Вам также может понравиться
- Incremental Reduced Error Pruning: Johannes F Urnkranz and Gerhard WidmerДокумент15 страницIncremental Reduced Error Pruning: Johannes F Urnkranz and Gerhard WidmerAmardeep Kumar YadavОценок пока нет
- Multilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksОт EverandMultilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksОценок пока нет
- Algorithms 06 00319Документ33 страницыAlgorithms 06 00319khansara7744Оценок пока нет
- Competitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionОт EverandCompetitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionОценок пока нет
- (Acl06 Fin) - (Rens)Документ8 страниц(Acl06 Fin) - (Rens)Anónimo AnónimoОценок пока нет
- Darling LdaДокумент10 страницDarling Ldaguru dineshОценок пока нет
- FeaturespaceДокумент2 страницыFeaturespaceControl NeuronОценок пока нет
- Decision Trees: More Theoretical Justification For Practical Algorithms (Extended Abstract)Документ15 страницDecision Trees: More Theoretical Justification For Practical Algorithms (Extended Abstract)ajithakalyankrishОценок пока нет
- AMPSO: A New Particle Swarm Method For Nearest Neighborhood ClassificationДокумент10 страницAMPSO: A New Particle Swarm Method For Nearest Neighborhood ClassificationDr-Yasir MehmoodОценок пока нет
- A Data Oriented Parsing Model ForДокумент8 страницA Data Oriented Parsing Model ForLucas BorgesОценок пока нет
- Topic Modeling-Based Domain Adaptation For System CombinationДокумент10 страницTopic Modeling-Based Domain Adaptation For System Combinationmusic2850Оценок пока нет
- Exploiting Problem Decomposition in Multi-ObjectivДокумент16 страницExploiting Problem Decomposition in Multi-Objectiva.frank.liceОценок пока нет
- Meta-Genetic Programming: Co-Evolving The Operators of VariationДокумент17 страницMeta-Genetic Programming: Co-Evolving The Operators of VariationchithrasreemodОценок пока нет
- How Many Hidden Layers and NodesДокумент15 страницHow Many Hidden Layers and Nodesaksinha4Оценок пока нет
- 2016 (003) - A Task Scheduling Algorithm Based On SFLAДокумент5 страниц2016 (003) - A Task Scheduling Algorithm Based On SFLAfsmondiolatiroОценок пока нет
- Sapp Automated Reconstruction of Ancient Languages PDFДокумент30 страницSapp Automated Reconstruction of Ancient Languages PDFAОценок пока нет
- 1 s2.0 S004579491100229X MainДокумент12 страниц1 s2.0 S004579491100229X MainKệ ThôiОценок пока нет
- Data Collection and Data Dissemination For Distributed EnvironmentsДокумент32 страницыData Collection and Data Dissemination For Distributed Environmentspand09Оценок пока нет
- A Cellular Genetic Algorithm For Multiobjective OptimizationДокумент12 страницA Cellular Genetic Algorithm For Multiobjective Optimizationrogeriocosta37Оценок пока нет
- Approximate String Matching in DNA SequencesДокумент8 страницApproximate String Matching in DNA SequencesEaco ShawОценок пока нет
- Engineering Applications of Arti Ficial Intelligence: Saber M. Elsayed, Ruhul A. Sarker, Daryl L. EssamДокумент13 страницEngineering Applications of Arti Ficial Intelligence: Saber M. Elsayed, Ruhul A. Sarker, Daryl L. EssamAnant Bhushan NagabhushanaОценок пока нет
- Dithered Noise Shapers and Recursive Digital Filters : Stanley P. Lipshitz, Robert A. Wannamaker, and John VanderkooyДокумент18 страницDithered Noise Shapers and Recursive Digital Filters : Stanley P. Lipshitz, Robert A. Wannamaker, and John VanderkooyTimos PapadopoulosОценок пока нет
- A Memory-Based Approach To Learning Shallow Natural Language PatternsДокумент27 страницA Memory-Based Approach To Learning Shallow Natural Language PatternsargamonОценок пока нет
- Dynamic Multi-Swarm Particle Swarm Optimizer With Local Search For Large Scale Global OptimizationДокумент8 страницDynamic Multi-Swarm Particle Swarm Optimizer With Local Search For Large Scale Global OptimizationahmedtawabОценок пока нет
- Inter Speech 2018Документ5 страницInter Speech 2018Rahul KumarОценок пока нет
- 2021 EMNLP Single RootДокумент18 страниц2021 EMNLP Single RootmiloshstanojevicОценок пока нет
- Cover Detection Using Dominant Melody Embeddings: Guillaume Doras Geoffroy PeetersДокумент8 страницCover Detection Using Dominant Melody Embeddings: Guillaume Doras Geoffroy PeetersannaОценок пока нет
