Вам также может понравиться
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Bipolar DisordersДокумент8 страницBipolar Disorderssarguss14100% (2)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Dissociative and Eating DisordersДокумент6 страницDissociative and Eating Disorderssarguss14Оценок пока нет
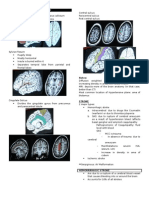
- NeuroradiologyДокумент11 страницNeuroradiologysarguss14100% (2)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Pediatric GI RadiologyДокумент6 страницPediatric GI Radiologysarguss14Оценок пока нет
- NeuroradiologyДокумент25 страницNeuroradiologysarguss14100% (2)
- Developmental AssessmentДокумент3 страницыDevelopmental Assessmentsarguss14Оценок пока нет
- Pleura and MediastinumДокумент16 страницPleura and Mediastinumsarguss14100% (1)
- Epidural and Spinal AnesthesiaДокумент86 страницEpidural and Spinal Anesthesiasarguss1471% (7)
- Introduction To RadiologyДокумент3 страницыIntroduction To Radiologysarguss14Оценок пока нет
- Cardiac ImagingДокумент7 страницCardiac Imagingsarguss14Оценок пока нет
- Small BowelДокумент4 страницыSmall Bowelsarguss14100% (1)
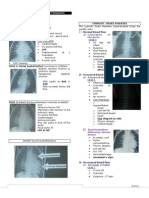
- Cyanotic Congenital Heart Diseases, Etc.Документ12 страницCyanotic Congenital Heart Diseases, Etc.sarguss14100% (2)
- Inhalational Anesthetics: Patigas, Requinta, ResuelloДокумент88 страницInhalational Anesthetics: Patigas, Requinta, Resuellosarguss140% (1)
- Epidemiology MCQsДокумент4 страницыEpidemiology MCQsChikezie Onwukwe100% (1)
- Stage 1: Dorsal Induction: Pediatric NeuroradiologyДокумент8 страницStage 1: Dorsal Induction: Pediatric Neuroradiologysarguss14100% (1)
- From Doc Bandong's Own Words:: Shar 1 of 20Документ20 страницFrom Doc Bandong's Own Words:: Shar 1 of 20sarguss14100% (1)
- Genitourinary SystemДокумент8 страницGenitourinary Systemsarguss14100% (1)
- Non Experimental ResearchДокумент16 страницNon Experimental ResearchAnju Margaret100% (1)
- Basic Concepts of EpidemiologyДокумент125 страницBasic Concepts of EpidemiologyKailash Nagar100% (1)
- Clinical Epidemiology - Principles, Methods, and Applications For Clinical Research (PDFDrive)Документ487 страницClinical Epidemiology - Principles, Methods, and Applications For Clinical Research (PDFDrive)khalid balsha100% (1)
- Epidemiological Methods: Prabha Krishnan, Year MSC Nursing, CNC, KKDДокумент22 страницыEpidemiological Methods: Prabha Krishnan, Year MSC Nursing, CNC, KKDprabha krishnan100% (2)
- Evidence Based Practice in NursingДокумент86 страницEvidence Based Practice in NursingKrea kristalleteОценок пока нет
- Gallbladder, Liver, Pancreas and SpleenДокумент19 страницGallbladder, Liver, Pancreas and Spleensarguss14100% (3)
- Critical Appraisal Form For Cohort StudyДокумент3 страницыCritical Appraisal Form For Cohort StudyFina Adolfina100% (1)
- Nursing Research POST TEST PNLE 2023 AKДокумент14 страницNursing Research POST TEST PNLE 2023 AKFANER CIENAH MARIEОценок пока нет
- Epidemiological MethodsДокумент22 страницыEpidemiological MethodsDolly Dutta0% (1)
- Axial Arthritis: Degenerative Annular DiseaseДокумент18 страницAxial Arthritis: Degenerative Annular Diseasesarguss14100% (1)
- Bone TumorsДокумент15 страницBone Tumorssarguss1450% (2)
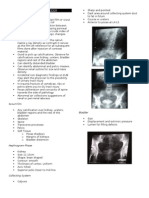
- Kidney, Ureter, BladderДокумент12 страницKidney, Ureter, Bladdersarguss14100% (1)
- Substance AbuseДокумент4 страницыSubstance Abusesarguss14Оценок пока нет
- Congenital Cystic Adenomatoid Malformation (CCAM)Документ7 страницCongenital Cystic Adenomatoid Malformation (CCAM)sarguss14Оценок пока нет
