Fi Stereo Handbook - William F. BoyceMeyer Mendel100% (1)
- Recording Classical PDFДокумент181 страницаRecording Classical PDFLeo Micro100% (3)
- Teaching Students With Autism A Resource Guide For SchoolsДокумент141 страницаTeaching Students With Autism A Resource Guide For SchoolspsihologulbvОценок пока нет
- Fluency in The ClassroomДокумент209 страницFluency in The ClassroomTấn Tài VõОценок пока нет
- Awaken The Giant WithinДокумент25 страницAwaken The Giant WithinHenrique Cavagnoli100% (1)
- Leadership in Maritime /BRM/ERMДокумент34 страницыLeadership in Maritime /BRM/ERMPanagiotis KtenasОценок пока нет
- Assessment Summary-DasДокумент6 страницAssessment Summary-Dasapi-283942000Оценок пока нет
- Hi-Fi Stereo Handbook William F. Boyce (1970) PDFДокумент291 страницаHi-Fi Stereo Handbook William F. Boyce (1970) PDFjimmy67music100% (1)
- Lecture 9 - Speech RecognitionДокумент65 страницLecture 9 - Speech RecognitionViswakarma ChakravarthyОценок пока нет
- S6 Emotion Regulation StrategiesДокумент4 страницыS6 Emotion Regulation StrategiesRăzvan-Andrei ZaicaОценок пока нет
- Demon Analysis PDFДокумент21 страницаDemon Analysis PDFBùi Trường Giang100% (1)
- RA English07Документ28 страницRA English07mcastilho100% (2)
- Child and Adolescent Development (Revised)Документ139 страницChild and Adolescent Development (Revised)Kelly Mayo80% (5)
- Surround Miking (DPA)Документ21 страницаSurround Miking (DPA)TVCОценок пока нет
- Ethical Decision-Making TheoryДокумент23 страницыEthical Decision-Making Theoryhendrik silalahiОценок пока нет
- Audio Bandwidth Extension: Application of Psychoacoustics, Signal Processing and Loudspeaker DesignОт EverandAudio Bandwidth Extension: Application of Psychoacoustics, Signal Processing and Loudspeaker DesignОценок пока нет
- Sow English Year 2 2022-2023 by RozayusacademyДокумент12 страницSow English Year 2 2022-2023 by RozayusacademyrphsekolahrendahОценок пока нет
- ISMIR 2019 Tutorial - Waveform-Based Music Processing With Deep LearningДокумент152 страницыISMIR 2019 Tutorial - Waveform-Based Music Processing With Deep LearningYue Hann ChinОценок пока нет
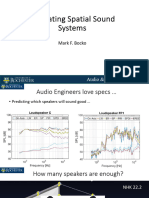
- Evaluating Spatial Sound SystemsДокумент32 страницыEvaluating Spatial Sound SystemsMark BockoОценок пока нет
- SSP 5 3 Music CodingДокумент48 страницSSP 5 3 Music CodingGabor GerebОценок пока нет
- Evaluating Spatial Sound SystemsДокумент32 страницыEvaluating Spatial Sound SystemsMark BockoОценок пока нет
- Materials 16 01879 v2Документ23 страницыMaterials 16 01879 v2slavceОценок пока нет
- Lesson02 PDFДокумент23 страницыLesson02 PDFMehnaz Baloch100% (1)
- Chapter 1 - NoiseДокумент21 страницаChapter 1 - NoisepingpaОценок пока нет
- Pitch TrackingДокумент17 страницPitch TrackingMatthias StrassmüllerОценок пока нет
- New Count The DotsДокумент1 страницаNew Count The Dotslin ee100% (1)
- Chapter6 - SPEECH SIGNAL PROCESSINGДокумент54 страницыChapter6 - SPEECH SIGNAL PROCESSINGQuyền PhanОценок пока нет
- Trends in Audio and Acoustic Signal ProcessingДокумент35 страницTrends in Audio and Acoustic Signal ProcessingAl StringsОценок пока нет
- Cocktail Party Problem As Binary Classification: Deliang WangДокумент39 страницCocktail Party Problem As Binary Classification: Deliang WangSumit HukmaniОценок пока нет
- Echo Analysis For Voice Over IP: Updated: Jul 26, 2001Документ29 страницEcho Analysis For Voice Over IP: Updated: Jul 26, 2001徐得胜Оценок пока нет
