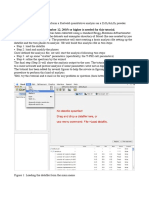
Вам также может понравиться
- MZA Userguide PDFДокумент8 страницMZA Userguide PDFmark canolaОценок пока нет
- UNIT 2 Electronic SpreadsheetДокумент30 страницUNIT 2 Electronic SpreadsheetAnjum AkhtharОценок пока нет
- In Class Exercise ClusteringДокумент46 страницIn Class Exercise ClusteringMárcio NitãoОценок пока нет
- 1st IT Cls10Документ30 страниц1st IT Cls10Piyush kumarОценок пока нет
- 2261 PDFДокумент30 страниц2261 PDFTessfaye Wolde GebretsadikОценок пока нет
- Mazda Brain CompareДокумент83 страницыMazda Brain CompareknovakОценок пока нет
- 402-IT - ClassX - 2023Документ153 страницы402-IT - ClassX - 2023Harish Raghave.GОценок пока нет
- Cluster AnalysisДокумент43 страницыCluster AnalysisArpan KumarОценок пока нет
- Spreadsheet Unit 1Документ25 страницSpreadsheet Unit 1sujatha chundruОценок пока нет
- Comprehensive Meta Analysis Version 2 (Beta)Документ68 страницComprehensive Meta Analysis Version 2 (Beta)surbhi.meshramОценок пока нет
- Eviews PDFДокумент18 страницEviews PDFaftab20Оценок пока нет
- Unsupervised Classfication Using ER MapperДокумент9 страницUnsupervised Classfication Using ER MapperavisenicОценок пока нет
- Zond-MT 1D: User GuideДокумент25 страницZond-MT 1D: User GuideEmRan LeghariОценок пока нет
- Image Analysis - Supervised Classification. Evaluation of AccuracyДокумент5 страницImage Analysis - Supervised Classification. Evaluation of AccuracyHariharKaliaОценок пока нет
- Release Procedure For Service Entry SheetДокумент3 страницыRelease Procedure For Service Entry SheetKapil KulkarniОценок пока нет
- Advanced Engineering Statistics: Lectures For M.SCДокумент77 страницAdvanced Engineering Statistics: Lectures For M.SCBest PracticeОценок пока нет
- Nemo AnalyserДокумент22 страницыNemo AnalyserNguyễn Hùng SơnОценок пока нет
- U2 All SessionsДокумент22 страницыU2 All SessionsParshiv SharmaОценок пока нет
- Correlation Analysis TutorialДокумент45 страницCorrelation Analysis TutorialAmogh R NalawadeОценок пока нет
- Calculation and Reblocking Tools Added To MineSight® DARTДокумент4 страницыCalculation and Reblocking Tools Added To MineSight® DART11804Оценок пока нет
- Analysis of Trusses Using SAP2000Документ20 страницAnalysis of Trusses Using SAP2000ran71681Оценок пока нет
- Win Tensor-UserGuide Subset-Management PDFДокумент6 страницWin Tensor-UserGuide Subset-Management PDFLeoSolorzanoMirandaОценок пока нет
- Femap TutorialДокумент33 страницыFemap TutorialTahir RashidОценок пока нет
- Ansys User Guide PDFДокумент33 страницыAnsys User Guide PDFSahil KumarОценок пока нет
- NetworkscanviewerДокумент3 страницыNetworkscanviewerBenito_Camelas2021Оценок пока нет
- Microsoft - SQL Scripts For Partitioned Tables and IndexesДокумент12 страницMicrosoft - SQL Scripts For Partitioned Tables and Indexessivy75Оценок пока нет
- Nemo Analyzer: Gaurav TiwariДокумент22 страницыNemo Analyzer: Gaurav TiwariWasim BaigОценок пока нет
- Microsoft Excel 2010: Data ManipulationДокумент56 страницMicrosoft Excel 2010: Data ManipulationdangermanОценок пока нет
- Plot XYДокумент10 страницPlot XYbubo28Оценок пока нет
