Вам также может понравиться
- Guía para comentario de texto históricoДокумент1 страницаGuía para comentario de texto históricodilecafaОценок пока нет
- 2011Документ46 страниц2011Alberto Diaz Paste100% (1)
- jmhv5 PDFДокумент11 страницjmhv5 PDFAlex Pablo Holguin CutipaОценок пока нет
- Primeras Paginas Teatro Obra ReunidaДокумент18 страницPrimeras Paginas Teatro Obra ReunidaAlex Pablo Holguin CutipaОценок пока нет
- AnexoA AWTДокумент50 страницAnexoA AWTGutierrez Rurush EstherОценок пока нет
- IntroDesarrolloAplEmpresariales PDFДокумент46 страницIntroDesarrolloAplEmpresariales PDFAlex Pablo Holguin CutipaОценок пока нет
- Oracle Database 11g On Windows Dev Deploy TWP (Cast) 1Документ24 страницыOracle Database 11g On Windows Dev Deploy TWP (Cast) 1Nataniel Marcial ChavezОценок пока нет
- 06 PatronesДокумент82 страницы06 PatronesFrancisca ChirinosОценок пока нет
- Uml JAVA PDFДокумент26 страницUml JAVA PDFovniamcОценок пока нет
- Ffundacionluz Proyecto-EducativoДокумент46 страницFfundacionluz Proyecto-EducativoAlex Pablo Holguin CutipaОценок пока нет
- FamiliaДокумент4 страницыFamiliaAlex Pablo Holguin CutipaОценок пока нет
- Java SE - Interfaces - EscuchasДокумент11 страницJava SE - Interfaces - EscuchasAlex Pablo Holguin CutipaОценок пока нет
- El Sistema de Gestión Por Procesos de La Formación Profesional 1.-Sistema de Gestión Por ProcesosДокумент42 страницыEl Sistema de Gestión Por Procesos de La Formación Profesional 1.-Sistema de Gestión Por ProcesosAlex Pablo Holguin CutipaОценок пока нет
- Informe de gestión 2008-2011 Empresa de Servicios Públicos SopoДокумент433 страницыInforme de gestión 2008-2011 Empresa de Servicios Públicos SopoAlex Pablo Holguin Cutipa100% (1)
- NetBeans 6.9.1 - ManualForWindowsДокумент16 страницNetBeans 6.9.1 - ManualForWindowsJesus Kevin LojeОценок пока нет
- Historia Del Peru Segun San Marcos PDFДокумент2 страницыHistoria Del Peru Segun San Marcos PDFAlan Vladimir Rivas CárdenasОценок пока нет
- NoticiaДокумент4 страницыNoticiaAlex Pablo Holguin CutipaОценок пока нет
- Metodologia Mesova para Objetos de AprendizajeДокумент25 страницMetodologia Mesova para Objetos de AprendizajeHéctor PensoОценок пока нет
- 03-00 Procedimiento #003 - Toma de Inventario ExistenciasДокумент15 страниц03-00 Procedimiento #003 - Toma de Inventario ExistenciasReno N. Chévez Chvez100% (1)
- Diseño de SoftwareДокумент10 страницDiseño de SoftwareAbel SebastiánОценок пока нет
- El Sistema de Gestión Por Procesos de La Formación Profesional 1.-Sistema de Gestión Por ProcesosДокумент42 страницыEl Sistema de Gestión Por Procesos de La Formación Profesional 1.-Sistema de Gestión Por ProcesosAlex Pablo Holguin CutipaОценок пока нет
- PeruДокумент88 страницPeruAlex Pablo Holguin Cutipa100% (1)
- Ensayo Cookies + RemarketingДокумент8 страницEnsayo Cookies + RemarketingDaniel RosalesОценок пока нет
- WebcamvisualДокумент14 страницWebcamvisualRolando NinaОценок пока нет
- Alicante, 10 Argelinos Detenidos Por Violar en Grupo A 3 ChicasДокумент5 страницAlicante, 10 Argelinos Detenidos Por Violar en Grupo A 3 ChicasRolando Pinado JimenezОценок пока нет
- Kunmap Guia Pracitca 4 Pasos para Crear Una Estrategia de Data MarketingДокумент16 страницKunmap Guia Pracitca 4 Pasos para Crear Una Estrategia de Data MarketingLarisa Lopez BarredoОценок пока нет
- Reemplazo de Oscilador Fuente TV Led - Taller de ElectrónicaДокумент5 страницReemplazo de Oscilador Fuente TV Led - Taller de ElectrónicaGeovanny SanJuanОценок пока нет
