Академический Документы
Профессиональный Документы
Культура Документы
9ib DIAG
Загружено:
api-3831209Исходное описание:
Оригинальное название
Авторское право
Доступные форматы
Поделиться этим документом
Поделиться или встроить документ
Этот документ был вам полезен?
Это неприемлемый материал?
Пожаловаться на этот документАвторское право:
Доступные форматы
9ib DIAG
Загружено:
api-3831209Авторское право:
Доступные форматы
Event-Driven Diagnostic Dumps
Improved Diagnosability Features 1-1
Objectives
After this lesson, you should be able to:
• Identify uses for event-driven flash freezes
• List the features of an event-driven flash freeze
• Set events for an event driven flash freeze
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 1-2
What is a Flash Freeze
• Flash freezing locks a database so that
diagnostic checks can be run but no further
activity will modify the contents to change the
problem being diagnosed
• Flash freeze terminates all connections and
refuses all new ones except a privileged user
• Useful in test or development databases where
work can wait until diagnosis is completed: the
database can be terminated but the state of its
memory preserved
• Used by advanced analysts familiar with
Oracle debugging tools, such as ORADEBUG
Copyright © Oracle Corporation, 2001. All rights reserved.
What is a Flash Freeze
A flash freeze “locks” a database in its current state so that an analyst can use debugging tools
to examine the contents of memory and the state of various background processes, resources,
and so on. The operation freezes the processes so nothing can change at all— the UGA, PGA,
and SGA are all frozen. To freeze the background processes, flash freeze uses a signal handler
that is triggered by sending that signal to every process. In that signal handler, every signal is
marked “OFF,” except the release one, and then the flash freeze waits for a release signal.
The typical user of a flash freeze is an Oracle World Wide Support (WWS) analyst as it is used
in conjunction with such debugging tools as ORADEBUG. Once an instance is frozen, an
analyst to see exactly what was occurring in the database at the moment it was frozen. Flash
freezing is typically used when an error is being debugged and the relative state of the various
components potentially involved needs to be examined to determine the cause.
By flash freezing the database, the analyst prevents any further work from occurring. It is
therefore most useful in situations where the loss of the instance will not impact the work of
the database users. This is most likely to occur when the database is used for development and
testing.
NOTE: Flash Freeze is an existing tool that has not changed in this release. This lesson only
covers the event-driven functionality introduced in Oracle9i. More detailed information on
Flash Freeze capabilities is available from WWS analysts who have used this feature.
Improved Diagnosability Features 1-3
Flash Freeze
• Previous versions of flash freeze required
manual intervention to freeze the database
using ORADEBUG
• Event-driven flash freezes are initiated by
events
– Internal errors
– External events or errors
• Conditions set by database administrator or
similar, high-level user, defined by events
– In init.ora
– Initiated by alter system set event
commands
Copyright © Oracle Corporation, 2001. All rights reserved.
Flash Freeze
As the Oracle RDBMS continues to grow with new and complex functionality, and high
availability requirements are mandatory, efficient debugging and diagnostics becomes crucial.
As systems continue to scale and require 99.999% uptime, it is imperative that diagnosability
tools are secure, fast, and provide all the data necessary to determine root cause the first time a
fault occurs.
In previous versions, a flash freeze could only be initiated manually using ORADEBUG. This
required that someone be available at the time an error occurred to freeze the database
immediately. In an event-driven flash freeze, the freeze is performed automatically when a
predefined condition occurs.
The events triggering an automatic flash freeze are defined by a privileged user, either with
EVENT specifications in the initialization parameter file or with ALTER SYSTEM SET
EVENT commands. The triggering events include
• Internal errors, that is, any ORA-00600 error
• External events, typically driven from operating system scripts which would also
initiate a manual freeze
• External errors, that is, any ORA-xxxxx error, where xxxxx is any error number other
than 00600
Improved Diagnosability Features 1-4
Benefits of Event-Driven Flash Freeze
• Defined events allow flash freeze to occur at
time of problem
– Preserves all relevant database and SGA
states at time of the problem
– SGA and database can be examined to
determine the cause of the problem
– Can be initiated in unattended databases
• Can trigger the freeze on a preliminary event
suspected of being a precursor to a problem
• Diagnosis can be done the first time an error
occurs, helping preserve future availability
• Reduce information submitted to WWS
Copyright © Oracle Corporation, 2001. All rights reserved.
Benefits of Event-Driven Flash Freeze
Event-driven Flash Freeze enables users to set conditions under which a “flash freeze” of an
instance can be invoked. The main requirement is to allow support analysts a mechanism to
freeze a system automatically for further diagnostics when an Oracle error occurs. Although
flash freezing can be completed manually, it has the following shortcomings:
• It may be invoked too late; if the system is frozen long after the problem has happened,
the clues may have disappeared from the SGA.
• It makes flash freeze functionality easier to use in an unattended environment, such as
nightly testing, where it could be desirable to freeze the system on error, and look at it
in the morning.
• It may be desirable to freeze the system on certain events which are suspected to trigger
the problem, although they may not be the cause of the problem. Error handling, for
example, is not always done correctly, and can cause the problems downstream. In this
case, it may be helpful to freeze the system on the triggering condition, and debug it
from there.
Improved Diagnosability Features 1-5
Event-Driven Flash Freeze Functionality
• Automatic flash freeze on
– Any internal error
– Specified external errors
• Allow privileged user to flash freeze an entire instance
• Setting and unsetting flash freeze events is dynamic
– Does not require instance restart
– Setting changes are recorded in the alert log
• Flash freeze and de-register a single Real Application
Cluster instance
– De-registration of the flash-frozen instance permits
the remaining instances to reconfigure and resume
operation
– The frozen instance can be analyzed in isolation
– This is a manual step and is optional
Copyright © Oracle Corporation, 2001. All rights reserved.
Event-Driven Flash Freeze Functionality
Event-driven flash freeze functionality includes the following features:
• Provides the ability to automatically flash freeze the system when (any) internal error
(ORA-00600) happens.
• Provides the ability to automatically flash freeze the system under specified external
errors (any ORA error other than ORA-00600).
• Allows only users with appropriate privilege (DBA) to set this event of flash freezing
an entire instance upon error. (Allow only ALTER SYSTEM syntax.)
• Offers a dynamic mechanism for setting and unsetting this event dynamically; the
instance does not need to be shutdown and restarted for the event to take effect.
• Creates additional logging to the alert log. Flash Freeze itself already contains
appropriate logging information, but event-driven flash freeze requires messages when
an event is set/unset, and when it is triggered. This is necessary since it may be several
hours or days from when the event is actually set to when it is triggered.
• Allows event to flash freeze a single instance and allows an instance to be de-registered
from a Real Application Cluster. This allows the surviving instances to reconfigure and
resume their operations while the frozen instance can be analyzed in isolation as time
permits. You de-register an instance using the ffderegister option of the
oradebug command, as shown in the following example:
SQL> oradebug ffderegister;
• Once de-registered, you must shutdown and restart the instance to resume normal
operations
Improved Diagnosability Features 1-6
Precedence of Flash Freeze Actions
When multiple actions can initiate a flash freeze,
they follow this order of precedence:
1. Context-independent traces in order of
declaration
2. Context-specific trace
3. Flash freeze
4. Debugger call
5. Oracle crash
Copyright © Oracle Corporation, 2001. All rights reserved.
Precedence of Flash Freeze Actions
Triggers can be set for an instance using the EVENT parameter in the initialization file. The
trigger setting for event based flash freeze can be specified at run time via alter system only.
There will be an explicit check to disallow such a setting either in the alter session driver
(KKY) or in the parser code (PRSA).
Different actions for the same trigger event have a built-in precedence. The flash freeze action
will have the following precedence:
• Context-independent traces in order of declaration
• Context-specific trace
• Flash freeze
• Debugger call
• Oracle crash
Improved Diagnosability Features 1-7
Examples
SQL>
SQL> ALTER
ALTER SYSTEM
SYSTEM SET
SET EVENT=
EVENT=
22 "600
"600 flashfreeze
flashfreeze on
on error
error 1301,proc=PMON";
1301,proc=PMON";
System
System altered.
altered.
SQL>
SQL> ALTER
ALTER SYSTEM
SYSTEM SET
SET EVENT=
EVENT=
22 "10295
"10295 flashfreeze,proc=BGS,instance=single";
flashfreeze,proc=BGS,instance=single";
System
System altered.
altered.
Copyright © Oracle Corporation, 2001. All rights reserved.
Examples
The examples show events being set with the ALTER SYSTEM command. The same results
would occur if the event were set in the initialization parameter file. The following command
would trigger a flash freeze whenever internal error 1301 occurs in PMON:
SQL> ALTER SYSTEM SET EVENT =
2 "600 flashfreeze on error 1301, proc=PMON";
The following command would trigger a flash freeze in any background processes whenever
event 10295 occurs in a background process:
SQL> ALTER SYSTEM SET EVENT = "10295 flashfreeze, proc=BGS";
The full syntax of the EVENT clause is as follows:
<event name><action>{:<event name><action>}
where:
• <event name> is a symbolic name for the event, or an optional event number
• <action> is <action keyword><action qualifiers>
and
<action keyword> is "trace"|"debugger"|"crash"|"flashfreeze"
Improved Diagnosability Features 1-8
Current Limitations of Event-Driven Flash
Freeze
• Can only distinguish between different types of
ORA-600 errors at the first argument level
• Cannot define specific type of process in
certain cases, such as DBWR and PQ
Copyright © Oracle Corporation, 2001. All rights reserved.
Examples (continued)
The action qualifier for the action "flashfreeze" is ""|"off"|"on <error tag>"
|"after <N> times"|"proc = all | fgs | bgs | <pid> | <pname>"
where
• "" does nothing because flash freeze requires a qualifier
• "off" disables flash freeze action for this event
• "on <error tag>" where <error tag> is "error <first argument
of internal error>"
• "after <N> times" causes flash freeze after <n> occurrences of this event
• "proc = all | fgs | bgs | <pid> | <pname>" where all means
all processes; bgs means all background processes; fgs means all foreground
processes; <pid> is an Oracle process ID; and <pname> is an Oracle process name
such as LMON, PMON, LMD0, and so on.