- Measures and Sources of Sound: Professor Phil JosephДокумент21 страницаMeasures and Sources of Sound: Professor Phil JosephBelaliaОценок пока нет
- Speech Signal Analysis and Coding: Dr. Arun KumarДокумент52 страницыSpeech Signal Analysis and Coding: Dr. Arun KumarHoang Duong Quy RomОценок пока нет
- N13 - What Is DB Weighting NC RC - 14nov2021Документ60 страницN13 - What Is DB Weighting NC RC - 14nov2021mohamad isaОценок пока нет
- STUDENTS Lecture 3 (Chapter 2)Документ29 страницSTUDENTS Lecture 3 (Chapter 2)Sirine AjourОценок пока нет
- Convention Paper 5565: Audio Engineering SocietyДокумент18 страницConvention Paper 5565: Audio Engineering SocietycontatoОценок пока нет
- Digital Signal Processing: CourseДокумент47 страницDigital Signal Processing: CourseYasashiRikaiОценок пока нет
- Psycho AcousticsДокумент64 страницыPsycho Acousticsphoenixdefuhrer3Оценок пока нет
- Room Acoustics: CMSC 828D / Spring 2006Документ36 страницRoom Acoustics: CMSC 828D / Spring 2006Krishna RenduchintalaОценок пока нет
- BisingДокумент26 страницBisingannitaОценок пока нет
- Time-Frequency Signal Processing: A Review With Recent ResultsДокумент11 страницTime-Frequency Signal Processing: A Review With Recent ResultsMehdi Chames Eddinne LAYESОценок пока нет
- Mavlas SlidesДокумент554 страницыMavlas Slidesitamar amraniОценок пока нет
- Webinar Random VibrationДокумент33 страницыWebinar Random VibrationAditya KulkarniОценок пока нет
- January 2021 Acoustics Basics For Hvac R DesignersДокумент31 страницаJanuary 2021 Acoustics Basics For Hvac R Designersaashiqueo2Оценок пока нет
- Acoustics of Speech: Julia Hirschberg CS 4706Документ29 страницAcoustics of Speech: Julia Hirschberg CS 4706jcmsОценок пока нет
- Yamada 2006Документ14 страницYamada 2006Sepya SodiqОценок пока нет
- Periodicity and Pitch: Importance of Fine Structure Representation in HearingДокумент47 страницPeriodicity and Pitch: Importance of Fine Structure Representation in HearingIsrael MarquezОценок пока нет
- Raw Strings ManualДокумент22 страницыRaw Strings ManualClément GillauxОценок пока нет
- Signals and Systems EE 3302: DR Pete Bernardin Telecommunications EngineeringДокумент9 страницSignals and Systems EE 3302: DR Pete Bernardin Telecommunications Engineeringnadia719Оценок пока нет
- Pitch Tracking: 1. Pitch Tracking 2. Spectral Approaches 3. Time Domain 4. Example AlgorithmsДокумент18 страницPitch Tracking: 1. Pitch Tracking 2. Spectral Approaches 3. Time Domain 4. Example AlgorithmsSandeep Reddy KankanalaОценок пока нет
- Lectures 7-8 Winter 2012Документ73 страницыLectures 7-8 Winter 2012wellhellothere123Оценок пока нет
- Hearing 2018Документ47 страницHearing 2018wajiha.needafatimaОценок пока нет
- FT LDB300 Software-Export 05-15Документ4 страницыFT LDB300 Software-Export 05-15Khalid JakirОценок пока нет
- Yamaha SpeakersДокумент4 страницыYamaha SpeakersalayshahОценок пока нет
- Brief Analysis of Sounds Using A SmartphoneДокумент3 страницыBrief Analysis of Sounds Using A Smartphonesyahlan FairuzОценок пока нет
- TRANS 4 - Audiology 2021 Dr. DalandagДокумент9 страницTRANS 4 - Audiology 2021 Dr. DalandagNestle NgoОценок пока нет
- 2020 - S2 - MEC4444 - Lecture Notes (Week 1 - Loudness) PDFДокумент48 страниц2020 - S2 - MEC4444 - Lecture Notes (Week 1 - Loudness) PDFSaadat BilalОценок пока нет
- Environmental Sound Recognition and ClassificationДокумент36 страницEnvironmental Sound Recognition and ClassificationmounamalarОценок пока нет