- Obtener valores clasificación SAPДокумент10 страницObtener valores clasificación SAPGlender AlbertoОценок пока нет
- Manual Tickeadora TM-U220 - BD Service Manual RevBДокумент16 страницManual Tickeadora TM-U220 - BD Service Manual RevBsamancoОценок пока нет
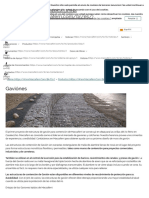
- Gaviónes - Maccaferri América LatinaДокумент3 страницыGaviónes - Maccaferri América LatinayuihОценок пока нет
- Establecer La Ubicación de Red Como Privada o Pública en Windows 10 - Tutoriales PDFДокумент21 страницаEstablecer La Ubicación de Red Como Privada o Pública en Windows 10 - Tutoriales PDFjoseto_441Оценок пока нет
- PHPДокумент187 страницPHPalejandro100% (1)
- Adrian Birdea Tax Declarations Fuente Dom - March Bank - Caixabank - Trason Act Criminal Charges - SignedДокумент79 страницAdrian Birdea Tax Declarations Fuente Dom - March Bank - Caixabank - Trason Act Criminal Charges - SignedAdrian BirdeaОценок пока нет
- Sistema de GestionДокумент1 страницаSistema de GestionNicolas SanchezОценок пока нет
- ¿Qué Es Una - Vernissage - Protocolo & EtiquetaДокумент11 страниц¿Qué Es Una - Vernissage - Protocolo & EtiquetaNoel RamirezОценок пока нет
- Eje 4 PtogramacionДокумент22 страницыEje 4 Ptogramacionorlando zambranoОценок пока нет
- TyC Generales Wplay PDFДокумент113 страницTyC Generales Wplay PDFYeisson Aguirre ReyesОценок пока нет
- Biografía de Antonio Alcalá Galiano - Antonio Alcalá GalianoДокумент5 страницBiografía de Antonio Alcalá Galiano - Antonio Alcalá GalianoJuanm JmmОценок пока нет
- Inscripcion de SeminarioДокумент2 страницыInscripcion de SeminarioNorely Vinces SánchezОценок пока нет
- Paso A Paso Manual de Gestión de CalidadДокумент11 страницPaso A Paso Manual de Gestión de CalidadCamilo Andres Castellanos RodriguezОценок пока нет
- Cerrar Sesión de Usuarios de Active Directory RemotamenteДокумент14 страницCerrar Sesión de Usuarios de Active Directory RemotamenteHector VasquezОценок пока нет
- Electronite: Únete A Millones de Otros Estudiantes y Comienza Tu InvestigaciónДокумент1 страницаElectronite: Únete A Millones de Otros Estudiantes y Comienza Tu InvestigaciónToni BenalmadenaОценок пока нет
- Normas ICONTEC para Trabajos Escritos - Guía COMPLETA (2019)Документ14 страницNormas ICONTEC para Trabajos Escritos - Guía COMPLETA (2019)Yuli RomeroОценок пока нет
- ¿Cuando Una Mountain Bike Es Demasiado Pesada - Trail 14kgДокумент4 страницы¿Cuando Una Mountain Bike Es Demasiado Pesada - Trail 14kgdaniel2rialОценок пока нет
- Caso Web Analytics at Quality Alloys - EsДокумент18 страницCaso Web Analytics at Quality Alloys - EsNancy Contreras100% (2)
- Memoria DescriptivaДокумент2 страницыMemoria DescriptivaAll Kopier Tecnico VeintiseisОценок пока нет
- Configuracion de Prom Terminal de UbuntuДокумент11 страницConfiguracion de Prom Terminal de UbuntuWilliam SanchezОценок пока нет
- AlibabaДокумент109 страницAlibabaronny belОценок пока нет
- El Código de La Manifestación - 12 Poderes ESPIRITUALIDAD Y VIDA INTERIOR - Amazon - Es - SAMSÓ QUERALTÓ, RAIMON - LibrosДокумент7 страницEl Código de La Manifestación - 12 Poderes ESPIRITUALIDAD Y VIDA INTERIOR - Amazon - Es - SAMSÓ QUERALTÓ, RAIMON - LibrosjuasnajnnsОценок пока нет
- OrdenAdmisionEquipoPesadoДокумент3 страницыOrdenAdmisionEquipoPesadoQuintero Osuna Elvia JosefinaОценок пока нет
- Facebook Lanza Sus Mapas de Densidad Poblacional en LATAM PDFДокумент6 страницFacebook Lanza Sus Mapas de Densidad Poblacional en LATAM PDFDiego Gómez MartinoОценок пока нет
- Tirada Cartas Españolas GratisДокумент10 страницTirada Cartas Españolas GratisMarixel OrtizОценок пока нет