Вам также может понравиться
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- VtDA - The Ashen Cults (Vampire Dark Ages) PDFДокумент94 страницыVtDA - The Ashen Cults (Vampire Dark Ages) PDFRafãoAraujo100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Catastrophe Claims Guide 2007Документ163 страницыCatastrophe Claims Guide 2007cottchen6605100% (1)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Contents Serbo-Croatian GrammarДокумент2 страницыContents Serbo-Croatian GrammarLeo VasilaОценок пока нет
- Research ProposalДокумент45 страницResearch ProposalAaliyah Marie AbaoОценок пока нет
- Abnormal PsychologyДокумент13 страницAbnormal PsychologyBai B. UsmanОценок пока нет
- Nielsen & Co., Inc. v. Lepanto Consolidated Mining Co., 34 Phil, 122 (1915)Документ3 страницыNielsen & Co., Inc. v. Lepanto Consolidated Mining Co., 34 Phil, 122 (1915)Abby PajaronОценок пока нет
- FMEA 4th BOOK PDFДокумент151 страницаFMEA 4th BOOK PDFLuis Cárdenas100% (2)
- Validator in JSFДокумент5 страницValidator in JSFvinh_kakaОценок пока нет
- Reflection On Harrison Bergeron Society. 21ST CenturyДокумент3 страницыReflection On Harrison Bergeron Society. 21ST CenturyKim Alleah Delas LlagasОценок пока нет
- A Photograph (Q and Poetic Devices)Документ2 страницыA Photograph (Q and Poetic Devices)Sanya SadanaОценок пока нет
- Ideal Weight ChartДокумент4 страницыIdeal Weight ChartMarvin Osmar Estrada JuarezОценок пока нет
- 9m.2-L.5@i Have A Dream & Literary DevicesДокумент2 страницы9m.2-L.5@i Have A Dream & Literary DevicesMaria BuizonОценок пока нет
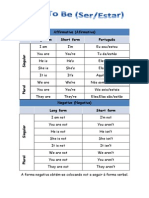
- Affirmative (Afirmativa) Long Form Short Form PortuguêsДокумент3 страницыAffirmative (Afirmativa) Long Form Short Form PortuguêsAnitaYangОценок пока нет
- Need You Now Lyrics: Charles Scott, HillaryДокумент3 страницыNeed You Now Lyrics: Charles Scott, HillaryAl UsadОценок пока нет
- Diploma Pendidikan Awal Kanak-Kanak: Diploma in Early Childhood EducationДокумент8 страницDiploma Pendidikan Awal Kanak-Kanak: Diploma in Early Childhood Educationsiti aisyahОценок пока нет
- Gandhi Was A British Agent and Brought From SA by British To Sabotage IndiaДокумент6 страницGandhi Was A British Agent and Brought From SA by British To Sabotage Indiakushalmehra100% (2)
- Signalling in Telecom Network &SSTPДокумент39 страницSignalling in Telecom Network &SSTPDilan TuderОценок пока нет
- Sukhtankar Vaishnav Corruption IPF - Full PDFДокумент79 страницSukhtankar Vaishnav Corruption IPF - Full PDFNikita anandОценок пока нет
- Technique Du Micro-Enseignement Une Approche PourДокумент11 страницTechnique Du Micro-Enseignement Une Approche PourMohamed NaciriОценок пока нет
- Philosophy of Jnanadeva - As Gleaned From The Amrtanubhava (B.P. Bahirat - 296 PgsДокумент296 страницPhilosophy of Jnanadeva - As Gleaned From The Amrtanubhava (B.P. Bahirat - 296 PgsJoão Rocha de LimaОценок пока нет
- Quarter 3 Week 6Документ4 страницыQuarter 3 Week 6Ivy Joy San PedroОценок пока нет
- A Study of Consumer Behavior in Real Estate Sector: Inderpreet SinghДокумент17 страницA Study of Consumer Behavior in Real Estate Sector: Inderpreet SinghMahesh KhadeОценок пока нет
- Chapter 4 INTRODUCTION TO PRESTRESSED CONCRETEДокумент15 страницChapter 4 INTRODUCTION TO PRESTRESSED CONCRETEyosef gemessaОценок пока нет
- CEI and C4C Integration in 1602: Software Design DescriptionДокумент44 страницыCEI and C4C Integration in 1602: Software Design Descriptionpkumar2288Оценок пока нет
- Challenges For Omnichannel StoreДокумент5 страницChallenges For Omnichannel StoreAnjali SrivastvaОценок пока нет
- Ghalib TimelineДокумент2 страницыGhalib Timelinemaryam-69Оценок пока нет
- FJ&GJ SMДокумент30 страницFJ&GJ SMSAJAHAN MOLLAОценок пока нет
- Snapshot Traveller January 2022Документ11 страницSnapshot Traveller January 2022api-320548675Оценок пока нет
- SATURDAY - FIRST - PDF (1)Документ3 страницыSATURDAY - FIRST - PDF (1)Manuel Perez GastelumОценок пока нет
- SHS11Q4DLP 21st CentFinalДокумент33 страницыSHS11Q4DLP 21st CentFinalNOEMI DE CASTROОценок пока нет