- An Alternative Design For Loudspeakers Using The Non-Linear Interaction of Sound WavesДокумент10 страницAn Alternative Design For Loudspeakers Using The Non-Linear Interaction of Sound Wavesakankshamishra150Оценок пока нет
- Sound-Intensity en V20-1 WebДокумент4 страницыSound-Intensity en V20-1 WebPaul GálvezОценок пока нет
- Linear PredictionДокумент94 страницыLinear PredictionAndreas RousalisОценок пока нет
- SignalДокумент5 страницSignalSanket SapateОценок пока нет
- CH 3Документ71 страницаCH 3CH LОценок пока нет
- Sofra - ASET-US-2018 - Kinetics Noise ControlДокумент55 страницSofra - ASET-US-2018 - Kinetics Noise ControlLaura SalasОценок пока нет
- TrendsBeamforming ThomeniusДокумент113 страницTrendsBeamforming ThomeniusMai Thanh SơnОценок пока нет
- TutorialsДокумент1 страницаTutorialsNickOlОценок пока нет
- Two-Way Passive Cinema Surround Loudspeaker: Key FeaturesДокумент2 страницыTwo-Way Passive Cinema Surround Loudspeaker: Key FeaturesDhivaakar KrishnanОценок пока нет
- Digital SoundДокумент37 страницDigital SoundNorisalwaani Mohd JidinОценок пока нет
- Lesson 9 - Perception of SoundДокумент62 страницыLesson 9 - Perception of SoundIzzat IkramОценок пока нет
- Audio Software Lesson ReportДокумент6 страницAudio Software Lesson ReportEzekiel AmnonОценок пока нет
- Red BeansДокумент126 страницRed BeansmcastilhoОценок пока нет
- The Westcoast Wire: An Upright Solution For CP KidsДокумент5 страницThe Westcoast Wire: An Upright Solution For CP KidsmcastilhoОценок пока нет
- Corrections FinalДокумент7 страницCorrections FinalmcastilhoОценок пока нет
- 100 Children's Specialty Clinics: July 2008 100-1Документ18 страниц100 Children's Specialty Clinics: July 2008 100-1mcastilhoОценок пока нет
- Office of Inspector General: Medicare Payments For OrthoticsДокумент30 страницOffice of Inspector General: Medicare Payments For OrthoticsmcastilhoОценок пока нет
- Ruby On RailsДокумент53 страницыRuby On RailsmcastilhoОценок пока нет
- Dynamic Macroprogramming of Wireless Sensor Networks With Mobile AgentsДокумент6 страницDynamic Macroprogramming of Wireless Sensor Networks With Mobile AgentsmcastilhoОценок пока нет
- Adding Meta TagsДокумент3 страницыAdding Meta Tagsmcastilho0% (1)
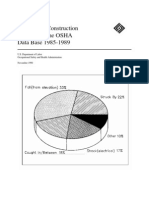
- Analysis of Construction Fatalities - The OSHA Data Base 1985-1989Документ84 страницыAnalysis of Construction Fatalities - The OSHA Data Base 1985-1989mcastilho100% (1)
- Haga 1220Документ77 страницHaga 1220mcastilhoОценок пока нет
- Spywarehome 0905Документ8 страницSpywarehome 0905mcastilhoОценок пока нет
- Implementing Functional Languages On Object-Oriented Virtual MachinesДокумент20 страницImplementing Functional Languages On Object-Oriented Virtual MachinesmcastilhoОценок пока нет
- SMAMem LДокумент4 страницыSMAMem LmcastilhoОценок пока нет
- Eduardo Peixoto Neves: ProfileДокумент2 страницыEduardo Peixoto Neves: ProfilemcastilhoОценок пока нет
- Razavi Et Al Oopsla06 PosterДокумент3 страницыRazavi Et Al Oopsla06 PostermcastilhoОценок пока нет
- Quality Early Learning - : Key To School SuccessДокумент190 страницQuality Early Learning - : Key To School SuccessmcastilhoОценок пока нет
- Trading Tasks: A Simple Theory of O Shoring: Gene M. Grossman and Esteban Rossi-HansbergДокумент37 страницTrading Tasks: A Simple Theory of O Shoring: Gene M. Grossman and Esteban Rossi-HansbergmcastilhoОценок пока нет
- Mediakit 08Документ9 страницMediakit 08mcastilhoОценок пока нет
