Вам также может понравиться
- Setting The Stage For Indian Realty - Modi's Mid-Term Performance ReportДокумент23 страницыSetting The Stage For Indian Realty - Modi's Mid-Term Performance ReportAnonymous P1dMzVxОценок пока нет
- Mayo ClinicДокумент48 страницMayo ClinicAbdul RazzaqОценок пока нет
- Real Estate March 2017Документ46 страницReal Estate March 2017Anonymous P1dMzVxОценок пока нет
- Building A Collaborative Multichannel Insurance Distribution StrategyДокумент5 страницBuilding A Collaborative Multichannel Insurance Distribution StrategyAnonymous P1dMzVxОценок пока нет
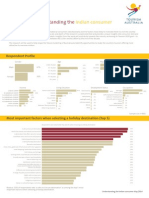
- Future of Outbound Travel in Asia PacificДокумент44 страницыFuture of Outbound Travel in Asia PacificAnonymous P1dMzVxОценок пока нет
- Real Estate March 2017Документ46 страницReal Estate March 2017Anonymous P1dMzVxОценок пока нет
- Union Budget 2016-17: Implications On India's Real EstateДокумент2 страницыUnion Budget 2016-17: Implications On India's Real EstateAnonymous P1dMzVxОценок пока нет
- Data File C W CREDAI Moving Beyond Conventional Housing 1440489013Документ35 страницData File C W CREDAI Moving Beyond Conventional Housing 1440489013Anonymous P1dMzVxОценок пока нет
- Chandigarh Residential Report Aug 2015Документ26 страницChandigarh Residential Report Aug 2015Anonymous P1dMzVxОценок пока нет
- Raheja Vistas MumbaiДокумент12 страницRaheja Vistas MumbaiAnonymous P1dMzVxОценок пока нет
- India Knowing The CustomerДокумент6 страницIndia Knowing The CustomerAnonymous P1dMzVxОценок пока нет
- Indian Consumer Insights on Safety, Beauty and MoreДокумент10 страницIndian Consumer Insights on Safety, Beauty and MoreAnonymous P1dMzVxОценок пока нет
- Singapore Visa Application Form 14AДокумент3 страницыSingapore Visa Application Form 14Asatishakumara100% (2)
- Pulse May 2014 FinalДокумент11 страницPulse May 2014 FinalAnonymous P1dMzVxОценок пока нет
- India Market ProfileДокумент17 страницIndia Market ProfileAnonymous P1dMzVxОценок пока нет
- WP Online Retailing Optimized 2011Документ28 страницWP Online Retailing Optimized 2011Anonymous P1dMzVxОценок пока нет
- Gold Investment SchemeДокумент4 страницыGold Investment SchemeAnonymous P1dMzVxОценок пока нет
- Real Estate GradingsДокумент6 страницReal Estate GradingsAnonymous P1dMzVxОценок пока нет
- 2012 Trends in Loyalty MarketingДокумент8 страниц2012 Trends in Loyalty Marketingmichael guОценок пока нет
- Little Black Book SingaporeДокумент27 страницLittle Black Book SingaporeAnonymous P1dMzVxОценок пока нет
- PPA Profile SampleДокумент4 страницыPPA Profile SampleAnonymous P1dMzVxОценок пока нет
- 50 Digital Marketing MetricsДокумент51 страница50 Digital Marketing MetricsAnonymous P1dMzVx100% (21)
- 2011 COLLOQUY India White PaperДокумент14 страниц2011 COLLOQUY India White PaperAnonymous P1dMzVxОценок пока нет
- Apple Without Steve JobsДокумент1 страницаApple Without Steve JobsAnonymous P1dMzVxОценок пока нет
- Sa+Tourism+Annual+Report+2010 2011Документ186 страницSa+Tourism+Annual+Report+2010 2011Anonymous P1dMzVx100% (1)
- Umpires SignalsДокумент2 страницыUmpires SignalsAnonymous P1dMzVxОценок пока нет
- Social Media TipSДокумент16 страницSocial Media TipSapi-25909664Оценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- ICARE Form Corp Accreditation BOCДокумент3 страницыICARE Form Corp Accreditation BOCMcAsia Foodtrade CorpОценок пока нет
