Вам также может понравиться
- Smart Meter Data AnalysisДокумент306 страницSmart Meter Data AnalysisGurpinder Singh100% (1)
- Z TableДокумент2 страницыZ Tablejeffe333100% (1)
- 03 Chap03 ReviewOfLinearRegressionДокумент31 страница03 Chap03 ReviewOfLinearRegressionamelОценок пока нет
- Regression: Dr. Agustinus Suryantoro, M.SДокумент31 страницаRegression: Dr. Agustinus Suryantoro, M.SVikha Suryo KharismawanОценок пока нет
- APznzaazpaxdEZySF0f1zeSdA1pP9fTu1S78qA NZiKlyKnL 0CF6EBZBUtsxgvДокумент3 страницыAPznzaazpaxdEZySF0f1zeSdA1pP9fTu1S78qA NZiKlyKnL 0CF6EBZBUtsxgvsovandy2004Оценок пока нет
- Dummy Variable FinalДокумент14 страницDummy Variable FinalMihir Ranjan NayakОценок пока нет
- Lecture10 Regression2 TS PDFДокумент22 страницыLecture10 Regression2 TS PDFsnoozermanОценок пока нет
- Lecture On Non-Parametric StatisticsДокумент16 страницLecture On Non-Parametric StatisticsRyan BondocОценок пока нет
- Module 5.2 - Anova and AncovaДокумент10 страницModule 5.2 - Anova and Ancovagiest4lifeОценок пока нет
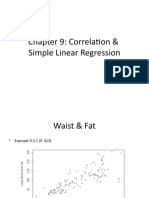
- Chapter 9: Correlation & Simple Linear RegressionДокумент17 страницChapter 9: Correlation & Simple Linear RegressionKadir OzcanОценок пока нет
- Econometrics For FinanceДокумент54 страницыEconometrics For Financenegussie birieОценок пока нет
- CH 123Документ63 страницыCH 123Talha ImtiazОценок пока нет
- Assignment - Week 10Документ6 страницAssignment - Week 10Nabella Roma DesiОценок пока нет
- Practice Midterm2 Fall2011Документ9 страницPractice Midterm2 Fall2011truongpham91Оценок пока нет
- T-Tests, Anova and Regression: Lorelei Howard and Nick Wright MFD 2008Документ37 страницT-Tests, Anova and Regression: Lorelei Howard and Nick Wright MFD 2008kapil1248Оценок пока нет
- Business Analytics Assignment: Submitted ToДокумент18 страницBusiness Analytics Assignment: Submitted Tosoumya MОценок пока нет
- 317 Final ExamДокумент6 страниц317 Final Examdadu89Оценок пока нет
- Statistics For Decision Making: ANOVA: Analysis of VarianceДокумент32 страницыStatistics For Decision Making: ANOVA: Analysis of VarianceAmit AdmuneОценок пока нет
- Machine Learning and Linear RegressionДокумент55 страницMachine Learning and Linear RegressionKapil Chandel100% (1)
- Sonek Linear Regression NotesДокумент11 страницSonek Linear Regression NotesAlfredОценок пока нет
- Chap3 - Multiple RegressionДокумент56 страницChap3 - Multiple RegressionNguyễn Lê Minh AnhОценок пока нет
- QTA InterpretationДокумент17 страницQTA InterpretationMuhammad HarisОценок пока нет
- Mp11 QuantitativeHypothesis Testing 7e2016sekaran &bougie-Ch15Документ39 страницMp11 QuantitativeHypothesis Testing 7e2016sekaran &bougie-Ch15Diah Desy NataliaОценок пока нет
- Non-Parametric Tests and ANOVAДокумент26 страницNon-Parametric Tests and ANOVACollins MuseraОценок пока нет
- The Simple Linear Regression Model and CorrelationДокумент64 страницыThe Simple Linear Regression Model and CorrelationRajesh DwivediОценок пока нет
- CH 4 Multiple Regression ModelsДокумент28 страницCH 4 Multiple Regression Modelspkj009Оценок пока нет
- PPT 08 - Quantitative Data AnalysisДокумент51 страницаPPT 08 - Quantitative Data AnalysisZakaria AliОценок пока нет
- Multiple RegressionДокумент63 страницыMultiple RegressionchilotawОценок пока нет
- Hypothesis Tests, Confidence Intervals, and Bootstrapping: Business Statistics 41000Документ54 страницыHypothesis Tests, Confidence Intervals, and Bootstrapping: Business Statistics 41000Manab ChetiaОценок пока нет
- Basic Econometrics Revision - Econometric ModellingДокумент65 страницBasic Econometrics Revision - Econometric ModellingTrevor ChimombeОценок пока нет
- Stat 473-573 NotesДокумент139 страницStat 473-573 NotesArkadiusz Michael BarОценок пока нет
- Ch01 02 03 Final BДокумент63 страницыCh01 02 03 Final BMaria Cristina RossiОценок пока нет
- Research PaperДокумент20 страницResearch PaperBianca ValenciaОценок пока нет
- Estimating Demand FunctionДокумент45 страницEstimating Demand FunctionManisha AdliОценок пока нет