- Teaching MATH Content Thru Explicit Instruction FINAL COPY Edited VersionДокумент59 страницTeaching MATH Content Thru Explicit Instruction FINAL COPY Edited VersionRomel Bayaban100% (1)
- Week 01 Lesson Plan Grade 6 The Believer Between Gratitude and PatienceДокумент2 страницыWeek 01 Lesson Plan Grade 6 The Believer Between Gratitude and PatienceAhmad SaadОценок пока нет
- Assignment01-PIX 2001 Sem 1 2021-22Документ2 страницыAssignment01-PIX 2001 Sem 1 2021-22Khairul HannanОценок пока нет
- On Human Nature: The Mind-Body Problem: Dr. Noorunnisa Khan Session 9Документ23 страницыOn Human Nature: The Mind-Body Problem: Dr. Noorunnisa Khan Session 9Maryam AslamОценок пока нет
- Graphic OrganizersДокумент6 страницGraphic Organizersapi-332490117Оценок пока нет
- Relationship Between Learning Styles and Content Based Academic Achievement Among Tertiary Level StudentsДокумент8 страницRelationship Between Learning Styles and Content Based Academic Achievement Among Tertiary Level StudentsNining Sri AstutiОценок пока нет
- Chapter II: Listening: I. Course DescriptionДокумент16 страницChapter II: Listening: I. Course DescriptionJohn Marlo DolosoОценок пока нет
- Richard Kitchener - Genetic Epistemology, Normative Epistemology, and PsychologismДокумент25 страницRichard Kitchener - Genetic Epistemology, Normative Epistemology, and PsychologismIva ShaneОценок пока нет
- Community Language Learning 3Документ8 страницCommunity Language Learning 3Amal OmarОценок пока нет
- Perspective of The Self This Unit Gives Highlight To The Concepts and Nature of Understanding The SelfДокумент23 страницыPerspective of The Self This Unit Gives Highlight To The Concepts and Nature of Understanding The SelfAnn Nicole De JesusОценок пока нет
- Problem Solving Concepts Theories PDFДокумент4 страницыProblem Solving Concepts Theories PDFfallen anderson100% (1)
- Philippine Professional Standards For Teachers OutlineДокумент15 страницPhilippine Professional Standards For Teachers OutlineJamela Jade T. BonostroОценок пока нет
- Teaching Approaches & Methods: Presented By: Kirk John TonidoДокумент53 страницыTeaching Approaches & Methods: Presented By: Kirk John Tonidoanalyn100% (2)
- Ejemplos de Fichas Bibliográficas para Temas y para Estudios - MADДокумент4 страницыEjemplos de Fichas Bibliográficas para Temas y para Estudios - MADGina Lisseth Tapia ToroОценок пока нет
- HUMS04 Unit I Lesson 2 - LectureДокумент2 страницыHUMS04 Unit I Lesson 2 - LectureMai GeeОценок пока нет
- Saccades Test: Kutoli, Senerita and JavaДокумент12 страницSaccades Test: Kutoli, Senerita and JavaTori Kehlani TanieluОценок пока нет
- Consumer Decision Making and Beyond: Consumer Behavior, Schiffman & KanukДокумент37 страницConsumer Decision Making and Beyond: Consumer Behavior, Schiffman & KanukKhokhar ZadaОценок пока нет
- Unit 1: The Place of Science in The Early Years: Module 1: What Initial Information Should I Know To Teach Science?Документ7 страницUnit 1: The Place of Science in The Early Years: Module 1: What Initial Information Should I Know To Teach Science?Dlanor AvadecОценок пока нет
- Understanding The Self: Defining The Self: Personal and Developmental Perspectives On Self and IdentityДокумент18 страницUnderstanding The Self: Defining The Self: Personal and Developmental Perspectives On Self and IdentityChloe LibosadaОценок пока нет
- UTS ResearchДокумент12 страницUTS ResearchAntholyn Thian JayaОценок пока нет
- Systems PsychologyДокумент5 страницSystems Psychologyshanna_heenaОценок пока нет