Current Limitations of Event-Driven Flash Freeze
The current event-driven flash freeze product is unable to distinguish between different types
of internal (ORA-600) errors other than by the first argument value, using the on <error
tag> syntax of the action qualifier clause. Similarly not all background process types can be
distinguished in the <pname> option of the proc action qualifier.
Overall, this initial release of event-driven flash freeze is not very easy to use. The syntax
alone is compatible with the EVENT syntax, which is pretty bad already. The feature is
intended for the experts, hence ease-of-use is not a key feature. The tool is aimed at WWS,
Bugs and Defects Escalation (BDE), and Diagnostic and Defect Resolution (DDR) personnel,
and may also help developers and testers in debugging the new features.
Improved Diagnosability Features 1-9
Summary
In this lesson, you should have learned how to:
• Identify uses for event-driven flash freezes
• List the features of an event-driven flash freeze
• Set events for an event driven flash freeze
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 1-10
Copy-on-Write SQL-Based Debugger
Improved Diagnosability Features 2-1
Objectives
After this lesson, you should be able to:
• Identify when to use the copy-on-write (COW)
SQL-based debugger
• Prepare an SGA for use with the debugger
• Execute SQL queries using the debugger
• Identify the limitations and restrictions of the
debugger
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 2-2
What is a COW Debugger?
• Debugger operations
– Requires flash-frozen instance
– All Oradebug functionality availability
– SQL queries may be issued without impacting the
SGA, for example, the Shared Pool
– SQL queries for debug can be executed without
latches
• COW features
– Copies on write
– Modifications to the SGA as a result of any debug
operation do not affect the frozen SGA
– Implemented by making a process-private copy of
the modified page with the debugger process
Copyright © Oracle Corporation, 2001. All rights reserved.
What is a COW Debugger?
The copy-on-write (COW) debugger allows an analyst to examine the contents of a flash-
frozen instance using standard SQL commands to query the contents of the instance. The
COW debugger has the following characteristics:
• Requires a flash-frozen instance
• Can use all of the Oradebug functionality
• Allows SQL queries to be executed against fixed tables and views without
– Impacting the frozen contents of the SGA, including the Shared Pool
– Requiring any latches
• Allows the ALTER SYSTEM DUMP command to be executed if connected to a real
instance, as opposed to a standalone SGA
The features permitting this include:
• The use of copies of memory pages when a write to memory is necessary
• Changes to the SGA resulting from a debug operation occur in copied pages
• The copied pages required to support SGA changes are stored in process-private
memory by the debugger process
Improved Diagnosability Features 2-3
Benefits of a COW Debugger
• Debugging information can be gathered
– Quickly and completely, reducing initial
downtime and preventing future failures for
the same reason
– Locally but analyzed remotely, such as at a
World Wide Support site
– Without installing new binaries or database
images
• The COW debugger
– Is an integral part of Oracle
– Has a small localized footprint
– Helps provide an easy-to-diagnose system
Copyright © Oracle Corporation, 2001. All rights reserved.
Benefits of a COW Debugger
Requirements for better diagnosability arise from the needs of Oracle’s customers. The main
issues for these customers are:
• A minimum known downtime if a failure should occur, and preventing the same failure
from re-occurring; therefore causing multiple outages.
• Customers and support analysts/engineers want to be able to gather diagnostic
information quickly but completely. The first issue generally jeopardizes the second; in
other words, we may be able to recover or fail-over quickly, but it generally means
sacrificing sufficient diagnostics. On the opposite end, we can gather more complete
diagnostics (although limited today with the current tools at hand), by sacrificing
availability. Ultimately, either can result in lost revenue for the customer. With internet
and e-commerce sites rapidly increasing and longer business hours, systems are rapidly
approaching true “24 x 7 x 365” availability requirements.
• Customers prefer remote analysis and no changes to their environment. The debugger
architecture enables writing to file and shipping of the in-memory state of the database
to a remote location for deferred analysis. When not faced with chronic or unrestartable
problems, the customer can ship the in-memory state, restart the system, and allow
normal operations to continue. But when faced with a problem that needs to be
debugged at a customer site, no new database images or binaries need to be installed
using the COW debugger.
• Customers prefer that new software is not installed on their systems unless absolutely
necessary. The dynamic verb compilation and execution system allows new software
pieces of code to be executed within the context of existing Oracle images and binaries.
Improved Diagnosability Features 2-4
Options for COW Debugger Use
• Instance is either frozen or an off-line copy
– A instance is frozen using flash freeze
– An off-line copy is made by copying the
SGA contents to a file, which may be used
instead of the original SGA for debug
purposes
• The instance can be resumed, if required,
following the debugging steps since it is not
touched by the COW SQL debugger
Copyright © Oracle Corporation, 2001. All rights reserved.
Options for COW Debugger Use
The actual implementation of the debugger is left open; both stand-alone and Oracle shadow
based debuggers are possible. The process private mappings are implemented as Copy-On-
Write (COW). The idea is as follows— the user connects to an Oracle instance in a special
stand-alone mode or using an Oracle shadow. The Oracle instance must either be flash frozen
or its SGA must be an off-line copy loaded from a file. The chosen implementation of copy-
on-write is a simple one that spans most OS and machine independent boundaries with the
least impact on Oracle operating system dependent (OSD) modules. This simple scheme keeps
the impact of the changes mostly in the generic layers of the code. The SGA is written to a file,
the SGA is then unmapped, and then the file is mapped back as copy-on-write.
The above properties allow the user to compile and execute SQL queries on fixed tables. The
SQL compilation process is possible because it reads through shared pool/library cache latches
and can actually create the shared cursor as if it were in the SGA. In reality, the shared cursor
is in private memory pages, but looks to the mapping process as if those are SGA pages. The
real SGA segment is not modified in any way, hence the frozen instance can even be resumed,
if desired. However, any resumption that needs to occur (in shared memory SGA
implementations) involves IPC through the use of shared memory; this implies a new Oracle
shadow needs to be brought up rather than issuing the "ORADEBUG
GET_SGA_SNAPSHOT" command, thus ensuring that the user is connected to the actual
global SGA rather than a view private snapshot.
Note: The offline functionality was available in Oracle8i, but the ability to map a copy of the
offline data into the debugger is available only with Oracle9i.
Improved Diagnosability Features 2-5
When to Use the COW Debugger
• To perform on-line diagnosis of a failed or
failing instance, or instances in the case of
Oracle9i Real Application Clusters
• To perform off-line or remote diagnosis of a
failed instance
• To perform concurrent debug of the same
failed instance
• To send a copy of diagnostic data to World
Wide Support for debugging
Copyright © Oracle Corporation, 2001. All rights reserved.
When to Use the COW Debugger
The COW SQL debugger is especially useful under the following circumstances:
• To perform on-line diagnostics of a failed or failing instance (or instances in the case of
Oracle9i Real Application Clusters). The instance(s) can be flash frozen using user
commands or triggers. Support engineers can look at the current SGA state using
views into standard fixed tables. An option would then be available to either resume or
terminate the instance (resuming the instance would allow execution to continue along
its previous path which may ultimately be instance death).
• To perform off-line or remote diagnostics of a failed instance. The SGA of the failing
instance can be written to a file, which can be sent to a World Wide Support center for
analysis and debugging. In the case of Real Application Clusters, the failed instance
can be flash frozen and de-registered from the rest of the database, thereby allowing
the surviving Real Application Cluster instances to continue.
• To perform concurrent debug of the same failed instance
– This is especially useful in the field where on system failure, time is critical, and
there is need to analyze the problem as quickly as possible. Multiple instances of
the debuggers can be spawned in parallel and any number of them can be
destroyed to restart new ones.
– The key in copy-on-write debugging is that the original state of the database is
unaltered. So a new debugger can be used to issue a whole bunch of commands.
This in turn creates a derived private in-memory view of the database state as a
side effect of copy-on-write.
– Extensive peeking of the view-private data has the benefit of extracting valuable
state information that may point to the problem. But since the extraction process
also modifies some view private SGA pages, we may reach a point where
certain SQL queries may arbitrarily hang as a result of all information for the
query not being readily available in a consistent manner and primarily because
of contention on synchronization resources. This is a reasonable point to discard
the debugger instance and spawn a new one with the original flash frozen state
of the database.
Improved Diagnosability Features 2-6
Functions of the COW Debugger
• Provides SQL access to fixed tables and views
– Online with a flash-frozen instance
– Off-line with an SGA snapshot
• Enforces security by allowing only privileged
logins
• Supports Oracle9i Real Application Clusters
Copyright © Oracle Corporation, 2001. All rights reserved.
Functions of the COW Debugger
The COW Debugger has the following characteristics and functionality:
• Performs online debugging by providing SQL access to the fixed tables and views on
SGA of the flash frozen instance.
• Performs off-line debugging by providing SQL access to the fixed tables and views on
the SGA snapshot which is written to a file and brought to a possibly different machine.
• Does not interfere with the current state of the SGA, or any database persistent state on
disk. The standard debugger will only work when flash freeze has been invoked in the
terminating mode, which assures that the instance is not restartable. The primary goal
of the debugger is to analyze system failure and there is no good reason to resume an
instance.
• Allows SELECT from the fixed tables/views using SQL as long as sorts, caused by
ORDER BY or GROUP BY clauses, can be completed in memory.
• Enforces security and access limitations by allowing only internal logins to use this
functionality.
• Allows dumping of data files and control files in the flash-frozen mode.
• Supports multi-instance (Oracle9i Real Application Cluster) configurations.
• Coded for minimal maintenance overhead, including the differences required to operate
in the flash-frozen or off-line mode.
