Вам также может понравиться
- Fpga Implementation of Memory Controller FSM Using Simulink2Документ57 страницFpga Implementation of Memory Controller FSM Using Simulink2AKОценок пока нет
- Design Verification Engineer RTL in Austin TX Resume Sumaira KhowajaДокумент3 страницыDesign Verification Engineer RTL in Austin TX Resume Sumaira KhowajaSumairaKhowaja4Оценок пока нет
- Computer Architecture 3rd Edition by Moris Mano CH 08Документ43 страницыComputer Architecture 3rd Edition by Moris Mano CH 08Sadaf RasheedОценок пока нет
- Application-Specific Integrated Circuit ASIC A Complete GuideОт EverandApplication-Specific Integrated Circuit ASIC A Complete GuideОценок пока нет
- Shahid Qureshi MSEEДокумент1 страницаShahid Qureshi MSEEShahid QureshiОценок пока нет
- PCIe Designguides PDFДокумент32 страницыPCIe Designguides PDFEdward DapitonОценок пока нет
- Unveil The Mystery of Code Coverage in Low-Power Designs: Achieving Power AwareДокумент13 страницUnveil The Mystery of Code Coverage in Low-Power Designs: Achieving Power AwareNishit GuptaОценок пока нет
- On-the-Fly Reset Handling in UVM TestbenchesДокумент7 страницOn-the-Fly Reset Handling in UVM TestbenchesChandan ChoudhuryОценок пока нет
- Sequence, Sequence on the Wall – Who’s the Fairest of Them All? Using UVM SequencesДокумент24 страницыSequence, Sequence on the Wall – Who’s the Fairest of Them All? Using UVM SequencesNivaz ChockkalingamОценок пока нет
- HunterSNUGSV UVM Resets PaperДокумент13 страницHunterSNUGSV UVM Resets PaperpriyajeejoОценок пока нет
- DUI0305C Amba Axi PC UgДокумент58 страницDUI0305C Amba Axi PC UgSuman LokondaОценок пока нет
- Sva 4 Formal QRG v2.1Документ2 страницыSva 4 Formal QRG v2.1Nikhil jainОценок пока нет
- Course Uvm-Framework Session17 Code-Generation-Guidelines BodenДокумент36 страницCourse Uvm-Framework Session17 Code-Generation-Guidelines BodenQuý Trương QuangОценок пока нет
- Chapter 2Документ41 страницаChapter 2Lavanya GowdaОценок пока нет
- Riscv Spec PDFДокумент239 страницRiscv Spec PDFpozitron_plusОценок пока нет
- DUI0534A Amba 4 Axi4 Protocol Assertions r0p0 UgДокумент47 страницDUI0534A Amba 4 Axi4 Protocol Assertions r0p0 UgSoumen BasakОценок пока нет
- Xilinx Answer 56616 7 Series PCIe Link Training Debug GuideДокумент88 страницXilinx Answer 56616 7 Series PCIe Link Training Debug GuidevpsampathОценок пока нет
- DVClub Advanced Scoreboarding Techniques-FrancoisДокумент23 страницыDVClub Advanced Scoreboarding Techniques-Francoiscoolkad81Оценок пока нет
- Ankit ResumeДокумент3 страницыAnkit ResumenikkyjОценок пока нет
- SCALe-UVM-REG - FlowДокумент14 страницSCALe-UVM-REG - FlowTracie ShawОценок пока нет
- Assessment of Cache Coherence ProtocolsДокумент195 страницAssessment of Cache Coherence Protocolscharity_iitm100% (1)
- Axi BFMДокумент85 страницAxi BFMIgor AmosovОценок пока нет
- Verification Approach For ASIC Generic IP Functional VerificationДокумент3 страницыVerification Approach For ASIC Generic IP Functional VerificationMohammad Seemab AslamОценок пока нет
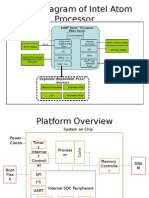
- Block Diagram of Intel Atom ProcessorДокумент23 страницыBlock Diagram of Intel Atom Processorfestio94Оценок пока нет
- Adv Verif Topics Book Final-ACCELERATIONДокумент25 страницAdv Verif Topics Book Final-ACCELERATIONcoolkad81Оценок пока нет
- Fuzzy Logic Design Using VHDL On FPGAДокумент69 страницFuzzy Logic Design Using VHDL On FPGAadaikammeik100% (1)
- AMD Gem5 APU Simulator Micro 2015 Final PDFДокумент62 страницыAMD Gem5 APU Simulator Micro 2015 Final PDFflintfireforgeОценок пока нет