- Efficient Knowledge Base Management in DCSPДокумент11 страницEfficient Knowledge Base Management in DCSPijasucОценок пока нет
- Lower Bounds Probabilistic Arguments: With AllДокумент9 страницLower Bounds Probabilistic Arguments: With AllAbishanka SahaОценок пока нет
- B.E Semester: 6 - IT (GTU) : 2161603 - Data Compression and Data RetrievalДокумент17 страницB.E Semester: 6 - IT (GTU) : 2161603 - Data Compression and Data RetrievalpriyankaОценок пока нет
- Recent Advances in Sparse Direct Solvers: Approximations, and Distributed/shared Memory Hybrid ProgrammingДокумент10 страницRecent Advances in Sparse Direct Solvers: Approximations, and Distributed/shared Memory Hybrid ProgrammingRaviteja MeesalaОценок пока нет
- Clustering of Bio Medical Scientific PapersДокумент5 страницClustering of Bio Medical Scientific PapersCaN EroLОценок пока нет
- A Unified Architecture For Natural Language Processing: Deep Neural Networks With Multitask LearningДокумент9 страницA Unified Architecture For Natural Language Processing: Deep Neural Networks With Multitask LearningnghiaОценок пока нет
- Persistent Data StructuresДокумент3 страницыPersistent Data StructuresHarishNandanОценок пока нет
- Span-Based LCFRS-2 ParsingДокумент11 страницSpan-Based LCFRS-2 ParsingmiloshstanojevicОценок пока нет
- Run-Sort-Rerun: Escaping Batch Size Limitations in Sliced Wasserstein Generative ModelsДокумент11 страницRun-Sort-Rerun: Escaping Batch Size Limitations in Sliced Wasserstein Generative ModelsAni SafitriОценок пока нет
- Multi-Core Strategies For Particle Me: John R. Williams, David Holmes and Peter TilkeДокумент7 страницMulti-Core Strategies For Particle Me: John R. Williams, David Holmes and Peter Tilkeyagebu88Оценок пока нет
- Description of The Tangora SystemДокумент5 страницDescription of The Tangora SystemPatrick MooreОценок пока нет
- A Dynamic Global and Local Combined Particle Swarm Optimization AlgorithmДокумент8 страницA Dynamic Global and Local Combined Particle Swarm Optimization AlgorithmSopan Ram TambekarОценок пока нет
- Language Processing and ComputationalДокумент10 страницLanguage Processing and ComputationalCarolyn HardyОценок пока нет
- (Conll06 Fin) - (Rens)Документ8 страниц(Conll06 Fin) - (Rens)Anónimo AnónimoОценок пока нет
- Figueiredo Et Al. - 2007 - Gradient Projection For Sparse Reconstruction Application To Compressed Sensing and Other Inverse Problems-AnnotatedДокумент12 страницFigueiredo Et Al. - 2007 - Gradient Projection For Sparse Reconstruction Application To Compressed Sensing and Other Inverse Problems-Annotatedyjang88Оценок пока нет
- Inducing Tree-Substitution Grammars: Trevor CohnДокумент44 страницыInducing Tree-Substitution Grammars: Trevor CohnJay DRLOОценок пока нет
- Application of Fsa To NLPДокумент21 страницаApplication of Fsa To NLPAnimesh ShawОценок пока нет
- Journal of Statistical Software: Pyparticleest: A Python Framework ForДокумент25 страницJournal of Statistical Software: Pyparticleest: A Python Framework ForCasey GibsonОценок пока нет
- Signal Processing: Bob L. Sturm, Laurent DaudetДокумент16 страницSignal Processing: Bob L. Sturm, Laurent DaudetGurpreet Singh WaliaОценок пока нет
- New Ranking Algorithms For Parsing and Tagging: Kernels Over Discrete Structures, and The Voted PerceptronДокумент8 страницNew Ranking Algorithms For Parsing and Tagging: Kernels Over Discrete Structures, and The Voted PerceptronMeher VijayОценок пока нет
- Smaller Representation of Finite State AutomataДокумент12 страницSmaller Representation of Finite State AutomataPete aaОценок пока нет
- Vowel and Consonant Characterization Using Fractal Dimension in Natural SpeechДокумент4 страницыVowel and Consonant Characterization Using Fractal Dimension in Natural SpeechSourav BiswasОценок пока нет
- Inducing Deterministic Prolog Parsers From Treebanks: A Machine Learning ApproachДокумент6 страницInducing Deterministic Prolog Parsers From Treebanks: A Machine Learning Approachmali_me12Оценок пока нет
- Hieu ICASSP2012 8Документ4 страницыHieu ICASSP2012 8ngduyhieuОценок пока нет