Improved Diagnosability Features 2-7
Command Line Tools
• Command to prepare for online debugging of
flash-frozen instances
– Copy SGA to an identified file
– Unmap the SGA
– Remap the SGA in a copy-on-write mode
• Command to prepare for off-line debugging of
SGA snapshots written to a file
– Copy SGA to a file
– Read contents into a memory segment
Copyright © Oracle Corporation, 2001. All rights reserved.
Command-line Tools
GET_SGA_SNAPSHOT: for the online debugging of flash-frozen instances.
Online debugging of flash-frozen SGA requires that the current SGA contents be mapped into
a file before the high-level SQL commands are issued. This is needed to enable the Copy-On-
Write debugging, which guarantees that the current SGA contents is not destroyed. Therefore,
in order to set up the COW debugging on the frozen system’s SGA, GET_SGA_SNAPSHOT
command must be used first inside an Oradebug session:
SQL> oradebug
SQL> GET_SGA_SNAPSHOT 'filename'
where filename is a name of the file to which SGA is mapped. This command writes the
SGA to the specified filename using full access path. It then unmaps the SGA and remaps the
SGA in a copy-on-write mode. If the instance is not flash frozen, the command will return an
error message with status to indicate that a flash freeze must be in effect prior to issuing this
command. If the filename already exists or the disk is out of space, the appropriate messages
are flagged. The start of the SGA file contains special header information with a checksum to
identify it as the SGA. Non-SGA files (with incorrect headers) will not be mapped. Similarly,
files without access permission will not be mapped.
GET_SGA_OFFLINE: for the off-line debugging of SGA snapshots written to a file.
Off-line debugging of the SGA snapshot is performed by first saving SGA contents into a file,
and then reading it into a memory segment. In order to set up off-line debugging using this file,
GET_SGA_OFFLINE command must be used first inside the Mapsga utility:
%MAPSGA GET_SGA_OFFLINE 'filename'
where filename is a name of the file to which SGA has been saved.
Improved Diagnosability Features 2-8
Major Debugging Usage
1. Flash frozen exclusive instance
2. Off-line analysis of exclusive instance’s SGA
3. Flash-frozen and detached Real Application
Cluster instance
4. Off-line analysis of single Real Application
Cluster instance’s SGA
5. All Real Application Cluster instances flash-
frozen
6. Off-line analysis of all instances’SGAs
Copyright © Oracle Corporation, 2001. All rights reserved.
Major Debugging Usage
The major situations in which the COW debugger is expected to be used are listed in the slide.
Improved Diagnosability Features 2-9
Example: Flash Frozen Exclusive Instance
%sqlplus
%sqlplus "/
"/ AS
AS sysdba"
sysdba"
SQL>
SQL> REM
REM Invoke
Invoke flash
flash freeze
freeze
SQL>
SQL> oradebug
oradebug ffbegin;
ffbegin;
SQL>
SQL> REM
REM Create
Create view
view private
private SGA
SGA
SQL>
SQL> oradebug dmpcowsga "/dbs/memdump";
oradebug dmpcowsga "/dbs/memdump";
SQL>
SQL> REM
REM Now
Now select
select from
from fixed
fixed tables
tables
SQL>
SQL> SELECT
SELECT ** FROM
FROM v$bh;
v$bh;
Copyright © Oracle Corporation, 2001. All rights reserved.
Example: Flash Frozen Exclusive Instance
In the example, the online analysis of an exclusive instance is prepared and started. The user
connects with a privileged account, freezes the instance, and maps the SGA. The contents of
the SGA can then be queried using standard fixed tables, such as V$BH, as shown.
Improved Diagnosability Features 2-10
Example: Off-line Exclusive Instance
%mapsga
%mapsga get_sga_offline
get_sga_offline /dbs/memdump;
/dbs/memdump;
%sqlplus
%sqlplus "/
"/ AS
AS sysdba"
sysdba"
SQL>
SQL> REM
REM Now
Now select
select from
from fixed
fixed tables
tables
SQL>
SQL> SELECT
SELECT ** FROM
FROM v$bh;
v$bh;
Copyright © Oracle Corporation, 2001. All rights reserved.
Example: Off-line Exclusive Instance
In the example, the off-line analysis of an exclusive instance is prepared and started. The user
initially maps the SGA using the MAPSGA utility. The user then connects INTERNAL and
queries the contents of the SGA using standard fixed tables, such as V$BH, as shown.
Note that you must perform off-line analysis on the same machine, or one of the same
platform, as the one from which you copied the SGA.
Improved Diagnosability Features 2-11
Real Application Cluster Debugging
Debugging a single Real Application Cluster
instance is similar to debugging a single
exclusive instance
• Lock information may be stale
• In primary/secondary situations with just one
active instance, the distributed lock manager
information is probably not important for
debugging
Copyright © Oracle Corporation, 2001. All rights reserved.
Single Instance Real Application Cluster Debugging
The procedure for debugging a single Real Application Cluster instance is not particularly
different from debugging a single exclusive instance. The difference is that if the instance
being debugged is detached, while other instances are not frozen, distributed lock manager
(DLM) information available through fixed views/tables may be stale even for the online
debugging. This may still be enough to look at DLM data corruption, but the user should
understand that he/she operates under potential inconsistencies.There is one important case in
which we expect this kind of debugging to be useful, and that is HA configuration. The latter
uses Real Application Clusters mostly as a standby, hence the internal errors are much less
likely to be DLM-related. In this case, detaching the instance and debugging should work in
most cases, since we’ll be mostly looking at the non-DLM structures.
Debugging all instances
If all Real Application Cluster instances are frozen, DLM information should be current. The
only caveat is that the COW debugger will not initially support GV$ views, hence information
in each SGA has to be analyzed independently through explicit multiple connections.
Improved Diagnosability Features 2-12
Usage Rules
• Queries on fixed tables/views with already
mentioned limitations to prevent the use of
sort segments
• Dump individual data blocks using ALTER
SYSTEM DUMP DATAFILE command
• Dump control file information using ALTER
SYSTEM DUMP CONTROLFILE command
• The entire set of Oradebug and flash freeze
commands will be available
Copyright © Oracle Corporation, 2001. All rights reserved.
Usage Rules
Not all SQL commands are possible in the debugging mode. Generally speaking, the user can
issue the same queries as are possible today when a database is not opened. More precisely, the
user will be able to do the following:
• Queries on fixed tables/views with already mentioned limitations.
• Dump individual data blocks using ALTER SYSTEM DUMP DATAFILEcommand.
• Dump control file information using ALTER SYSTEM DUMP CONTROLFILE
command.
• The entire set of Oradebug and flash freeze commands will be available.
Improved Diagnosability Features 2-13
Current Limitations
• Not all SGA structures are visible through fixed
tables or views
• Swap space could be inadequate
• Cursor compiles can alter SGA contents
• Queries requiring sorts may not work
• Corrupted structures may cause SQL to fail
• Not all functions are available on every
platform that supports Oracle9i
• Not supported on HP and Windows platforms
Copyright © Oracle Corporation, 2001. All rights reserved.
Current Limitations
Some of the limitations of the COW debugger come from the basic server infrastructure, others
from the current implementation. The intrinsic limitation is that not all SGA structures are
viewable through the fixed tables/views, and even those which are may only be partially
represented.
The implementation-specific limitations include:
• Swap space can be exhausted during cursor compilation, if, for example, all objects in
the shared pool are pinned at the time of freeze and a large number of SGA pages are
accessed. In general, the copy-on write implementation uses swap only for the pages
that are modified, so there are only a few cases when swap space might run out.
• Compiling cursors into the shared pool changes the shared pool contents. It is quite
possible that the new state of the shared pool will not contain the clues that were
present in the original state. However, since the COW debugger only creates the local
view, which can be discarded and restarted.
• Some queries containing ORDER BY/GROUP BY clauses will not work. Memory is
used as much as possible, even beyond SORT_AREA_SIZE, but there may be cases
when it is not be possible to avoid the use of temporary space. In these cases, the
queries will not work.
• Some of the structures which are traversed either when compiling SQL or when
executing it may be in a corrupted state, because the SGA was in an arbitrary state
when it was frozen/dumped. This may cause compilation/execution to fail. Latch
recovery callbacks may be invoked at some appropriate points of execution, but it may
not always be enough.
• HP and Windows implementation of this functionality is not currently available.
Improved Diagnosability Features 2-14
Summary
In this lesson, you should have learned how to:
• Identify when to use the COW SQL-based
debugger
• Prepare an SGA for use with the debugger
• Execute SQL queries using the debugger
• Identify the limitations and restrictions of the
debugger
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 2-15
Enhanced Oracle9i Real Application Clusters
Diagnosability
Improved Diagnosability Features 3-1
Objectives
After this lesson, you should be able to:
• Identifiy the components of the diagnosability
architecture for Oracle9i Real Application Clusters
• Explain the functions of the DIAG process
• Differentiate in-memory and on-disk diagnosability
data
• Select tools for diagnosing Oracle9i Real
Application Clusters hangs and crashes
• Set trace levels with initialization parameters and
the ALTER TRACE command
• Use X$ views to observe tracing information
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 3-2
Purpose and Features
• Sufficient “diagnosability data”
– to analyze a problem whenever it occurs
– to minimize the need to reproduce a
problem
• Support and development staff controls the
diagnosability data:
– Methods of collection
– Store either in-memory or on disk
• Interactive tools for analysis
• Single system view of the cluster to control the
mechanisms and tools
Copyright © Oracle Corporation, 2001. All rights reserved.
Purpose and Features
The Oracle9i Real Application Clusters diagnosability feature addresses the following
requirements:
1. Optimal amount of diagnosability data (run-time trace data along with the other data
such as the traces collected on demand and the output from the different system
dumps) is gathered on a continuous basis such that there is enough information about
the current and the past (finite number of) system states for analysis of a problem
whenever it happens.