- Difference Between Check and Bilyet GiroДокумент2 страницыDifference Between Check and Bilyet GiroEmilia N. FitriОценок пока нет
- Chapter 3 Solution ManualДокумент14 страницChapter 3 Solution ManualAhmed FathelbabОценок пока нет
- Lecture 10Документ49 страницLecture 10Raja Waseem Sajjad BhattiОценок пока нет
- IA 431 - Group 5 - Finals Case StudyДокумент5 страницIA 431 - Group 5 - Finals Case StudyRaljon YutucОценок пока нет
- Document Date: Vendor Details Delivery DetailsДокумент4 страницыDocument Date: Vendor Details Delivery DetailsMaverick OmnesОценок пока нет
- Defferals AccrualsДокумент30 страницDefferals AccrualsMalvin Roix OrenseОценок пока нет
- IOI Corporation Berhad Circular To Shareholders 2021Документ32 страницыIOI Corporation Berhad Circular To Shareholders 2021parthchillОценок пока нет
- Parachute Hair OilДокумент25 страницParachute Hair OilVatsal Chauhan100% (9)
- Ethics Chapter 1Документ2 страницыEthics Chapter 1lbtuОценок пока нет
- Cover PageДокумент209 страницCover PageABHISHREE JAINОценок пока нет
- OST Roject Eview : P P R TДокумент9 страницOST Roject Eview : P P R TPanneerselvam EkОценок пока нет
- Dealer List 25 04 2006Документ62 страницыDealer List 25 04 2006yogesh_panchal0% (1)
- MYK Arment Company ProfileДокумент16 страницMYK Arment Company ProfileKamal RaoОценок пока нет
- Financial Planning ToolsДокумент50 страницFinancial Planning ToolsPhill SamonteОценок пока нет
- 173335Документ148 страниц173335Taskeen AliОценок пока нет
- Supplier Selection and Evaluation SCMДокумент58 страницSupplier Selection and Evaluation SCMMuneeb KhanОценок пока нет
- FTX Bankruptcy Court Filings of Sullivan & CromwellДокумент23 страницыFTX Bankruptcy Court Filings of Sullivan & CromwellChefs Best Statements - NewsОценок пока нет
- Nike STP & Marketing MixДокумент8 страницNike STP & Marketing MixSaahil BcОценок пока нет
- Feasibility - Study PetroДокумент3 страницыFeasibility - Study PetroDear Lakes AyoОценок пока нет
- Draft National Tourism Policy 2022 Final July 12Документ96 страницDraft National Tourism Policy 2022 Final July 12Shubhadeep MannaОценок пока нет
- Partnership and ResourcesДокумент9 страницPartnership and ResourcesDunia MiqdadОценок пока нет
- BU1193 - Ch. 3 Procurement With FinancialsДокумент39 страницBU1193 - Ch. 3 Procurement With FinancialsTejas CyrilОценок пока нет
- QM - ISO 9001 Corrections 1Документ5 страницQM - ISO 9001 Corrections 1Ravichandran BОценок пока нет
- Notice de Montage Velux ZIS Joint GlaceДокумент9 страницNotice de Montage Velux ZIS Joint GlacecrutОценок пока нет
- Cross Trades and Principal TransactionsДокумент4 страницыCross Trades and Principal TransactionsBrie TeicherОценок пока нет
- Organizational CommunicationДокумент47 страницOrganizational CommunicationRo-Anne LozadaОценок пока нет
- PSF Provides Recommendations To Make Greeces research-KIAX22018ENNДокумент3 страницыPSF Provides Recommendations To Make Greeces research-KIAX22018ENNAxistosОценок пока нет
- VTU MBA Sem 1 Syllabus and Scheme of TeachingДокумент102 страницыVTU MBA Sem 1 Syllabus and Scheme of TeachingShashi KumarОценок пока нет
- Quinones, Geraine Rose D. BSA 21Документ3 страницыQuinones, Geraine Rose D. BSA 21Geraine Rose DelRosario QuiñonesОценок пока нет