Вам также может понравиться
- Theatre Guide Live 2014 DigitalДокумент24 страницыTheatre Guide Live 2014 DigitalArtist RecordingОценок пока нет
- Consoles Guide 2015Документ28 страницConsoles Guide 2015Artist RecordingОценок пока нет
- Microphone Guide 2012Документ32 страницыMicrophone Guide 2012Artist RecordingОценок пока нет
- IZotope Mixing Guide Principles Tips TechniquesДокумент70 страницIZotope Mixing Guide Principles Tips TechniquesRobinson Andress100% (1)
- Waves StoryДокумент4 страницыWaves StoryArtist RecordingОценок пока нет
- Consoles 2014Документ44 страницыConsoles 2014Artist Recording100% (1)
- Music Salary Guide PDFДокумент24 страницыMusic Salary Guide PDFSusan JonesОценок пока нет
- The Mastering ProcessДокумент1 страницаThe Mastering ProcessArtist RecordingОценок пока нет
- Noise ReductionДокумент112 страницNoise ReductionnosoyninjaОценок пока нет
- 37 Recording TipsДокумент3 страницы37 Recording TipsIrwin B. GalinoОценок пока нет
- Console Guide 2013Документ52 страницыConsole Guide 2013Artist Recording100% (1)
- Home Studio Series Vol4Документ8 страницHome Studio Series Vol4Artist Recording100% (3)
- Izotope Mastering Guide-Mastering With Ozone PDFДокумент81 страницаIzotope Mastering Guide-Mastering With Ozone PDFOscar Pacheco100% (1)
- Refining The Details in Your Audio ProductionДокумент4 страницыRefining The Details in Your Audio ProductionArtist RecordingОценок пока нет
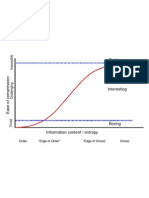
- Boring: Order "Edge of Order" "Edge of Chaos" ChaosДокумент1 страницаBoring: Order "Edge of Order" "Edge of Chaos" ChaosArtist RecordingОценок пока нет
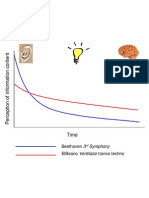
- Beethoven 3 Elbeano Ventilator Trance Techno: SymphonyДокумент1 страницаBeethoven 3 Elbeano Ventilator Trance Techno: SymphonyArtist RecordingОценок пока нет
- Rane Audio ReferenceДокумент437 страницRane Audio ReferenceArtist RecordingОценок пока нет
- The Art of Equalization For Custom Home TheatersДокумент3 страницыThe Art of Equalization For Custom Home TheatersArtist RecordingОценок пока нет
- Drum Tuning Advice For Recording and GigsДокумент7 страницDrum Tuning Advice For Recording and GigsArtist RecordingОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Practical-8: Write A Mobile Application That Creates Alarm ClockДокумент7 страницPractical-8: Write A Mobile Application That Creates Alarm Clockjhyter54rdОценок пока нет
- Official Tournament 5v5 Special MarksmanДокумент16 страницOfficial Tournament 5v5 Special Marksmanmamad nentoОценок пока нет
- Bus Pass Management SystemДокумент71 страницаBus Pass Management SystemAngamuthuОценок пока нет
- Opamp ProjectДокумент10 страницOpamp Projectbirla_sОценок пока нет
- A New Method For Encryption Using Fuzzy Set TheoryДокумент7 страницA New Method For Encryption Using Fuzzy Set TheoryAgus S'toОценок пока нет
- HTTPS: - WWW - Whois.com - Whois - Tech-Al - InfoДокумент4 страницыHTTPS: - WWW - Whois.com - Whois - Tech-Al - InfoΛουκάςОценок пока нет
- Can Internal Excellence Be Measured - DeshpandeДокумент11 страницCan Internal Excellence Be Measured - DeshpandeFelipeОценок пока нет
- Active Versus Passive DevicesДокумент6 страницActive Versus Passive DevicesSneha BandhaviОценок пока нет
- Temario Spring MicroserviciosДокумент5 страницTemario Spring MicroserviciosgcarreongОценок пока нет
- Full Multisim 14 PDFДокумент365 страницFull Multisim 14 PDFHafiz PGОценок пока нет
- Imrt VmatДокумент29 страницImrt VmatandreaОценок пока нет
- Instep BrochureДокумент8 страницInstep Brochuretariqaftab100% (4)
- ROZEE CV 219 Adnan KhanДокумент4 страницыROZEE CV 219 Adnan KhanMaria JavedОценок пока нет
- HeliTrim Manual en PDFДокумент9 страницHeliTrim Manual en PDFJuan Pablo100% (1)
- IGV AssamblyДокумент31 страницаIGV AssamblyPhong le100% (1)
- DigikeyДокумент9 страницDigikeyEfra IbacetaОценок пока нет
- Euler's Method and Logistic Growth Solutions (BC Only) SolutionsДокумент4 страницыEuler's Method and Logistic Growth Solutions (BC Only) SolutionsdeltabluerazeОценок пока нет
- Hipaa 091206Документ18 страницHipaa 091206Dishi BhavnaniОценок пока нет
- FДокумент38 страницFyuniar asmariniОценок пока нет
- Wireless Local Loop: A Seminar Report OnДокумент12 страницWireless Local Loop: A Seminar Report OnYesh DamaniaОценок пока нет
- List ObjectДокумент60 страницList ObjectCRA Esuela Claudio ArrauОценок пока нет
- Flitedeck Pro X: Release NotesДокумент28 страницFlitedeck Pro X: Release NotesŁukasz BarzykОценок пока нет
- Pandapower PDFДокумент167 страницPandapower PDFAlen TatalovićОценок пока нет
- PNP Switching Transistor: FeatureДокумент2 страницыPNP Switching Transistor: FeatureismailinesОценок пока нет
- VACON NX SERVICE MANUAL Appendix FI10 PDFДокумент71 страницаVACON NX SERVICE MANUAL Appendix FI10 PDFStanislav Suganuaki0% (2)
- Dresner Data Preparation Market Study 2021Документ101 страницаDresner Data Preparation Market Study 2021Carlos Alonso FernandezОценок пока нет
- ProfiNet - IO User GuideДокумент36 страницProfiNet - IO User GuidePlacoОценок пока нет
- Lathi Ls SM Chapter 2Документ33 страницыLathi Ls SM Chapter 2Dr Satyabrata JitОценок пока нет
- Idoc Error Handling For Everyone: How It WorksДокумент2 страницыIdoc Error Handling For Everyone: How It WorksSudheer KumarОценок пока нет
- Manual Elisys DuoДокумент322 страницыManual Elisys DuoLeydi Johana Guerra SuazaОценок пока нет