- Nonparametric Statistics and Model Selection: 5.1 Estimating Distributions and Distribution-Free TestsДокумент10 страницNonparametric Statistics and Model Selection: 5.1 Estimating Distributions and Distribution-Free TestshalijahОценок пока нет
- BivariateДокумент28 страницBivariateVikas SainiОценок пока нет
- Econometrics PracticalДокумент13 страницEconometrics Practicalakashit21a854Оценок пока нет
- Exam June 2013 Answers TotalДокумент11 страницExam June 2013 Answers Totalkickbartram2Оценок пока нет
- Eco 3Документ68 страницEco 3Nebiyu WoldesenbetОценок пока нет
- 6.3 SSK5210 Parametric Statistical Testing - Analysis of Variance LR and Correlation - 2Документ39 страниц6.3 SSK5210 Parametric Statistical Testing - Analysis of Variance LR and Correlation - 2Sarveshwaran BalasundaramОценок пока нет
- Why Do We Need Statistics? - P Values - T-Tests - Anova - Correlation33Документ37 страницWhy Do We Need Statistics? - P Values - T-Tests - Anova - Correlation33sikunaОценок пока нет
- The F-Ratio in RegressionДокумент7 страницThe F-Ratio in RegressionMukesh KumarОценок пока нет
- Bivariate Regression Analysis: The Beginning of Many Types of RegressionДокумент40 страницBivariate Regression Analysis: The Beginning of Many Types of RegressionAshish AgarwalОценок пока нет
- Classical Linear Regression Model (CLRM)Документ68 страницClassical Linear Regression Model (CLRM)Nigussie BerhanuОценок пока нет
- Interpretation of RegressionДокумент6 страницInterpretation of RegressionnagpaloshankОценок пока нет
- Class X: Bivariate Association & The Chi Square TestДокумент27 страницClass X: Bivariate Association & The Chi Square TestNikita LotwalaОценок пока нет
- CorrelationДокумент52 страницыCorrelationasadОценок пока нет
- Chapter 3 EconometricsДокумент34 страницыChapter 3 EconometricsAshenafi ZelekeОценок пока нет
- Tarea 10nestadisticaДокумент9 страницTarea 10nestadisticacamilomelgarejo92Оценок пока нет
- INTRODUCTIONДокумент5 страницINTRODUCTIONAkshat TiwariОценок пока нет
- Review of Multiple Regression: Assumptions About Prior Knowledge. This Handout Attempts To Summarize and SynthesizeДокумент12 страницReview of Multiple Regression: Assumptions About Prior Knowledge. This Handout Attempts To Summarize and SynthesizeKiran PoudelОценок пока нет
- Chapter 2 SLRMДокумент40 страницChapter 2 SLRMmerondemekets12347Оценок пока нет
- Ordinary Least SquaresДокумент21 страницаOrdinary Least SquaresRahulsinghooooОценок пока нет
- Study CaseДокумент7 страницStudy CaseArko Setiyo PrabowoОценок пока нет
- Chapter 3Документ36 страницChapter 3feyisaabera19Оценок пока нет
- 7,8-Simple Regression PDFДокумент47 страниц7,8-Simple Regression PDFKevin HyunОценок пока нет
- Ermi Stat LL CH 4Документ32 страницыErmi Stat LL CH 4newaybeyene5Оценок пока нет
- Probability Density Function:: Time Again. More Closely The Histogram Will Approximate The PDFДокумент46 страницProbability Density Function:: Time Again. More Closely The Histogram Will Approximate The PDFSai KiranОценок пока нет
- Business Statistics 41000: Hypothesis TestingДокумент34 страницыBusiness Statistics 41000: Hypothesis Testinguday369Оценок пока нет
- Module-2 - Assessing Accuracy of ModelДокумент24 страницыModule-2 - Assessing Accuracy of ModelRoudra ChakrabortyОценок пока нет
- Eco No MetricsДокумент4 страницыEco No MetricsdazzlingbasitОценок пока нет
- Introduction Into ChemistryДокумент11 страницIntroduction Into ChemistryTumabang DivineОценок пока нет
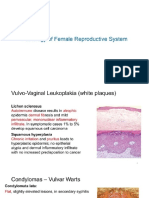
- Pathologies of The Female Reproductive SystemДокумент40 страницPathologies of The Female Reproductive SystemTumabang DivineОценок пока нет
- CELL BIOLOGY AND HISTOLOGY Handout 1Документ36 страницCELL BIOLOGY AND HISTOLOGY Handout 1Tumabang DivineОценок пока нет
- PARASITOLOGY NotesДокумент36 страницPARASITOLOGY NotesTumabang DivineОценок пока нет
- Anova TestДокумент32 страницыAnova TestTumabang DivineОценок пока нет
- Chi Square Test Lecture Note Final 2018Документ19 страницChi Square Test Lecture Note Final 2018Tumabang DivineОценок пока нет
- Abubakar KardiДокумент44 страницыAbubakar KardiTumabang DivineОценок пока нет