- Respiratory Distress of The NewbornДокумент3 страницыRespiratory Distress of The Newbornsarguss14100% (1)
- The Normal Kidney: Pediatrics 2 The Urinary System and Urinary Tract InfectionsДокумент4 страницыThe Normal Kidney: Pediatrics 2 The Urinary System and Urinary Tract Infectionssarguss14Оценок пока нет
- DepressionДокумент3 страницыDepressionsarguss14Оценок пока нет
- Child Abuse and NeglectДокумент3 страницыChild Abuse and Neglectsarguss14Оценок пока нет
- Mental Retardation and Learning DisordersДокумент4 страницыMental Retardation and Learning Disorderssarguss14100% (1)
- Pediatric Endocrinology Part 2: Pediatrics 2Документ8 страницPediatric Endocrinology Part 2: Pediatrics 2sarguss14Оценок пока нет
- CASP Checklist: Cohort StudyДокумент7 страницCASP Checklist: Cohort StudyShemae Lyn CamasuraОценок пока нет
- Advance Epi & Direct Acyclic GraphДокумент14 страницAdvance Epi & Direct Acyclic GraphPurnima VermaОценок пока нет
- sTEVENS PDFДокумент9 страницsTEVENS PDFmustafasacarОценок пока нет
- EBP ManualДокумент53 страницыEBP ManualsyamafiyahОценок пока нет
- Epidemiologi k3 Revisi-DikonversiДокумент16 страницEpidemiologi k3 Revisi-DikonversiLalisa NisaОценок пока нет
- (BAHAN BACAAN) Selecting The Appropriate Study Design - Case-Control and Cohort Study DesignsДокумент5 страниц(BAHAN BACAAN) Selecting The Appropriate Study Design - Case-Control and Cohort Study DesignsKasilaОценок пока нет
- Sesi 7c - Studi Kros Seksional 2011Документ88 страницSesi 7c - Studi Kros Seksional 2011rahimulyОценок пока нет
- Rancangan Penelitian.09Документ45 страницRancangan Penelitian.09Frendy GhaОценок пока нет
- (Current Topics in Microbiology and Immunology (2010)Документ173 страницы(Current Topics in Microbiology and Immunology (2010)milaОценок пока нет
- Soy Isoflavones and Breast Cancer RiskДокумент17 страницSoy Isoflavones and Breast Cancer RiskJannel Gentius100% (1)
- Economic Analysis For Health - AprilДокумент36 страницEconomic Analysis For Health - AprilSuyash Rai100% (1)
- BBA (Hons) Mini ProjectДокумент11 страницBBA (Hons) Mini ProjectMujahid AliОценок пока нет
- Cohort Critical AppraisalДокумент5 страницCohort Critical AppraisalViko Bagus LisephanoОценок пока нет
- COVID y RiñonesДокумент73 страницыCOVID y RiñonesSMIBA MedicinaОценок пока нет
- The UK Women's Cohort Study: Comparison of Vegetarians, Fish-Eaters and Meat-EatersДокумент8 страницThe UK Women's Cohort Study: Comparison of Vegetarians, Fish-Eaters and Meat-EatersNina TuilomaОценок пока нет
- Assignment 6: Analytical Study Designs: Unit 1 - Basic Course in Biomedical Research: Cycle 2 (Mar-Jun 2020)Документ6 страницAssignment 6: Analytical Study Designs: Unit 1 - Basic Course in Biomedical Research: Cycle 2 (Mar-Jun 2020)stОценок пока нет
- Hasil Tugas ConsortДокумент15 страницHasil Tugas ConsortSelly AnggrainiОценок пока нет
- Kul 6 - Bias Dan Confounding Dalam EpidemiologiДокумент52 страницыKul 6 - Bias Dan Confounding Dalam EpidemiologibenzabensaaОценок пока нет
- Radiation Related Risk of CancerДокумент283 страницыRadiation Related Risk of CancerKristy VasilachiОценок пока нет
- Levels of Smoking and Dental Implants Failure: A Systematic Review and Meta-AnalysisДокумент11 страницLevels of Smoking and Dental Implants Failure: A Systematic Review and Meta-AnalysisJuan Pablo Aguilera MardonesОценок пока нет
- Walsh2015association of Diabetic Foot Ulcer and Death in A Population-Based Cohort From The United KingdomДокумент6 страницWalsh2015association of Diabetic Foot Ulcer and Death in A Population-Based Cohort From The United KingdomAnonymous SMLzNAОценок пока нет