- Align 2Документ29 страницAlign 2Vandy IkraОценок пока нет
- Multiclass Text Classification On Unbalanced, Sparse and Noisy DataДокумент8 страницMulticlass Text Classification On Unbalanced, Sparse and Noisy DataAman AgnihotriОценок пока нет
- Aaaaa - CopieДокумент44 страницыAaaaa - CopieBagga HamzaОценок пока нет
- HMM Adaptation Using Vector Taylor Series For Noisy Speech RecognitionДокумент4 страницыHMM Adaptation Using Vector Taylor Series For Noisy Speech RecognitionjimakosjpОценок пока нет
- Dossi Kojon - M. Zafar IqbalДокумент7 страницDossi Kojon - M. Zafar Iqbalmasudalam33% (3)
- ParsingДокумент4 страницыParsingAmira ECОценок пока нет
- 26069-Article Text-30132-1-2-20230626Документ9 страниц26069-Article Text-30132-1-2-20230626nguyen van anОценок пока нет
- Premidsem Exercises Set 1Документ5 страницPremidsem Exercises Set 1sahil walkeОценок пока нет
- Mod11 - Context Sensitive Grammar (PDA)Документ24 страницыMod11 - Context Sensitive Grammar (PDA)jhon mhar beradorОценок пока нет
- MSCCST 302Документ2 страницыMSCCST 302api-3782519Оценок пока нет
- UNIT-1: Compiler DesignДокумент17 страницUNIT-1: Compiler DesignapoorvОценок пока нет
- Bca New Syll1 PDFДокумент40 страницBca New Syll1 PDFhaine12345Оценок пока нет
- Compiler Design and Construction NoteДокумент97 страницCompiler Design and Construction NoteSam MasОценок пока нет
- Stable PDFДокумент1 468 страницStable PDFnoltynОценок пока нет
- Evolutionary Algorithms N NLPДокумент28 страницEvolutionary Algorithms N NLPKomal Singh GillОценок пока нет
- Outline PDFДокумент3 страницыOutline PDFIsrat Noor KaziОценок пока нет
- Reviewer AutomataДокумент7 страницReviewer AutomataRe ErОценок пока нет
- r05310501 Formal Languages and Automata TheoryДокумент8 страницr05310501 Formal Languages and Automata TheoryandhracollegesОценок пока нет
- B.Tech 2nd Year CSE & CSIT AICTE Model Curriculum 2019-20 PDFДокумент14 страницB.Tech 2nd Year CSE & CSIT AICTE Model Curriculum 2019-20 PDFBrij BihariОценок пока нет
- CS2004Документ2 страницыCS2004Satya DasОценок пока нет
- Atc NotesДокумент30 страницAtc NotesRakshith AcchuОценок пока нет
- Lexical and Syntax AnalysisДокумент34 страницыLexical and Syntax AnalysisLashawn BrownОценок пока нет
- cs212 Lect04 63 InterДокумент23 страницыcs212 Lect04 63 InterLeng Hour lengОценок пока нет
- Compiler Design Notes PDFДокумент103 страницыCompiler Design Notes PDFharika manikantaОценок пока нет
- Ambiguous GrammarДокумент5 страницAmbiguous GrammarAnand Krishna100% (1)
- CFG Terminologies: Terminals: The Symbols That Can't Be Non-Terminals: The Symbols That Must BeДокумент37 страницCFG Terminologies: Terminals: The Symbols That Can't Be Non-Terminals: The Symbols That Must BetariqravianОценок пока нет
- Programming Language Concepts Format: 1 Exam ReviewДокумент3 страницыProgramming Language Concepts Format: 1 Exam ReviewAniketОценок пока нет
- SYcs Computer Science SyllabusДокумент38 страницSYcs Computer Science SyllabusakshayОценок пока нет
- Cse2004 Theory of Computation and Compiler Design LT 1.0 1 Cse2004 Theory of Computation and Compiler Design LT 1.0 1 Cse2004Документ2 страницыCse2004 Theory of Computation and Compiler Design LT 1.0 1 Cse2004 Theory of Computation and Compiler Design LT 1.0 1 Cse2004Yakshi MangalОценок пока нет
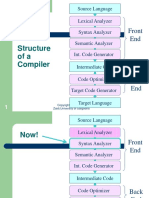
- Structure Ofa Compiler: Front EndДокумент95 страницStructure Ofa Compiler: Front EndHassan AliОценок пока нет
- Chapter 04 - Context Free LanguageДокумент21 страницаChapter 04 - Context Free LanguageprincejiОценок пока нет
- Atcd Model QPДокумент4 страницыAtcd Model QPIT HOD0% (1)
- 10 Natural Language ProcessingДокумент27 страниц10 Natural Language Processingrishad93Оценок пока нет
- PPL NotesДокумент95 страницPPL Notesneelima raniОценок пока нет
- Department of Computer Engineering: Sr. UnitДокумент4 страницыDepartment of Computer Engineering: Sr. UnitVipul KumarОценок пока нет
- Finite AutomataДокумент17 страницFinite Automatasumit_bhardwaj87Оценок пока нет
- PPLДокумент154 страницыPPLHarsha Vardhan ReddyОценок пока нет
- Unity University: Department of Computer SciencesДокумент4 страницыUnity University: Department of Computer SciencesSVB MoviesОценок пока нет