2. The kind of diagnosability data and its amount reduces the need to reproduce the
problem. Ideally, you should not have to reproduce a problem in order for it to be
diagnosed and resolved.
3. Support and development staff control the gathering, storage, and analysis of the
diagnosability data. Gathering refers to all the mechanisms controlling the collection of
diagnosability data on an Oracle9i Real Application Cluster. These include setting
trace events, specifying initialization parameters, and issuing commands for multiple
nodes interactively for data collection, and so on. Storage refers to all the mechanisms
that facilitate temporary and permanent saving of collected data. These could be in-
memory buffers or on-disk storage structures (for example, files), their layout, storage
parameters, and so on. Analysis refers to the manual processing of the data to diagnose
problems. For example, you can turn the data collection on and off, control the rate of
collection, and define the amount of history that needs to be retained.
4. Interactive tools dump and analyze the diagnosability data on-line.
5. Off-line tools to do the automatic analysis of the diagnosability data dumps.
6. There is a single system view of the cluster facilitating single point of control for its
manageability. All the manageability mechanisms including the tools (in 1 thorough 5
above) are cluster-aware.
Improved Diagnosability Features 3-3
Purpose and Features
• Sufficiently robust to manage diagnosability
data during database startup and shutdown
• Minimize time to diagnose a problem using
minimal system resources
• Tunable and reliable: provides acceptable level
of system overhead without causing hangs or
crashes
Copyright © Oracle Corporation, 2001. All rights reserved.
Purpose and Features
The Oracle9i Real Application Clusters diagnosability feature meets these additional
requirements:
• Sufficiently robust to ensure availability of the diagnosability information and the
mechanisms even in the worst case scenarios such as partitioning of the cluster due to
network failure. Tools used in diagnosis must not hang and the Oracle9i Real
Application Clusters diagnosability feature should work during the startup and
shutdown of the database.
• Cost-effective, using minimal system resources and minimizing the time to diagnose a
problem.
• Does not adversely affect the performance, scalability and availability of the system.
Since the diagnosability feature will have an affect on the system performance in the
absolute sense, you can tune the diagnosability level for acceptable loss in
performance.
As an example, the diagnosability framework will make data in X$TRACE available even
when an instance crashes by dumping those data to *.trw files in cdmp directory.
Additionally, because the data for the crashed instance may not be a complete view of the
database in a cluster, the diagnosability framework will allow dumps of data in X$TRACE of
all other instances in the same database when the crash happens. This is done through DIAG
processes.
Improved Diagnosability Features 3-4
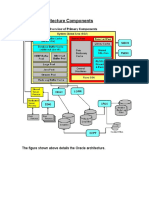
Diagnosability Framework: Architecture
On-line SGA
toolset Read and
Trace buffer B[i] Process
modify
P[i]
commands
Write trace records
Trace buffer B[j]
Control
Process
commands
P[j]
DIAG
Read trace Dynamic
Write buffer B[j] view on
trace trace
buffers buffer
to disk
Trace file
for P[i]
Off-line
review
Trace file
for P[j]
Copyright © Oracle Corporation, 2001. All rights reserved.
Diagnosability Framework: Architecture
The graphic shows the diagnosability-data manageability components and their relationship to
the Oracle database on a node. It represents the diagnosability framework component
architecture as viewed on a single node. The Enhanced Oracle9i Real Application Clusters
diagnosability framework is essentially based on the per node data collection framework. Off-
line analysis collates the per node diagnosability data to construct global order of events to
diagnose Oracle9i Real Application Clusters problems.
The key components of the architecture include:
• Trace buffers for each process in the SGA
• Dynamic view on the contents of the in-memory trace buffers
• The trace background process, DIAG, that writes trace information to disk and
coordinates with other DIAG processes working for other instances
• Disk-based copies of trace information
The on-line toolset used to control the work done by the DIAG process group includes
Oradebug commands and tools such as poradebug, lkdebug, and the hang analyzer. The
off-line review tools include any editor with which you can browse the trace files.
Improved Diagnosability Features 3-5
DIAG Background Process
Real Application Cluster Real Application Cluster
instance 1 instance 2
Tracing Tracing
DIAG DIAG
process process
Trace buffer Trace buffer
SGA SGA
Copyright © Oracle Corporation, 2001. All rights reserved.
DIAG Background Process
The diagnosability process (DIAG) is a per-instance background process that is present
throughout the life of a Real Application Cluster instance to monitor and help diagnosing any
unexpected behavior on that instance.
The goal of the DIAG processes is to provide a simple communication method for exchanging
messages of various sizes among each other across nodes in a cluster environment. Most of the
features in the messaging model are very similar to those found in the Cluster Group Services
(CGS) and Group Membership Service (GMS) processes.
Improved Diagnosability Features 3-6
Characteristics of the DIAG Process
• Independent of the database instance
– Failure does not bring down the instance
– Automatically restarted by PMON
– DIAG process group isolates diagnostic-
related services
• Peer-to-peer communication
• Communication isolation from the database
instance using separate logical connection
• Type of communications
Copyright © Oracle Corporation, 2001. All rights reserved.
Independence from the Database
To prevent problems with the diagnostic activity affecting an active database instance, the
DIAG process works outside the normal set of background process paradigms. In particular,
the failure of a DIAG process will not cause a related instance failure. A failed DIAG process
will be restarted automatically by the PMON process.
A process group for DIAG processes ensures that diagnostic related services are only available
to the DIAG group members. This process group is implemented to eliminate problems or
conflicts due to other Oracle9i Real Application Cluster components (such as DLM) which
may affect operations of the DIAG processes. This process group is on the same
implementation level as CGS, so the members of the DIAG process group do not subscribe to
any membership related services provided by the CGS.
Peer-to-peer Communication
Only a DIAG process of an instance can communicate with its peer (a remote DIAG process)
on any other instance . This simplifies the communication model simple while also avoiding
potential concurrency or deadlock related issues which could arise if the other background or
foreground processes communicated directly with remote DIAG processes.
Communication Isolation
If a local foreground or background process wants to talk to a remote DIAG process, it must
first send the message to the local DIAG process which will then forward the message to the
appropriate destination. This preserves the membership privileges of the DIAG group and
helps achieve communication isolation and a communication protection policy from
interference by the other non-member processes.
Type of Communications
The amount of data transfer for the trace management communications is relatively small in
comparison to that for the Oradebug commands. For example, Oracle9i Real Application
Clusters-aware hang analyzer sends results of local hang analysis on each instance, which may
be several thousand bytes for a multiple-session instance, to the initiating node for global hang
analysis. The DIAG demon handles both the small and large data transfers. However, large
data transfer occurs only during Oradebug sessions and most of these operations are not
frequently invoked, hence performance is not a problem.
Improved Diagnosability Features 3-7
Characteristics of the DIAG Process
• Master node election
• DIAG process group reconfiguration
• Recovery
Copyright © Oracle Corporation, 2001. All rights reserved.
Master Node Election
The node with the lowest node id is elected as the master. The master node is responsible for
message passing is selected in the following situations:
• Node hosting is the master DIAG is shutdown
• Master DIAG dies unexpectedly as a result of instance death
• A new instance on the node with the lowest node id joins the group
DIAG Process Group Reconfiguration
A DIAG group reconfiguration occurs when an instance leaves the cluster or a new instance
starts. When a DIAG process receives a reconfiguration-propose message, any outstanding
operations will be aborted, and rolled back if necessary. During DIAG process group
reconfiguration, no operation message except those related to reconfiguration are sent among
DIAG processes until the reconfiguration completes.
Recovery
All DIAG processes preserve a consistent state before and after DIAG reconfiguration or
master election. In order to enforce this consistency, any outstanding operation is aborted, and
rolled back if necessary, before the any change in group state is made. Also, each sender keeps
a copy of messages sent to the master until all operation-done messages are received for this
message. In this way, message replay for recovery is possible in case of any change in DIAG
process group.
Improved Diagnosability Features 3-8
Characteristics of the DIAG Process
• Message ordering
• Communication model
– General features
– Protocols
• Process-adaptive timeout mechanism
• Master node election
Copyright © Oracle Corporation, 2001. All rights reserved.
Message Ordering
When a node wants to send a message to the multiple nodes in a broadcast or multicast
manner, it sends the messages to the master node which forwards the message to the
appropriate destination nodes. If multiple messages are received by the master, it puts the
messages in a local first-in, first-out (FIFO) queue.
Communication Model
General Features
When the first Oracle9i Real Application Cluster instance starts up, a DIAG process group is
created. Each time an new instance starts up, its DIAG process joins the DIAG process group.
A DIAG group reconfiguration is initiated by the group member who discovers the change in
membership so that all the existing group members can update with the latest membership
information.
A separate port, in additional to those used by LMD and LMON, is created for each DIAG and
its information is published to other remote DIAG processes.
Protocols
There are two types of communication protocols, namely port-based IPC and memory-mapped
copying, used for inter-instance communication between DIAGs. The port-based IPC
mechanism is targeted for message passing between the DIAG processes in a broadcast or
multicast manner. Memory-mapped operation is used for passing large amounts of data which
would tax the IPC mechanism.
Process-Adaptive Timeout Mechanism
Communication problems or hanging processes may delay message passing between nodes.
Since message processing times may vary among nodes, the largest delay will be chosen as a
final timeout value to determine whether a node is hanging.
Improved Diagnosability Features 3-9
In Memory Data Storage
• Clients can tune in-memory storage
• Buffers for always-on tracing are in the SGA
• One trace buffer per process
• Different sizes of trace buffers can be allocated for Oracle
processes
• Trace buffers
• Are circular
• Can be tuned to hold the required amount of history
• Can be written out to a disk file
• Of dead processes can be retrieved and preserved
Copyright © Oracle Corporation, 2001. All rights reserved.
In Memory Data Storage
The on-disk trace data storage has the following features:
• Clients have the capability to specify and control (tune) the in-memory storage
characteristics using initialization parameters at the time of database start-up and using
SQL statements or an interface such as ORADEBUG during runtime.