- SV-UVM of AXI - WBДокумент4 страницыSV-UVM of AXI - WBRahul HanaОценок пока нет
- Janick Bergeron - Writing Testbenches Functional Verification of HDL Models-Springer (2003)Документ358 страницJanick Bergeron - Writing Testbenches Functional Verification of HDL Models-Springer (2003)arivalagan13Оценок пока нет
- UVM Interview Questions VLSI Encyclopedia PDFДокумент7 страницUVM Interview Questions VLSI Encyclopedia PDFQuastnОценок пока нет
- Ahb-Lite To Apb Protocol: BY Shraddha Devaiya EC - 018 Anand Therattil EC - 092Документ29 страницAhb-Lite To Apb Protocol: BY Shraddha Devaiya EC - 018 Anand Therattil EC - 092AnandОценок пока нет
- William K Lam Hardware Design Verification Simulation and Formal Method Based Approaches Prentice Hall 2008Документ837 страницWilliam K Lam Hardware Design Verification Simulation and Formal Method Based Approaches Prentice Hall 2008ganapathi50% (2)
- Introduction To Formal Equivalence Verification (FEV) : Erik Seligman CS 510, Lecture 4, January 2009Документ50 страницIntroduction To Formal Equivalence Verification (FEV) : Erik Seligman CS 510, Lecture 4, January 2009ddamitОценок пока нет
- Senior Design Verification Engineer in Phoenix AZ Resume Lloyd HeathДокумент3 страницыSenior Design Verification Engineer in Phoenix AZ Resume Lloyd HeathLloyd HeathОценок пока нет
- Sva FV Tutorial HVC2013Документ118 страницSva FV Tutorial HVC2013passep08Оценок пока нет
- Lal Usb Interface Vlsi 2010Документ22 страницыLal Usb Interface Vlsi 2010Ygb RedaОценок пока нет
- FIFOДокумент201 страницаFIFOMohammedОценок пока нет
- Study and Analysis of RTL Verification Tool IEEE ConferenceДокумент7 страницStudy and Analysis of RTL Verification Tool IEEE ConferenceZC LОценок пока нет
- Experiment (7) Multiplexer/DemultiplexerДокумент0 страницExperiment (7) Multiplexer/DemultiplexerUsman Sabir100% (1)
- Dma ControllerДокумент166 страницDma ControllerpraveenbhongiriОценок пока нет
- AHBДокумент59 страницAHBGautham Lukkur Venugopal50% (2)
- A Synthesizable Design of Amba-Axi Protocol For Soc IntegrationДокумент8 страницA Synthesizable Design of Amba-Axi Protocol For Soc IntegrationvjemmanОценок пока нет
- UART Protocol 00 For BC3MM Module Rev1.0Документ12 страницUART Protocol 00 For BC3MM Module Rev1.0kaaashuОценок пока нет
- How To Write FSM Is VerilogДокумент8 страницHow To Write FSM Is VerilogAyaz MohammedОценок пока нет
- AXI Implementation On SoCДокумент5 страницAXI Implementation On SoCvijaykumarn12Оценок пока нет
- USB3SS_VERIFICATIONДокумент34 страницыUSB3SS_VERIFICATIONSachin Kumar JainОценок пока нет
- Design and Verification of AMBA AHBДокумент6 страницDesign and Verification of AMBA AHBrishi tejuОценок пока нет
- Spyglass-Cdc: Industry Most Comprehensive, Practical, and Powerful CDC SolutionДокумент2 страницыSpyglass-Cdc: Industry Most Comprehensive, Practical, and Powerful CDC SolutionRamakrishnaRao SoogooriОценок пока нет
- Apb DocДокумент117 страницApb DocVikas ZurmureОценок пока нет
- Microsoft PowerPoint - SoC Design Flow Tools CodesignДокумент110 страницMicrosoft PowerPoint - SoC Design Flow Tools CodesignRathan NОценок пока нет
- Arm Amba AhbДокумент18 страницArm Amba AhbgeethaОценок пока нет
- Introduction to Model Checking: An Overview of Formal Verification Techniques and Their ApplicationsДокумент53 страницыIntroduction to Model Checking: An Overview of Formal Verification Techniques and Their ApplicationsphanitezaОценок пока нет