- Binary Encoding (Using ENVI) Exelis VIS Docs CenterДокумент2 страницыBinary Encoding (Using ENVI) Exelis VIS Docs CentermizzakeeОценок пока нет
- Query Wizard: Step 1 - Select FieldsДокумент3 страницыQuery Wizard: Step 1 - Select FieldsClerenda McgradyОценок пока нет
- What Is A Selection?: Characteristics of SelectionsДокумент7 страницWhat Is A Selection?: Characteristics of SelectionsYaronBabaОценок пока нет
- Classification ENVI TutorialДокумент16 страницClassification ENVI TutorialignaciaОценок пока нет
- Help AnClimДокумент12 страницHelp AnClimhcsrecsОценок пока нет
- GSM ActixДокумент64 страницыGSM ActixNenad100% (1)
- Chapter 11 - History MatchingДокумент14 страницChapter 11 - History MatchingBilal AmjadОценок пока нет
- Working With Database Tools by GeosoftДокумент9 страницWorking With Database Tools by GeosoftJuan PiretОценок пока нет
- MCTK User's GuideДокумент27 страницMCTK User's GuideBilly GemaОценок пока нет
- Chapter 6 Create-View-Draw Cross SectionsДокумент12 страницChapter 6 Create-View-Draw Cross SectionsBalachanter RamasamyОценок пока нет
- JAMOVI 2017 Statistics For Psychologists Section - JAMOVI Chapter - Using The Software - 1Документ25 страницJAMOVI 2017 Statistics For Psychologists Section - JAMOVI Chapter - Using The Software - 1Carlos EscalhaoОценок пока нет
- AX Interview Questions - SAIДокумент46 страницAX Interview Questions - SAIkasimОценок пока нет
- MultiSpec Tutorial 1Документ5 страницMultiSpec Tutorial 1Miguel Romero RinconОценок пока нет
- Sap Truess Step by Step ProceduresДокумент18 страницSap Truess Step by Step ProceduresThulasirajan KrishnanОценок пока нет
- TH Quick Start GuideДокумент11 страницTH Quick Start GuideostogradskiОценок пока нет
- QPA TrainingДокумент13 страницQPA TrainingsenthilkumarОценок пока нет
- 06 16 PT 3Документ115 страниц06 16 PT 3Dung OngОценок пока нет
- Load The Classified Image You Created Earlier 1 Click The Edit Algorithm Toolbar ButtonДокумент3 страницыLoad The Classified Image You Created Earlier 1 Click The Edit Algorithm Toolbar ButtonUlfah NastiОценок пока нет
- Emeraude v5.20 Update NotesДокумент15 страницEmeraude v5.20 Update NotesMuntadher MejthabОценок пока нет
- Plot XYДокумент8 страницPlot XYumairnaeem_90Оценок пока нет
- Processing of Diffraction Data With The HIGH SCORE PLUS ProgramДокумент23 страницыProcessing of Diffraction Data With The HIGH SCORE PLUS Programbasco costasОценок пока нет
- Scrubber 2Документ18 страницScrubber 2molszewОценок пока нет
- Tutorial OverviewДокумент31 страницаTutorial OverviewFernandoОценок пока нет
- MicroWind Tutorial MineДокумент12 страницMicroWind Tutorial MineFawad Khan100% (1)
- User Guide For 4cast XLДокумент31 страницаUser Guide For 4cast XLAbhinav JainОценок пока нет
- Data Warehousing and Data Mining Lab ManualДокумент30 страницData Warehousing and Data Mining Lab ManualBabuYgОценок пока нет
- Autodesk - Autocad - Vba Integrating With Microsoft Excel PDFДокумент4 страницыAutodesk - Autocad - Vba Integrating With Microsoft Excel PDFfrancodlhОценок пока нет
- Equipment Calibration LogДокумент5 страницEquipment Calibration Logkero keropiОценок пока нет