• The in-memory trace buffers for always-on tracing are in the SGA.
• There is one trace buffer per process.
• Different sizes of trace buffers for Oracle processes can be allocated.
• The trace buffers are circular.
• The length of the trace buffers should be tuned to hold the required amount of history to
avoid losing data when the buffer fills and its overwrites the old contents.
• The trace buffers can be written to an on-disk file.
• The in-memory trace buffer of a dead process on disk can be retrieved and preserved.
Improved Diagnosability Features 3-10
On-Disk Trace Data Storage
• Clients can tune the storage characteristics
• File names are unique across the cluster
• Each file contains a header with information common to all
the traces contained in that file
• Stores formatted (ASCII) as well as the unformatted (binary)
data
• Files holding trace data can be by instance or by process
• Trace data files
– Should be larger than the per-process memory circular
buffers
– Should be sufficient to hold the required amount of
history
– Are circular
• Always-on trace mechanism reside in a user-defined directory
specified by the user
Copyright © Oracle Corporation, 2001. All rights reserved.
The on-disk trace data storage has the following features:
• It stores the diagnosability data, full and partial results of the data analysis and the reports,
in files on the disk.
• Clients have the capability to specify and control (tune) the on-disk storage characteristics
using initialization parameters at the time of database start-up and using SQL statements or
an interface such as ORADEBUG during runtime.
• The trace data file names are unique across the nodes in the cluster.
• Each trace data file contains a file header that bears information common to all the traces
contained in that file. The files headers for always-on traces are the same as the file header
for the currently implemented on-demand trace files.
• It stores formatted, ASCII, data as well as the unformatted, binary, data in files on the disk.
• The on-disk files holding trace data can contain data on a per instance basis or on a per
process basis.
• The size of the trace data file is more than the size of the per-process in-memory circular
buffers. It should be sufficiently large to hold the required amount of history as specified
by the client.
• The on-disk trace data files are circular.
• All the trace files generated by the always-on trace mechanism reside in a separate trace
directory specified by the user. This directory can be same or different from the directory
where the current trace files reside.
Improved Diagnosability Features 3-11
Example Trace File
Oracle9i
Oracle9i Enterprise
Enterprise Edition
Edition Release
Release 9.0.0.0.0
9.0.0.0.0 –– Beta
Beta
With
With the
the Partitioning
Partitioning and
and Real
Real Application
Application Clusters
Clusters options
options
JServer
JServer Release
Release 9.0.0.0.0
9.0.0.0.0 –– Beta
Beta
ORACLE_HOME
ORACLE_HOME == /ade/ilam_rdbms_lrg/oracle
/ade/ilam_rdbms_lrg/oracle
System
System name:
name: SunOS
SunOS
Node
Node name:
name: dlsun1932
dlsun1932
Release:
Release: 5.6
5.6
Version:
Version: Generic_105181-14
Generic_105181-14
Machine:
Machine: sun4u
sun4u
Instance
Instance name:
name: lrg
lrg
Oracle
Oracle process
process number:
number: 44
Unix
Unix process
process pid:
pid: 24026,
24026, image:
image: oracle@dlsun1932
oracle@dlsun1932 (LMON)
(LMON)
Copyright © Oracle Corporation, 2001. All rights reserved.
Example Trace File
Visit the URL
http://opsm.us.oracle.com/diagnosability/crash.html
for a reference to sample dump trace files generated by the DIAG daemon and a brief
explanation about how dumps are created and interpreted.
Below are the first few lines from a trace file, lrg_lmon_24026.trw, generated by the
diagnostic utility from the LMON process on a Real Application Cluster. The entries in the
body of the trace file consist of the following elements:
• Timestamp (in %x:%x format)
• Oracle process number
• Session number
• Event id
• op code
• Data
Oracle9i Enterprise Edition Release 9.0.0.0.0 – Beta
With the Partitioning and Real Application Clusters options
JServer Release 9.0.0.0.0 – Beta
ORACLE_HOME = /ade/ilam_rdbms_lrg/oracle
System name: SunOS
Node name: dlsun1932
Release: 5.6
Version: Generic_105181-14
Machine: sun4u
Instance name: lrg
Oracle process number: 4
Unix process pid: 24026, image: oracle@dlsun1932 (LMON)
B7AAEEEB:00000009 4 0 10280 1 0x00000004
B7AAEEEB:0000000A 4 0 10401 26 KSXPMAP: client 1
…
Improved Diagnosability Features 3-12
On-Line Data Analysis Tools
• Oradebug
• Requirements
– Non-intrusive
– Should not hang or crash the database
instance while in use
– Must continue to work even if one or more
nodes join or leave the cluster
– Use a well-defined user interface
Copyright © Oracle Corporation, 2001. All rights reserved.
On-Line Data Analysis Tools
Most of the tools that are currently present in Oracle facilitate on-line analysis. These attach to
a live oracle database to read and dump data structures in SGA. The basic tool for analysis is
Oradebug.
Oradebug
• poradebug: set of Oradebug commands / options which make it Oracle9i Real
Application Cluster aware.
• lkdebug: Oradebug command to dump out lock database objects from SGA.
• Nsdbx: Oradebug command to dump out CGS name-service data objects from SGA.
• hang_analyze: Oradebug command to perform hang analysis. This command is
Oracle9i Real Application Cluster aware.
• oradebug commands to dump system-state, process-state, buffer-cache, heaps, and so
on.
• other miscellaneous oradebug commands.
Functional Requirements
The generic functional requirements of any on-line analysis tool include:
• The tool should be non-intrusive, that is, it should not perturb the run-time behavior of
the database system, should not cause a hang or crash the system.
• The tool itself should not hang or crash while in use.
• The tool should continue to work (have a well-defined behavior) on the surviving
nodes even if one or more nodes join or leave the cluster.
• There should be a well defined user interface.
Improved Diagnosability Features 3-13
Real Application Clusters-Aware Hang
Analyzer
The Oracle9i Real Application Clusters-Aware
Hang Analyzer performs in two phases
• Phase 1
– Each node performs a normal (exclusive)
hang analysis
– Results sent to initiator node
• Phase 2
– Initiator node identifies globally blocked
resources and events (blocked set)
– Initiator node broadcasts to the nodes
– Each node reports sessions holding
members of the blocked set to the initiator
– Global hang chains are constructed and
written to an output file by the initiator
Copyright © Oracle Corporation, 2001. All rights reserved.
Oracle9i Real Application Clusters-Aware Hang Analyzer
The hang analyzer command of ORADEBUG works for Oracle9i Real Application Clusters,
detecting hang chains that are spread across multiple nodes of the server. The Oracle9i Real
Application Clusters-aware hang analyzer executes in two phases to find all the hang chains in
the cluster.
Phase 1
Whenever there is a perceived hang the hang analyzer is invoked using the parallel mode of
the oradebug from one node of the cluster, termed as the initiator node. Parallel oradebug
propagates the hang analyze command to all the other nodes of the cluster. On receipt of the
command, each node performs the local hang analysis (same as in exclusive mode) and sends
its hang chains over to the node that initiated the command. These hang chains are complete or
partial. All the partial hang chains typically have a session which is blocked on some global
resource or event.
Phase 2
Once the initiator node receives the local hang chains from all the nodes, it finds all the
globally blocked sessions from the partial hang chains. The initiator node consolidates all the
resources and events which have global blockers on the nodes of the cluster. This is the
blocked set. The initiator broadcasts this blocked set to all the nodes of the cluster. On receipt
of the blocked set each node tries to find out whether it has the sessions that are holding the
resources or events in the set. All such sessions which are found to be holding the resources
and events in the blocked set are identified by each node and compiled as a set of blocker
sessions. This set is forwarded to the initiator. Once the initiator node has received all the
blocker sets from all the nodes, it completes the partial hang chains collected in phase 1, by
joining one or more of them using the global blocking sessions from the blocker set
consolidated in phase 2. These blocking sessions are the ones that are holding the resource or
the event on which the session at the end of the partial hang chain is blocked. The resulting
global hang chains are written to an output file by the initiator.
Improved Diagnosability Features 3-14
Crash Trace Data
• Diagnostic data is collected by DIAG when an
Oracle process crash is detected
• Data dump allows offline diagnosis for the
cause of process failure
• Data is collected across all Real Application
Cluster instances to obtain a complete view of
diagnosis in the cluster
• All data is saved in a cdmp_timestamp
directory for each crash
Copyright © Oracle Corporation, 2001. All rights reserved.
Crash Trace Data
Whenever an Oracle process crashes, diagnostic data is collected by the DIAG process. Data is
collected from all instances of a Real Application Cluster to ensure that a complete view of the
problem can be reviewed across all instances.
This diagnostic data is saved offline in a directory named according to the time of the dump,
cdmp_timestamp. This directory will be saved under the location identified (implicitly or
explicitly) by the background_dump_destinitialization parameter in the instance
performing the trace.
Improved Diagnosability Features 3-15
Initialization Parameters
• _trace_enabled
• _trace_archive
• _trace_buffers
_trace_buffers
_trace_buffers == "LMD0:100;LMON:75;FGS:50"
"LMD0:100;LMON:75;FGS:50"
Copyright © Oracle Corporation, 2001. All rights reserved.
_trace_enabled
Specifies whether the always-on tracing feature is enabled for the system or not. This is a
Boolean parameter with a default value of TRUE.
_trace_archive
Specifies whether the trace archive mode (logging to file) is on or not. This is a Boolean
parameter with a default value of FALSE.
_trace_buffers
Specifies the number of in-memory trace buffers to be configured for each process in the
system. The syntax of this string parameter is :
_trace_buffers = "proc-spec:size;proc-spec:size;..."
where,
proc-spec = proc | proc, proc-spec
proc = ALL | FGS | BGS | pid | pid - pid | pname
ALL = all the processes
BGS = all background processes
FGS = all foreground processes
pid = oracle process ID
pname = well-known Oracle process names such as LMON, PMON, and so on
size is an integer specifying the number of trace data records that should be allocated for the
process specified by the corresponding proc-spec parameter.