- 1442 - Reusable and Scalable Verification Solutions For Designing AIML SoCsДокумент34 страницы1442 - Reusable and Scalable Verification Solutions For Designing AIML SoCsAnh Dung LeОценок пока нет
- Xge Mac SpecДокумент24 страницыXge Mac Spechackdrag100% (1)
- Verilab Dvcon Tutorial AДокумент138 страницVerilab Dvcon Tutorial Ahimabindu2305Оценок пока нет
- ARM7 Processor FamilyДокумент8 страницARM7 Processor FamilySaravana KumarОценок пока нет
- Software Testing TechniquesДокумент17 страницSoftware Testing TechniquesTaqi Shah0% (1)
- Software Testing StrategiesДокумент16 страницSoftware Testing StrategiesTaqi ShahОценок пока нет
- Lect 3 Project ManagementДокумент46 страницLect 3 Project ManagementTaqi ShahОценок пока нет
- Tutorial Week 7 - Class and Entity-Relationship DiagramsДокумент14 страницTutorial Week 7 - Class and Entity-Relationship DiagramsSab707100% (1)
- Software Cost and Effort EstimationДокумент16 страницSoftware Cost and Effort EstimationTaqi ShahОценок пока нет
- Normalization NotesДокумент20 страницNormalization NotesShenna Kim CasinilloОценок пока нет
- Lect 5 Team OrgnizationДокумент13 страницLect 5 Team OrgnizationSheikh Waqas IqbalОценок пока нет
- Analysis ModelingДокумент78 страницAnalysis ModelingTaqi ShahОценок пока нет
- Software Cost and Effort Estimation in Software Engineering ProcessДокумент16 страницSoftware Cost and Effort Estimation in Software Engineering ProcessTaqi ShahОценок пока нет
- Lect 4 Cost EstimationДокумент16 страницLect 4 Cost EstimationTaqi ShahОценок пока нет
- Well Meadows Hospital NormalizationДокумент3 страницыWell Meadows Hospital NormalizationTaqi Shah50% (2)
- Software Engineering 1 - Lec 5 Software Project ManagmentДокумент68 страницSoftware Engineering 1 - Lec 5 Software Project ManagmentTaqi ShahОценок пока нет
- ERD To Relational Model ExampleДокумент7 страницERD To Relational Model ExampleTaqi ShahОценок пока нет
- Normalization Exercise AnswerДокумент8 страницNormalization Exercise Answermanisgurlz100% (2)
- Lesson 3: An Introduction To Data ModelingДокумент23 страницыLesson 3: An Introduction To Data Modelingabhi1banerjeeeОценок пока нет
- ERD Database Modeling.Документ53 страницыERD Database Modeling.Taqi ShahОценок пока нет
- Conceptual Data ModelingДокумент24 страницыConceptual Data ModelingTaqi Shah100% (1)
- Entity Relationship DiagramsДокумент12 страницEntity Relationship Diagramsbunty142001Оценок пока нет
- Cmmi Uaar Seminar 2012Документ77 страницCmmi Uaar Seminar 2012Taqi ShahОценок пока нет
- Practice: A Generic ViewДокумент18 страницPractice: A Generic ViewTaqi ShahОценок пока нет
- Lect 4 Req Engin ProcessДокумент41 страницаLect 4 Req Engin ProcessTaqi ShahОценок пока нет
- CH 03Документ76 страницCH 03Taqi ShahОценок пока нет
- English Solution2 - Class 10 EnglishДокумент34 страницыEnglish Solution2 - Class 10 EnglishTaqi ShahОценок пока нет
- Process: A Generic ViewДокумент14 страницProcess: A Generic ViewTaqi ShahОценок пока нет
- Process: A Generic ViewДокумент14 страницProcess: A Generic ViewTaqi ShahОценок пока нет
- Hardware Tutorial Solution 09Документ2 страницыHardware Tutorial Solution 09Taqi ShahОценок пока нет
- CH 01Документ16 страницCH 01Taqi ShahОценок пока нет
- S.E Chap ModelsДокумент41 страницаS.E Chap ModelsTaqi ShahОценок пока нет
- English Solution - Class 10 EnglishДокумент77 страницEnglish Solution - Class 10 EnglishTaqi ShahОценок пока нет
- HW1 SolДокумент9 страницHW1 SolTaqi ShahОценок пока нет
- Nagaraj - Salesforce DeveloperДокумент5 страницNagaraj - Salesforce DeveloperthirakannamnagarajaachariОценок пока нет
