Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
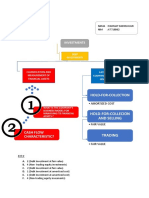
- Accounting and Bookkeeping SOPДокумент22 страницыAccounting and Bookkeeping SOPJessa Mae Cac100% (2)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- NCND TemplateДокумент3 страницыNCND Templateanne vilОценок пока нет
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Beams11 ppt04Документ49 страницBeams11 ppt04Rika RieksОценок пока нет
- The Challenges of Managing Institutional Properties.Документ49 страницThe Challenges of Managing Institutional Properties.Kingsley M100% (3)
- 363 889 1 PBДокумент19 страниц363 889 1 PBPrama AjiОценок пока нет
- Jawaban Debt Investments (Mindmap, E17-1 p17-1)Документ2 страницыJawaban Debt Investments (Mindmap, E17-1 p17-1)Rahmat DarmawanОценок пока нет
- Mafin QuizДокумент2 страницыMafin QuizNesgie MiclatОценок пока нет
- Why Are Ratios UsefulДокумент11 страницWhy Are Ratios UsefulKriza Sevilla Matro100% (3)
- CH 13 Working Capital OverviewДокумент12 страницCH 13 Working Capital OverviewIlyas SadvokassovОценок пока нет
- Zimbabwe School Examinations Council: Management of Business 9198/2Документ4 страницыZimbabwe School Examinations Council: Management of Business 9198/2brenda chinduruОценок пока нет
- Metrics Transformation in Telecommunications EF0117Документ20 страницMetrics Transformation in Telecommunications EF0117shru294Оценок пока нет
- Emerging Issues in Audit. Term PaperДокумент23 страницыEmerging Issues in Audit. Term PaperAneeka Niaz100% (2)
- GANN Curtis Arnold'Документ5 страницGANN Curtis Arnold'analyst_anil14Оценок пока нет
- ALR Calculator IIДокумент39 страницALR Calculator IIlucnesОценок пока нет
- Abn Amro Bank NV 1m Equity Certificates Linked To The Satyam Computer Services LTD - Supplement Series No33Документ62 страницыAbn Amro Bank NV 1m Equity Certificates Linked To The Satyam Computer Services LTD - Supplement Series No33Anthony BradyОценок пока нет
- Real Estate in GurgaonДокумент50 страницReal Estate in GurgaonShashank Garg0% (1)
- Concepts of Value and ReturnДокумент28 страницConcepts of Value and ReturnDolly Garg0% (1)
- Economics of Edu. - MarathiДокумент152 страницыEconomics of Edu. - MarathisagarОценок пока нет
- Physicists Graduate From Wall Street: News by Jennifer OuelletteДокумент4 страницыPhysicists Graduate From Wall Street: News by Jennifer OuelletteWong Kai WenОценок пока нет
- Competition Act 2002Документ53 страницыCompetition Act 2002Ca Prashanth DurgamОценок пока нет
- 2017 09 26 - Southey Capital Bond Illiquid and DistressedДокумент2 страницы2017 09 26 - Southey Capital Bond Illiquid and DistressedSouthey CapitalОценок пока нет
- Memo-Product Life CycleДокумент3 страницыMemo-Product Life CyclePrakash RanjanОценок пока нет
- On Ratio Analysis Vita Milk (3) 1Документ54 страницыOn Ratio Analysis Vita Milk (3) 1Sanchit SharmaОценок пока нет
- Annual Financial Statements and Management Report Deutsche Bank AG 2015Документ178 страницAnnual Financial Statements and Management Report Deutsche Bank AG 2015hieu le100% (1)
- Tongo RulesДокумент6 страницTongo RulesperpetualdreamerОценок пока нет
- Study Material Inventory-1Документ9 страницStudy Material Inventory-1lipak chinaraОценок пока нет
- ALKALOID ANNUAL2013 Web PDFДокумент157 страницALKALOID ANNUAL2013 Web PDFAleksandar ParamatmanОценок пока нет
- F3.ffa Examreport d14Документ4 страницыF3.ffa Examreport d14Kian TuckОценок пока нет
- Balanced ScorecardДокумент110 страницBalanced ScorecardCarl Johnson100% (2)
- Cost of Capital QuizДокумент3 страницыCost of Capital Quizrks88srk50% (2)