Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- Talent-Olympiad 9 Science SampleДокумент12 страницTalent-Olympiad 9 Science SampleFire GamingОценок пока нет
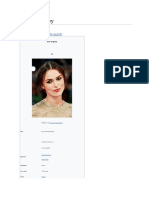
- Keira Knightley: Jump To Navigation Jump To SearchДокумент12 страницKeira Knightley: Jump To Navigation Jump To SearchCrina LupuОценок пока нет
- 7094 Bangladesh Studies: MARK SCHEME For The May/June 2011 Question Paper For The Guidance of TeachersДокумент11 страниц7094 Bangladesh Studies: MARK SCHEME For The May/June 2011 Question Paper For The Guidance of Teachersmstudy123456Оценок пока нет
- Norma Geral Astm Bronze Alumínio - b150b150m.19198Документ7 страницNorma Geral Astm Bronze Alumínio - b150b150m.19198EduardoОценок пока нет
- Wind LoadingДокумент18 страницWind LoadingStephen Ogalo100% (1)
- DocumentationДокумент44 страницыDocumentation19-512 Ratnala AshwiniОценок пока нет
- THE Ketofeed Diet Book v2Документ43 страницыTHE Ketofeed Diet Book v2jacosta12100% (1)
- Content Analysis of Tea BrandsДокумент49 страницContent Analysis of Tea BrandsHumaRiaz100% (1)
- Why Do Kashmiris Need Self-Determination?: UncategorizedДокумент16 страницWhy Do Kashmiris Need Self-Determination?: UncategorizedFarooq SiddiqiОценок пока нет
- Cinnamon RollДокумент1 страницаCinnamon RollMaria Manoa GantalaОценок пока нет
- 88 Year Old Man Missing in SC - Please ShareДокумент1 страница88 Year Old Man Missing in SC - Please ShareAmy WoodОценок пока нет
- Unit 4 Transistor Frequency ResponseДокумент6 страницUnit 4 Transistor Frequency ResponseShaina MabborangОценок пока нет
- Unseen Passage 2Документ6 страницUnseen Passage 2Vinay OjhaОценок пока нет
- Introduction To Regional PlanningДокумент27 страницIntroduction To Regional Planningadeeba siddiquiОценок пока нет
- Review of Related Literature and Related StudiesДокумент23 страницыReview of Related Literature and Related StudiesReynhard Dale100% (3)
- Rich Gas and Lean GasДокумент7 страницRich Gas and Lean GasManish GautamОценок пока нет
- Ultimate Prime Sieve - Sieve of ZakiyaДокумент23 страницыUltimate Prime Sieve - Sieve of ZakiyaJabari ZakiyaОценок пока нет
- Complex Poly (Lactic Acid) - Based - 1Документ20 страницComplex Poly (Lactic Acid) - Based - 1Irina PaslaruОценок пока нет
- GCG Damri SurabayaДокумент11 страницGCG Damri SurabayaEndang SusilawatiОценок пока нет
- Pointers in CДокумент25 страницPointers in CSainiNishrithОценок пока нет
- The Impact of Social Networking Sites To The Academic Performance of The College Students of Lyceum of The Philippines - LagunaДокумент15 страницThe Impact of Social Networking Sites To The Academic Performance of The College Students of Lyceum of The Philippines - LagunaAasvogel Felodese Carnivora64% (14)
- Exam C - HANATEC142: SAP Certified Technology Associate - SAP HANA (Edition 2014)Документ10 страницExam C - HANATEC142: SAP Certified Technology Associate - SAP HANA (Edition 2014)SadishОценок пока нет
- Sample Engagement LetterДокумент5 страницSample Engagement Letterprincess_camarilloОценок пока нет
- Theben Timer SUL 181DДокумент2 страницыTheben Timer SUL 181DFerdiОценок пока нет
- Syllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244Документ3 страницыSyllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244M O H A N A V E LОценок пока нет
- CA-idms Ads Alive User Guide 15.0Документ142 страницыCA-idms Ads Alive User Guide 15.0svdonthaОценок пока нет
- Toefl StructureДокумент50 страницToefl StructureFebrian AsharОценок пока нет
- Appendicitis Case StudyДокумент6 страницAppendicitis Case StudyKimxi Chiu LimОценок пока нет
- Machine DesignДокумент627 страницMachine DesignlucarОценок пока нет
- Astm D2265-00 PDFДокумент5 страницAstm D2265-00 PDFOGIОценок пока нет