- Excel Basic Student HandoutsДокумент95 страницExcel Basic Student Handoutsapi-226989719Оценок пока нет
- DigitalliteracyДокумент5 страницDigitalliteracyapi-419126179Оценок пока нет
- SW DTM ManualДокумент51 страницаSW DTM Manualsmanoj35475% (4)
- Prof Services Tools LibraryДокумент69 страницProf Services Tools Libraryluis E Perdomo AОценок пока нет
- Cotton MillДокумент197 страницCotton MillRyan SloanОценок пока нет
- AUGI - Data Extraction in AutoCADДокумент12 страницAUGI - Data Extraction in AutoCADRahul SrivastavaОценок пока нет
- Basler Electric Electriccalcs - r2Документ17 страницBasler Electric Electriccalcs - r2MrОценок пока нет
- Equation K-1, K-3 Calculation SpreadsheetДокумент4 страницыEquation K-1, K-3 Calculation SpreadsheetjowarОценок пока нет
- Mail MergeДокумент18 страницMail MergeCarl ThomasОценок пока нет
- Using Function: Prepared By: Prof. Rubilee S. MarianoДокумент38 страницUsing Function: Prepared By: Prof. Rubilee S. MarianoShaun KneeОценок пока нет
- Bsnos Program - WguДокумент21 страницаBsnos Program - WguRobert Allen RippeyОценок пока нет
- 2008 SCT Computing SkillsДокумент52 страницы2008 SCT Computing SkillsGorden GuОценок пока нет
- Business Plans and Marketing StrategyДокумент55 страницBusiness Plans and Marketing Strategysaachin.dubey1983Оценок пока нет
- 2023 It SbaДокумент8 страниц2023 It SbaCarl ThomasОценок пока нет
- Media Charge TrajectoriesДокумент9 страницMedia Charge Trajectoriessnarf273Оценок пока нет
- Uncertainty Budget Table Template 16jan2013Документ3 страницыUncertainty Budget Table Template 16jan2013BALAJIОценок пока нет
- Internet and Computing Fundamentals CBCДокумент88 страницInternet and Computing Fundamentals CBCJethro Campos80% (5)
- MrSnorch Spreadsheet - Sunflower Land (Recuperado Automáticamente)Документ201 страницаMrSnorch Spreadsheet - Sunflower Land (Recuperado Automáticamente)Jose GomezОценок пока нет
- CommonExcelWindowsShortcuts 01 PDFДокумент3 страницыCommonExcelWindowsShortcuts 01 PDFPriyankaKakruОценок пока нет
- +++375201080 UPL Design Using Microsoft Excel PDFДокумент7 страниц+++375201080 UPL Design Using Microsoft Excel PDFcabmendesОценок пока нет
- Basics of Information & Communication Technology (ICT) Course Code: 4300010Документ10 страницBasics of Information & Communication Technology (ICT) Course Code: 4300010Vishakha PatelОценок пока нет
- Buried piping-C2UG PDFДокумент18 страницBuried piping-C2UG PDFChirag BhagatОценок пока нет
- Microsoft Excel TutorialДокумент66 страницMicrosoft Excel TutorialFakhr-e-Alam88% (8)
- Excel Skill AssesmentДокумент50 страницExcel Skill Assesmentankit_khandelwal1210Оценок пока нет
- Boundary-Value Problems in ElectromagneticsДокумент20 страницBoundary-Value Problems in Electromagneticsdrjonesg19585102Оценок пока нет
- Unit 9 Spreadsheet Development Assignment 1 - Luke JacksonДокумент15 страницUnit 9 Spreadsheet Development Assignment 1 - Luke Jacksonapi-448941162100% (1)
- 3 PipelineStudio Technical Description Gas Rev 5 - Sep 2012Документ22 страницы3 PipelineStudio Technical Description Gas Rev 5 - Sep 2012wiwiz2000Оценок пока нет
- Conf 401 ManualДокумент85 страницConf 401 ManualdracuojiОценок пока нет