For example:
_trace_buffers = "LMD0:100;LMON:75;FGS:50"
The default value is "ALL:256", corresponding to all processes with 256 trace records.
Improved Diagnosability Features 3-16
Initialization Parameters
• _trace_flush_processes
• _trace_file_size
• _trace_events
• _trace_options
Copyright © Oracle Corporation, 2001. All rights reserved.
_trace_flush_processes
Specifies the processes where flushing is enabled. Their trace buffers are logged periodically
to their respective trace files, by default, when the buffer is half full. The argument for this
parameter, proc-spec, was defined previously and has a default value of "ALL".
_trace_file_size
Specifies the size (in bytes) which the per process trace file can assume on the disk before
wrapping occurs. This parameter takes any positive integer for a value; 65536 is the default.
_trace_events
Specifies the trace events with levels and the processes for which these must be enabled for
trace collection. The syntax is
_trace_events = "event-spec:level:proc-spec"
where
event-spec = event | event, event-spec
event = ALL | event-id | event-id - event-id
event-id = 10000 – 10999
level = 0 – 255. All trace events with a level less than or equal to this number will be logged
in the trace buffer.
proc-spec is as described earlier
The default value is an empty string (" ") indicating that no events are enabled.
_trace_options
Specifies the trace dump file format (binary or text) and whether multiple trace files (per
process) will be generated. The syntax is
_trace_options = "text | binary, single | multiple"
where the first option specifies whether the dump file contains text or binary data, and the
second option determines if there is one trace file generated per process (multiple) or one per
instance (single). The default value is "text,multiple".
Improved Diagnosability Features 3-17
ALTER TRACING Command
ALTER
ALTER TRACING
TRACING OFF;
OFF;
ALTER
ALTER TRACING
TRACING ENABLE
ENABLE "ALL:4:BGS";
"ALL:4:BGS";
ALTER
ALTER TRACING
TRACING ON;
ON;
ALTER
ALTER TRACING
TRACING DISABLE
DISABLE "10000-10500";
"10000-10500";
ALTER
ALTER TRACING
TRACING FLUSH
FLUSH "ALL";
"ALL";
Copyright © Oracle Corporation, 2001. All rights reserved.
ALTER TRACING Command
Use the ALTER TRACING command, specific to the trace facility, to change the tracing
characteristics dynamically for an running instance. The sub-commands include:
ON [proc-spec]: To turn on the tracing facility. If proc-spec is specified, it affects
only those processes. If proc-spec is not specified, tracing is turned on for all
processes in the local instance.
OFF [proc-spec]: To turn off the tracing facility. If proc-spec is specified, it
affects only that process. If proc-spec is not specified, tracing is turned off for all
processes in the local instance.
ENABLE event-string: To enable event tracings specified by event-string.
DISABLE event-spec: To disable event tracings specified by event-spec.
FLUSH proc-spec: To flush the trace buffers for specified process(es) to the disk.
where,
event-string = event-spec : level : proc-spec
and event-spec, level, and proc-spec are as defined earlier.
All trace events with a level less than or equal to this number will be logged in the trace buffer.
By default, when an instance is brought up, tracing facility is enabled and all events with level
0 will be logged. The example shows how you can manage tracing by
1. Turning off tracing facility for all Oracle processes
2. Enabling ALL events at level 4 (data with level 4 or below will be logged) for all
background processes
3. Turning the tracing facility back on to activate the logging set in step 2 (for the events
with level 4 or below from background processes) as well as the default logging of all
events at level 0 for all Oracle processes
4. Tracing for events with id from 10000-10500 are disabled, including level 0 data (so
only event 10501-10999 with level 4 or below from background processes are logged).
5. Flushing all tracing data to files
Improved Diagnosability Features 3-18
Dynamic Views
• X$TRACE contains the following columns
– event INTEGER
– op INTEGER
– time INTEGER
– seq# INTEGER
– sid INTEGER
– pid INTEGER
– data VARCHAR(128)
• X$TRACE_EVENTS
– event INTEGER
– trclevel INTEGER
– status INTEGER
– procs VARCHAR(256)
Copyright © Oracle Corporation, 2001. All rights reserved.
Dynamic Views
Two fixed tables, X$TRACE and X$TRACE_EVENTS were added to Oracle9i to support the
new Real Application Clusters diagnosability features.
X$TRACE
This view shows all the traces collected in the trace buffers till the time of query. It can be
used to view the trace snapshots for a process or opcode or any other combination of trace
attributes. The columns in this view are as follows:
• event— event ID
• op— op code
• time— time at which the event was recorded
• seq#— system-wide unique identifier for this recorded event
• sid— session id of this event
• pid— Oracle process number
• data— related data for this event (implementation related)
X$TRACE_EVENTS
This view lists the currently enabled trace events and their attributes. It has the following
columns:
• event— event ID
• trclevel— tracing level at which this event is enabled
• status— 0 (disable) or 1 (enabled) for this event
• procs— which Oracle process for this event is enabled
Improved Diagnosability Features 3-19
Summary
In this lesson, you should have learned how to:
• Describe the components of the diagnosability
architecture for Oracle9i Real Application
Clusters
• Identify the functions of the DIAG process
• Define in-memory and on-disk diagnosability
data
• Choose tools for diagnosing Oracle9i Real
Application Clusters hangs and crashes
• Set trace controls with initialization parameters
and the ALTER TRACE command
• Use X$ views to observe tracing information
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 3-20
Oracle Cluster Analysis Utility
Improved Diagnosability Features 4-1
Objectives
After this lesson, you should be able to:
• Explain the purpose of the Oracle Cluster
Analysis Utility
• Define the environments where the utility will
run
• Understand the output from the program
• List the limitations of the utility
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 4-2
Features
The Oracle Cluster Analysis Utility
• Analyzes Windows clusters
• Performs tests that ascertain whether a cluster
is able to run Oracle Real Application Clusters
• The tests
– Do not guarantee that Oracle Real
Application Clusters will run
– Provide information about the cluster
components required by Oracle Real
Application Clusters for valid clusters
• The utility runs independently of Oracle9i
Copyright © Oracle Corporation, 2001. All rights reserved.
Features
The Oracle Cluster Analysis Utility is designed for use by Windows system administrators or
database administrators who want to install and run Oracle9i Real Application Clusters
software for the first time. It performs a discovery of all the Windows cluster components
needed to support Real Application Clusters to determine if they are available.
During the analysis of the cluster, the utility will collect other data that can be of value when
planning and designing a database to run on the cluster. This includes information about the
available cluster interconnects and the size and names of any raw partitions (raw partitions are
needed for the database files in a Real Application Clusters database).
The utility will identify any missing components necessary for the support of a Real
Application Clusters database. However, if your analysis reports a properly configured cluster,
you are not guaranteed a successful installation of Real Application Clusters software and
configuration of a database. This is because other factors not analyzed by the Oracle Cluster
Analysis Utility, such as available disk and memory space, are also pertinent.
You can install the Oracle Cluster Analysis Utility independently of any other Oracle9i
software, so you can perform your analysis before running the Oracle Universal Installer to
install and configure your database software.
Improved Diagnosability Features 4-3
Usage Model
• Complete cluster analysis from any single
node in the cluster
• Quick identification of working cluster
• Report any errors encountered
Copyright © Oracle Corporation, 2001. All rights reserved.
Usage Model
The utility can be run from the command line on any of the nodes in a cluster, by running the
clustercheck.exe file from the preinstall area. This executable, in turn, uses the
ocvfile.exe file to collect information from each node in the cluster.
The Oracle Cluster Analysis Utility provides the following:
• Complete cluster analysis from single node in cluster.
• Quick identification of working cluster. The utility analyzes the basic components and
a successful run identifies the cluster as functioning properly.
• If the program encounters an error, the severity and possible fixes are reported.
Improved Diagnosability Features 4-4
Information Provided by the Utility
• Number of disk drives
• Reports bad disk information
• Size and number of available partitions
• Existence of file systems or letter names on
partitions
• Free space available in each partition
• Number, types, and addresses of
interconnects on each node
• Host name and alias for each node
Copyright © Oracle Corporation, 2001. All rights reserved.
Information Provided by the Utility
The utility runs on a cluster which should include network connectivity and shared storage.
The program attempts to use the cluster to run basic tests to ensure that the hardware is
functioning correctly.
If it encounters no problems or errors, the module reports the following information:
• Number of drives available per node
• Information about bad disks encountered
• Number of partitions on each drive
• Whether or not a file system is on each partition
• Whether or not a drive letter is assigned to each partition
• Size of partition
• Free space available on each partition
• Number and types of interconnects available per node
• IP address for all interconnects
• Medium Access Control (MAC) sublayer address for the physical communication
device
• Virtual Interface Architecture (VIA) interconnects
• Host name and aliases of each node
If an error is encountered while gathering the information or testing the hardware, the program
analyzes the error and provides information on possible solutions to fix the error.
Improved Diagnosability Features 4-5
Limitations
• Oracle Cluster Analysis Utility works only with
Windows clusters
• Only reports on storage devices connected to
SCSI or Fiber Channel
• Only reports on TCP- and VIA-based networks
• Does not perform dynamic discovery of cluster
nodes
Copyright © Oracle Corporation, 2001. All rights reserved.
Limitations
The cluster check utility works only on Windows. It generates reports only on storage devices
connected to SCSI or Fiber Channel. Also, it only reports on TCP and VIA based networks.
The nodes in the cluster have to be typed in initially for the utility. The utility cannot
automatically discover the nodes in the cluster.