- PPH 707 Summary of The Types of Variables and Tutorial I, Jan 2020Документ3 страницыPPH 707 Summary of The Types of Variables and Tutorial I, Jan 2020Tumabang DivineОценок пока нет
- 2ND Sem Result Level 1Документ8 страниц2ND Sem Result Level 1Tumabang DivineОценок пока нет
- Admissions PG Programmes 2020Документ1 страницаAdmissions PG Programmes 2020Tumabang DivineОценок пока нет
- Employment Veri Cation Letter: 4158 New York Avenue, Fort Worth, TX, 76110 - (123) 1234567Документ2 страницыEmployment Veri Cation Letter: 4158 New York Avenue, Fort Worth, TX, 76110 - (123) 1234567Tumabang DivineОценок пока нет
- Non Parametric TestsДокумент43 страницыNon Parametric TestsTumabang Divine100% (1)
- Advanced Techniques in Diagnostic MicrobiologyДокумент14 страницAdvanced Techniques in Diagnostic MicrobiologyTumabang DivineОценок пока нет
- Introduction To Financial Statement AuditДокумент49 страницIntroduction To Financial Statement Auditgandara koОценок пока нет
- Specifications Indoor-Air-comfort v6 enДокумент25 страницSpecifications Indoor-Air-comfort v6 enelezmОценок пока нет
- Week 3 - Describing Numerical DataДокумент7 страницWeek 3 - Describing Numerical DatamarcОценок пока нет
- Critical Reasoning NotesДокумент21 страницаCritical Reasoning NotesrvundavalliОценок пока нет
- Outsourcing Mini LessonДокумент2 страницыOutsourcing Mini Lessonapi-270236691Оценок пока нет
- STA 577 Statistical Quality Control (Assignment 1)Документ6 страницSTA 577 Statistical Quality Control (Assignment 1)Atiqah JilisОценок пока нет
- Retake 522 Asm1Документ17 страницRetake 522 Asm1Trần Minh NhậtОценок пока нет
- Violence in The WorkplaceДокумент24 страницыViolence in The WorkplaceAlexander HodgeОценок пока нет
- Time Study2Документ68 страницTime Study2omkdikОценок пока нет
- Students' Experience and Evaluation of Community Pharmacy Internship in IraqДокумент9 страницStudents' Experience and Evaluation of Community Pharmacy Internship in Iraqsiti nadzirahОценок пока нет
- Bellaachia PDFДокумент4 страницыBellaachia PDFDr-Rabia AlmamalookОценок пока нет
- Audtheo Fbana AnswersДокумент8 страницAudtheo Fbana AnswersArian AmuraoОценок пока нет
- Dorothea Orem'S Self-Care Deficit Nursing Theory: By: Tracy Clarke & Jeanine GrossmanДокумент37 страницDorothea Orem'S Self-Care Deficit Nursing Theory: By: Tracy Clarke & Jeanine Grossmannapper67100% (2)
- Online FoodДокумент8 страницOnline Foodneha agrawalОценок пока нет
- The Teochew Chinese of ThailandДокумент7 страницThe Teochew Chinese of ThailandbijsshrjournalОценок пока нет
- Neuro MarketingДокумент166 страницNeuro MarketingAlen PeruskoОценок пока нет
- Lecture in EntrepreneurshipДокумент7 страницLecture in EntrepreneurshipAnonymous xl2Fs9R8wОценок пока нет
- Advancing The Nature of Bone.: Allofuse DBMДокумент2 страницыAdvancing The Nature of Bone.: Allofuse DBMEnrique S OcampoОценок пока нет
- MILMAaa InternshipДокумент85 страницMILMAaa InternshipMelvin BabuОценок пока нет
- Medical Device RequirementsДокумент25 страницMedical Device RequirementsiliyasОценок пока нет
- Performance Monitoring and Coaching FormДокумент7 страницPerformance Monitoring and Coaching FormEduardoAlejoZamoraJr.Оценок пока нет
- Proposal QUAL MoralesДокумент101 страницаProposal QUAL MoralesFrederick BaldemoroОценок пока нет
- Compassionate Sciences Inc NorthernAPPДокумент72 страницыCompassionate Sciences Inc NorthernAPPNew Jersey marijuana documentsОценок пока нет
- Mobile Money Adoption in A Fragile Economy: The Case of A Seven Year Failed Experiment in NigeriaДокумент10 страницMobile Money Adoption in A Fragile Economy: The Case of A Seven Year Failed Experiment in NigeriainventionjournalsОценок пока нет
- NORPLAN Tanzania BrochureДокумент20 страницNORPLAN Tanzania BrochureAnicet VincentОценок пока нет
- A Presentation: To NBA Appellate Committee MembersДокумент10 страницA Presentation: To NBA Appellate Committee Membersi sai ramОценок пока нет
- MumificationДокумент717 страницMumificationrafiya rahmanОценок пока нет
- PBB in MauritiusДокумент7 страницPBB in MauritiusnewmadproОценок пока нет