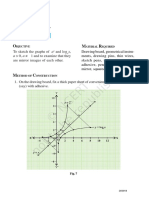
Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- 2.0 - Mathematical Language and Symbols - Including SetsДокумент40 страниц2.0 - Mathematical Language and Symbols - Including SetsKATHERINE JAYME79% (14)
- Comp6651 Final Fall 2020Документ6 страницComp6651 Final Fall 2020Gopal EricОценок пока нет
- De First OrderДокумент86 страницDe First OrderRina Dwi YaniОценок пока нет
- Interior PointДокумент213 страницInterior PointAnonymous XKlkx7cr2IОценок пока нет
- Graph of Log X and A XДокумент3 страницыGraph of Log X and A XVivek SahОценок пока нет
- DPP Math PDFДокумент48 страницDPP Math PDFanurag vОценок пока нет
- Generalized Signed-Digit Number Systems Unifying Framework For Redundant Number RepresentationsДокумент10 страницGeneralized Signed-Digit Number Systems Unifying Framework For Redundant Number Representationsfeezy11Оценок пока нет
- Electromagnetic Signals: Engr. Mark Jefferson A. Arellano, Ect, VCP, RtaДокумент52 страницыElectromagnetic Signals: Engr. Mark Jefferson A. Arellano, Ect, VCP, RtaMark ArrelanoОценок пока нет
- Number SystemsДокумент12 страницNumber SystemsJyoti SukhijaОценок пока нет
- Specialist12 2ed Ch12Документ47 страницSpecialist12 2ed Ch12ZeinabОценок пока нет
- DM - 6 Euclidean AlgorithmДокумент4 страницыDM - 6 Euclidean AlgorithmArvin Anthony Sabido AranetaОценок пока нет
- National Open University of Nigeria: School of Science and TechnologyДокумент204 страницыNational Open University of Nigeria: School of Science and TechnologyApeh Anthony AkorОценок пока нет
- CBSE Class 6 Mathematics Decimals WorksheetДокумент2 страницыCBSE Class 6 Mathematics Decimals Worksheetsoumya09Оценок пока нет
- SAMPLE Examination in Teaching Mathematics in The Primary GradesДокумент3 страницыSAMPLE Examination in Teaching Mathematics in The Primary GradesWindel Q. BojosОценок пока нет
- (Say X, Y, Z) and Values May Be From Interval (1,100) The Program Output May Have One of The Following: - (Not A Quadratic Equations, Real Roots, Imaginary Roots, Equal Roots) Perform BVAДокумент3 страницы(Say X, Y, Z) and Values May Be From Interval (1,100) The Program Output May Have One of The Following: - (Not A Quadratic Equations, Real Roots, Imaginary Roots, Equal Roots) Perform BVAsourabh_sanwalrajputОценок пока нет
- Grade 8 MATH 4th GradingДокумент3 страницыGrade 8 MATH 4th Gradingrenz100% (1)
- Cse M1Документ4 страницыCse M1GPNОценок пока нет
- Discrete NotesДокумент32 страницыDiscrete Notesjake100% (1)
- Lecture Notes of MAT203Документ101 страницаLecture Notes of MAT203siddharthОценок пока нет
- Mycbseguide: Class 12 - Mathematics Term-2 Sample Paper - 01 Marks: 40 Time Allowed: 2 Hours InstructionsДокумент10 страницMycbseguide: Class 12 - Mathematics Term-2 Sample Paper - 01 Marks: 40 Time Allowed: 2 Hours Instructionsdhruv jainОценок пока нет
- Unit 8 AnswersДокумент8 страницUnit 8 Answerspyropop3Оценок пока нет
- Solving Initial Value Problem Using Runge-Kutta 6 TH Order MethodДокумент10 страницSolving Initial Value Problem Using Runge-Kutta 6 TH Order Methodhusmech80_339926141Оценок пока нет
- Revision Inverse Trigonometric FunctionsДокумент85 страницRevision Inverse Trigonometric Functionslekhi spamОценок пока нет
- Distance and DisplacementДокумент31 страницаDistance and DisplacementChristine D. BaliloОценок пока нет
- Ordinary Differential Equations I Lecture (3) First Order Differential EquationsДокумент8 страницOrdinary Differential Equations I Lecture (3) First Order Differential EquationsWisal muhammedОценок пока нет
- 10 C1 Specimen PaperДокумент57 страниц10 C1 Specimen PaperMohammed Jawad AyubОценок пока нет
- Unit 2 PDFДокумент19 страницUnit 2 PDFSampath KumarОценок пока нет
- CwaltonДокумент11 страницCwaltonapi-270305905Оценок пока нет
- Assignment 1Документ2 страницыAssignment 1Vibhanshu PrajapatiОценок пока нет
- Best Book For Quantitative Aptitude Practice Book For All Type of Government and Entrance Exam (Bank, SSC, Defense, Management (CAT, XAT GMAT), Railway, Police, Civil Services) in EnglishДокумент46 страницBest Book For Quantitative Aptitude Practice Book For All Type of Government and Entrance Exam (Bank, SSC, Defense, Management (CAT, XAT GMAT), Railway, Police, Civil Services) in EnglishexamcartОценок пока нет