Improved Diagnosability Features 4-6
Dynamics
• The node where the utility runs acts as the coordinator
node
• The coordinator node starts the Oracle Cluster Verifier
service on all the nodes in the cluster
• This Oracle Cluster Verifier service collects information
related to the storage devices and network
interconnects present on the node
• After populating the information file, the the Oracle
Cluster Verifier service reports to the coordinator node
• When the coordinator node hears back from all the
nodes in the cluster, it can determine if the cluster can
support Oracle Real Application Clusters
• The services and the clustercheck utility report
information in files stored in the opsm subdirectory
under the Temp directory
Copyright © Oracle Corporation, 2001. All rights reserved.
Dynamics
The node from where the utility is run acts as the coordinator node. The coordinator node
starts the Oracle Cluster Verifier service on all the nodes in the cluster (including itself). This
service collects information related to the storage devices and network interconnects present
on the node. The information collected by the Oracle Cluster Verifier service is stored inside
the opsm directory under a Temp directory of the node on which the service is running.
After populating the information file, the the Oracle Cluster Verifier service reports to the
coordinator node whether it was successful or not in collecting the information. When the
coordinator node hears back from all the nodes in the cluster, it decides whether the cluster is
in a state to support Oracle Real Application Clusters and displays its decision.
The services and the clustercheck utility use log files while doing their job. These logs files are
stored in the same location as the information files, which is the opsm subdirectory under
Temp directory.
Improved Diagnosability Features 4-7
Interfaces
• Command line to initiate program
– clustercheck.exe
– Located in pre-install area on the CD
– Loaded into %ORACLE_HOME%\bin\
• Log and information files record results
– Log files show how the utility executed
– Information files, one for each node,
contain cluster analysis data
– The files are stored in a temporary directory
under opsm
• NOTE: The utility runs independently of Oracle
Copyright © Oracle Corporation, 2001. All rights reserved.
Command Line Tools
This program is executable from the command line with the command
clustercheck
The results are stored in log files and information files located in a temp directory under
OPSM.The former show how the utility executed and contain information primarily useful for
developers to debug the tool. One information text file is created on each node in the cluster
and contains the cluster analysis data, for example, OraCluInfo.txt.
Users are prompted for the host name of each node, so they must be aware of the host name of
each node, otherwise the program is self running. Users must have some basic knowledge of
the hardware in order to analyze the results:
• Make up of a cluster
• Networking setup
• Storage device setup
Installation and Configuration
The program is located in the pre-install area on the Oracle9i distribution for Windows. It is
installed in the %ORACLE_HOME%\bin\ directory. The program is self cleaning and requires
no further installation or configuration.
This is a stand-alone program with no dependencies on other components. The utility does not
require Oracle to be installed on the system.
Improved Diagnosability Features 4-8
Sample Output
Machine--------->INTELOPS1
Machine--------->INTELOPS1
IP-------------->144.25.190.128
IP-------------->144.25.190.128
Num
Num ofof Net
Net Crds->2
Crds->2
.. .. ..
Number
Number ofof Drives------>4
Drives------>4
Disk
Disk Number--->0
Number--->0
Bad
Bad Disk------>0
Disk------>0
Drive
Drive Signtr-->254434909
Signtr-->254434909
Total
Total Size------>8183MB
Size------>8183MB
Num
Num Part------>33
Part------>33
Partition
Partition Number---->1
Number---->1
Partition
Partition Letter---->None
Letter---->None
Partition
Partition Format---->6
Format---->6
Total
Total Size------------>274MB
Size------------>274MB
Free
Free Space---------->0Kbytes
Space---------->0Kbytes
Copyright © Oracle Corporation, 2001. All rights reserved.
Buffer length ! including HDR = 3340
Machine--------->INTELOPS1
IP-------------->144.25.190.128
Num of Net Crds->2
Card Name---->Intel 82557-based 10/100 Ethernet PCI
Adapter or compatible
Card IP------>144.25.190.128
NumofAlias--->0
Aliases
. . .
VIA not available on this cluster
Number of Drives------>4
Disk Number--->0
Bad Disk------>0
Drive Signtr-->254434909
Total Size------>8183MB
Num Part------>33
Partition Number---->1
Partition Letter---->None
Partition Format---->6
Total Size------------>274MB
Free Space---------->0Kbytes
Partition Number---->2
. . .
Disk Number--->1
. . .
Improved Diagnosability Features 4-9
Summary
In this lesson, you should have learned how to:
• Explain the purpose of the Oracle Cluster
Analysis Utility
• Define the environments where the utility will
run
• Understand the output from the program
• List the limitations of the utility
Copyright © Oracle Corporation, 2001. All rights reserved.
Improved Diagnosability Features 4-10
Вам также может понравиться
- Physical Standby Database Configuration For User Managed Failover End To End TestДокумент49 страницPhysical Standby Database Configuration For User Managed Failover End To End TestsiyasoonОценок пока нет
- Oracle Dataguard Interview QuestionsДокумент6 страницOracle Dataguard Interview QuestionsPranabKanojiaОценок пока нет
- Oracle HRMS Self Service SetupДокумент6 страницOracle HRMS Self Service SetupDhinakaran DartОценок пока нет
- Oracle Data Guard Interview QuestionsДокумент6 страницOracle Data Guard Interview Questionsdbareddy100% (2)
- Sample Interview Questions For Planning EngineersДокумент16 страницSample Interview Questions For Planning EngineersPooja PawarОценок пока нет
- ADG LabExercise LinuxДокумент41 страницаADG LabExercise LinuxMuneeza HashmiОценок пока нет
- Process Industry Practices Insulation: PIP INEG2000 Guidelines For Use of Insulation PracticesДокумент15 страницProcess Industry Practices Insulation: PIP INEG2000 Guidelines For Use of Insulation PracticesZubair RaoofОценок пока нет
- Using Procedures and PackagesДокумент45 страницUsing Procedures and Packagesapi-3831209Оценок пока нет
- Data Guard 11gДокумент450 страницData Guard 11gXuan Sinh PhamОценок пока нет
- Module 1 - Oracle ArchitectureДокумент34 страницыModule 1 - Oracle ArchitecturePratik Gandhi100% (2)
- Setting Up Oracle 11g Data Guard For SAP CustomersДокумент60 страницSetting Up Oracle 11g Data Guard For SAP CustomersUdit SharmaОценок пока нет
- Chapter 24 - The Solar SystemДокумент36 страницChapter 24 - The Solar SystemHeather Blackwell100% (1)
- Route Clearence TeamДокумент41 страницаRoute Clearence Teamctenar2Оценок пока нет
- Exadata PerformanceДокумент35 страницExadata Performancesdranga123Оценок пока нет
- Oracle SM IДокумент388 страницOracle SM ITanmoy NandyОценок пока нет
- Database Architecture Oracle DbaДокумент41 страницаDatabase Architecture Oracle DbaImran ShaikhОценок пока нет
- Oracle Performance Tuning Basic PDFДокумент50 страницOracle Performance Tuning Basic PDFsharminaОценок пока нет
- 2011-11-09 Diana and AtenaДокумент8 страниц2011-11-09 Diana and AtenareluОценок пока нет
- oRACLE NotesДокумент15 страницoRACLE NotesCarla MissionaОценок пока нет
- PowerFlex 755 Programming With DeviceLogix PDFДокумент39 страницPowerFlex 755 Programming With DeviceLogix PDFf270171Оценок пока нет
- Data GuardДокумент6 страницData GuardJai Narayan SharmaОценок пока нет
- Data GuardДокумент3 страницыData Guardsivakumar_kuttyОценок пока нет
- Active Data Guard 11g DatasheetДокумент2 страницыActive Data Guard 11g DatasheetRaghu ChiranjiviОценок пока нет
- S937 SmithMeeksДокумент55 страницS937 SmithMeeksvenu_dbaОценок пока нет
- Monitoring Windows EventlogsДокумент6 страницMonitoring Windows EventlogsPrince JabaKumarОценок пока нет
- Oracle DBA ArchitectureДокумент17 страницOracle DBA ArchitectureDiwakar Reddy SОценок пока нет
- 11g Active Data Guard More Than Just DR .: Gavin Soorma Senior Oracle DBA, BankwestДокумент30 страниц11g Active Data Guard More Than Just DR .: Gavin Soorma Senior Oracle DBA, BankwestAbhinay IrukullaОценок пока нет
- Oracle Data Guard 11g Release 2 With Oracle Enterprise Manager 11g Grid ControlДокумент64 страницыOracle Data Guard 11g Release 2 With Oracle Enterprise Manager 11g Grid ControlKashif HussainОценок пока нет
- Managing The Oracle InstanceДокумент28 страницManaging The Oracle Instancesherif hassan younisОценок пока нет
- Dataguard QuestionsДокумент5 страницDataguard QuestionssuhaasОценок пока нет
- Technical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureДокумент35 страницTechnical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureHuynh Sy NguyenОценок пока нет
- Maximum Availability Architecture: Oracle Best Practices For High AvailabilityДокумент17 страницMaximum Availability Architecture: Oracle Best Practices For High AvailabilityVineet MehtaОценок пока нет
- Test That The Standby Database Is in Sync?Документ6 страницTest That The Standby Database Is in Sync?Surender MarthaОценок пока нет
- Oracle Performance Diagnostic Guide (Version 3.20) Hang/LockingДокумент51 страницаOracle Performance Diagnostic Guide (Version 3.20) Hang/LockingdmdunlapОценок пока нет
- Oracle 10g Admin Workshops PPTLess 18Документ23 страницыOracle 10g Admin Workshops PPTLess 18mahirouxОценок пока нет
- D17316GC21 Les09 9Документ46 страницD17316GC21 Les09 9johnrambo4Оценок пока нет
- Maa WP DR DBM 130065Документ27 страницMaa WP DR DBM 130065Hot MaleОценок пока нет
- Os Us en WP SnapshotДокумент20 страницOs Us en WP SnapshotpandsinОценок пока нет
- Oracle University Oracle Database 11g: Administration Workshop IДокумент10 страницOracle University Oracle Database 11g: Administration Workshop IperhackerОценок пока нет
- Dataguard P LДокумент6 страницDataguard P LAhmed HussainОценок пока нет
- Managing An Oracle InstanceДокумент30 страницManaging An Oracle InstanceAbid AliОценок пока нет
- Module 1 - Oracle Architecture: ObjectivesДокумент41 страницаModule 1 - Oracle Architecture: ObjectivesNavneet SainiОценок пока нет
- Oracle-9: Unit - 9 (A) One Mark QuestionsДокумент12 страницOracle-9: Unit - 9 (A) One Mark QuestionsJonty BabaОценок пока нет
- Process: Course: COMP6153 Effective Period: September 2018Документ27 страницProcess: Course: COMP6153 Effective Period: September 2018Dicky AngkasaОценок пока нет
- ADG Technical PaperДокумент23 страницыADG Technical PaperHarish NaikОценок пока нет
- Memory Management PARTITIONED ALLOCATIONДокумент7 страницMemory Management PARTITIONED ALLOCATIONG.LAKSHIMIPRIYA Dept Of Computer ScienceОценок пока нет
- Active Data Guard and Oracle Golden GateДокумент3 страницыActive Data Guard and Oracle Golden GateMahendranath ReddyОценок пока нет
- Accelerate Database Efficiency With SQL Performance Investigator Pi Technical Brief 26681Документ6 страницAccelerate Database Efficiency With SQL Performance Investigator Pi Technical Brief 26681LoruhОценок пока нет
- Backup Recovery ConceptsДокумент26 страницBackup Recovery Conceptsapi-3722405Оценок пока нет
- 9i Database TriggersДокумент25 страниц9i Database Triggersvinaydixit2Оценок пока нет
- 3 Oracle Architecture NotesДокумент39 страниц3 Oracle Architecture NotesPaul NikolaidisОценок пока нет
- 9i RAC: Cloning To A Single Instance: Shankar GovindanДокумент12 страниц9i RAC: Cloning To A Single Instance: Shankar GovindanPedro Tablas SanchezОценок пока нет
- Ohio11 Grid Kramer PresentДокумент422 страницыOhio11 Grid Kramer PresentkruemeL1969Оценок пока нет
- Maximum Availability Architecture: Oracle Best Practices For High AvailabilityДокумент32 страницыMaximum Availability Architecture: Oracle Best Practices For High AvailabilityAngel Freire RamirezОценок пока нет
- T305-05 Backup Nodes - RevEДокумент12 страницT305-05 Backup Nodes - RevEMurilloSilvaSilveiraОценок пока нет
- UntitledДокумент13 страницUntitledNemat SahebОценок пока нет
- Oracle 11g - Taking High Availability To The Next Level: Gavin Soorma Senior Oracle DBA, HBOS AustraliaДокумент47 страницOracle 11g - Taking High Availability To The Next Level: Gavin Soorma Senior Oracle DBA, HBOS AustraliaVenkatesh GuntiОценок пока нет
- Pre SalesДокумент4 страницыPre Sales김진태Оценок пока нет
- OratopДокумент17 страницOratopWahab AbdulОценок пока нет
- Flash Recovery AreaДокумент2 страницыFlash Recovery Areasatish.lodamОценок пока нет
- Data Loss Faq TP 638 1 1206 GBДокумент3 страницыData Loss Faq TP 638 1 1206 GBOuss OrbitОценок пока нет
- UpgasstДокумент20 страницUpgasstapi-3831209Оценок пока нет
- AIM HandbookДокумент356 страницAIM Handbookmohamed_spОценок пока нет
- R11i DocДокумент6 страницR11i Docapi-3831209Оценок пока нет
- Oracle SQL Plus - User Guide and ReferenceДокумент394 страницыOracle SQL Plus - User Guide and Referenceimdfuture9999100% (5)
- PLSQL ChapterДокумент26 страницPLSQL Chapterapi-3831209Оценок пока нет
- PL SQL User's Guide & Reference 8.1.5Документ590 страницPL SQL User's Guide & Reference 8.1.5api-25930603Оценок пока нет
- Dynamic SQLДокумент15 страницDynamic SQLapi-3831209Оценок пока нет
- Oracle Database TipsДокумент97 страницOracle Database Tipsapi-3831209Оценок пока нет
- What Is A Package?Документ45 страницWhat Is A Package?api-3831209Оценок пока нет
- DependenciesДокумент16 страницDependenciesapi-3831209Оценок пока нет
- Procedure BuilderДокумент17 страницProcedure Builderapi-3831209Оценок пока нет
- Supplied PackageДокумент10 страницSupplied Packageapi-3831209Оценок пока нет
- PROCEDURE Name ( (Parameter (, Parameter, ... ) ) ) IS (Local Declarations) Begin Executable Statements (Exception Exception Handlers) END (Name)Документ34 страницыPROCEDURE Name ( (Parameter (, Parameter, ... ) ) ) IS (Local Declarations) Begin Executable Statements (Exception Exception Handlers) END (Name)api-3831209100% (1)
- 9ib TEXTДокумент41 страница9ib TEXTapi-3831209Оценок пока нет
- 9ib WSPCДокумент44 страницы9ib WSPCapi-3831209Оценок пока нет
- 9ib WINДокумент135 страниц9ib WINapi-3831209Оценок пока нет
- Database Triggers: You May Fire When You Are Ready, GridleyДокумент43 страницыDatabase Triggers: You May Fire When You Are Ready, GridleyranusofiОценок пока нет
- 9ib SCALEДокумент66 страниц9ib SCALEapi-3831209Оценок пока нет
- 9ib XMLДокумент51 страница9ib XMLapi-3831209100% (1)
- 9ib JAVAДокумент62 страницы9ib JAVAapi-3831209Оценок пока нет
- 9ib REPLДокумент72 страницы9ib REPLapi-3831209Оценок пока нет
- 9ib IPLUSДокумент16 страниц9ib IPLUSapi-3831209Оценок пока нет
- Installation and ConfigurationДокумент104 страницыInstallation and Configurationapi-3831209Оценок пока нет
- 9ib OBJДокумент96 страниц9ib OBJapi-3831209Оценок пока нет
- 9ib ISRCHДокумент71 страница9ib ISRCHapi-3831209Оценок пока нет
- 9ib SECДокумент56 страниц9ib SECapi-3831209Оценок пока нет
- 9ib MANAGДокумент168 страниц9ib MANAGapi-3831209Оценок пока нет
- 9ib HADRДокумент179 страниц9ib HADRapi-3831209Оценок пока нет
- List of Olympic MascotsДокумент10 страницList of Olympic MascotsmukmukkumОценок пока нет
- Epistemology and OntologyДокумент6 страницEpistemology and OntologyPriyankaОценок пока нет
- ProspДокумент146 страницProspRajdeep BharatiОценок пока нет
- Pontevedra 1 Ok Action PlanДокумент5 страницPontevedra 1 Ok Action PlanGemma Carnecer Mongcal50% (2)
- KiSoft Sort & Pack Work Station (User Manual)Документ41 страницаKiSoft Sort & Pack Work Station (User Manual)Matthew RookeОценок пока нет
- PR Earth Users Guide EMILY1Документ2 страницыPR Earth Users Guide EMILY1Azim AbdoolОценок пока нет
- Jones Et - Al.1994Документ6 страницJones Et - Al.1994Sukanya MajumderОценок пока нет
- Waswere Going To Waswere Supposed ToДокумент2 страницыWaswere Going To Waswere Supposed ToMilena MilacicОценок пока нет
- Cpar ReviewerДокумент6 страницCpar ReviewerHana YeppeodaОценок пока нет
- Personal Narrative RevisedДокумент3 страницыPersonal Narrative Revisedapi-549224109Оценок пока нет
- Strategic Capital Management: Group - 4 Jahnvi Jethanandini Shreyasi Halder Siddhartha Bayye Sweta SarojДокумент5 страницStrategic Capital Management: Group - 4 Jahnvi Jethanandini Shreyasi Halder Siddhartha Bayye Sweta SarojSwetaSarojОценок пока нет
- Bathinda - Wikipedia, The Free EncyclopediaДокумент4 страницыBathinda - Wikipedia, The Free EncyclopediaBhuwan GargОценок пока нет
- Nikasil e AlusilДокумент5 страницNikasil e AlusilIo AncoraioОценок пока нет
- Durability of Prestressed Concrete StructuresДокумент12 страницDurability of Prestressed Concrete StructuresMadura JobsОценок пока нет
- Sickle Cell DiseaseДокумент10 страницSickle Cell DiseaseBrooke2014Оценок пока нет
- Paper II - Guidelines On The Use of DuctlessДокумент51 страницаPaper II - Guidelines On The Use of DuctlessMohd Khairul Md DinОценок пока нет
- April 2021 BDA Case Study - GroupДокумент4 страницыApril 2021 BDA Case Study - GroupTinashe Chirume1Оценок пока нет
- Remedy MidTier Guide 7-5Документ170 страницRemedy MidTier Guide 7-5martin_wiedmeyerОценок пока нет
- Key Performance Indicators - KPIsДокумент6 страницKey Performance Indicators - KPIsRamesh Kumar ManickamОценок пока нет
- Bulletin PDFДокумент2 страницыBulletin PDFEric LitkeОценок пока нет
- Community Resource MobilizationДокумент17 страницCommunity Resource Mobilizationerikka june forosueloОценок пока нет
- Property House Invests $1b in UAE Realty - TBW May 25 - Corporate FocusДокумент1 страницаProperty House Invests $1b in UAE Realty - TBW May 25 - Corporate FocusjiminabottleОценок пока нет
- Rin Case StudyДокумент4 страницыRin Case StudyReha Nayyar100% (1)
- Nyamango Site Meeting 9 ReportДокумент18 страницNyamango Site Meeting 9 ReportMbayo David GodfreyОценок пока нет
- Evolis SDK Use Latest IomemДокумент10 страницEvolis SDK Use Latest IomempatrickОценок пока нет