- i.MX RT1050 Processor Reference Manual PDFДокумент3 357 страницi.MX RT1050 Processor Reference Manual PDFfranz_feingeist100% (2)
- V GuardДокумент2 страницыV GuardandresavilaОценок пока нет
- HCL Company ProfileДокумент8 страницHCL Company ProfilePriya ThakurОценок пока нет
- Value ChainДокумент135 страницValue ChainJunaid SabriОценок пока нет
- Aca Tut1-1Документ5 страницAca Tut1-1ArvindОценок пока нет
- VisualAge PLI Programming Guide Ver 2.1Документ587 страницVisualAge PLI Programming Guide Ver 2.1neokci100% (1)
- 7 Ways To Optimize JenkinsДокумент15 страниц7 Ways To Optimize JenkinsAgung PrasetyoОценок пока нет
- TC-P42X3X: 42 Inch Class 720p Plasma HDTVДокумент7 страницTC-P42X3X: 42 Inch Class 720p Plasma HDTVEstuardoОценок пока нет
- Name: Department: Roll No: Subject: Submitted To:: Araiz Mirza Bs (It) 082 Data-Base Sir SayyamДокумент4 страницыName: Department: Roll No: Subject: Submitted To:: Araiz Mirza Bs (It) 082 Data-Base Sir SayyamAraiz IjazОценок пока нет
- Training E&M: Issued by SPL/GK 2012-03Документ130 страницTraining E&M: Issued by SPL/GK 2012-03Nadir100% (1)
- W M U G NL: Automation How To Make My IT Life EasierДокумент34 страницыW M U G NL: Automation How To Make My IT Life EasierHamelОценок пока нет
- Grade 7 SyllabusДокумент11 страницGrade 7 SyllabusSarah May CruzОценок пока нет
- DevSecOps A CASE STUDY ON A SAMPLE IMPLEMENTATIONДокумент4 страницыDevSecOps A CASE STUDY ON A SAMPLE IMPLEMENTATIONQuân - VCCloud Đinh CôngОценок пока нет
- DH XVR7x16-X MultiLang V4.001.0000000.15.R.211013 Release-Notes PDFДокумент6 страницDH XVR7x16-X MultiLang V4.001.0000000.15.R.211013 Release-Notes PDFMinou NmiОценок пока нет
- Introduction to procedures in assembly languageДокумент8 страницIntroduction to procedures in assembly languageJames ChuОценок пока нет
- VMware WorkstationДокумент406 страницVMware WorkstationsocrazОценок пока нет
- InstallДокумент2 страницыInstallZoran VerbicОценок пока нет
- R6K+TDM ConfigurationДокумент37 страницR6K+TDM ConfigurationMuhammad Sikander hayat100% (1)
- Bug ReportДокумент20 страницBug ReportesperanzaОценок пока нет
- Arm BookДокумент221 страницаArm BookGandhimathinathanОценок пока нет
- Website: Vce To PDF Converter: Facebook: Twitter:: 1Z0-1072-20.Vceplus - Premium.Exam.60QДокумент22 страницыWebsite: Vce To PDF Converter: Facebook: Twitter:: 1Z0-1072-20.Vceplus - Premium.Exam.60QMartin YinОценок пока нет
- App PM5200English-OEM-A2 QSG 20120520 CYRUS 20130221030616Документ14 страницApp PM5200English-OEM-A2 QSG 20120520 CYRUS 20130221030616Riski SuhardinataОценок пока нет
- Os LabДокумент26 страницOs LabgunaОценок пока нет
- The Work Life of Developers: Activities, Switches and Perceived ProductivityДокумент17 страницThe Work Life of Developers: Activities, Switches and Perceived ProductivityDante Callo FuentesОценок пока нет
- MyLocker User Manual v1.0 (Mode 8)Документ18 страницMyLocker User Manual v1.0 (Mode 8)gika12345Оценок пока нет
- Gmail Keyboard Shortcuts GuideДокумент5 страницGmail Keyboard Shortcuts Guidesanju2sanjuОценок пока нет
- Gpu Accelerator Co Processor Capabilities 18Документ3 страницыGpu Accelerator Co Processor Capabilities 18VisawjeetMallikОценок пока нет
- Oracle Database Appliance X6-2-HA: Fully Redundant Integrated SystemДокумент6 страницOracle Database Appliance X6-2-HA: Fully Redundant Integrated SystemOliveira RubensОценок пока нет
- Service & Support: Support Packages For STEP 7 V11Документ9 страницService & Support: Support Packages For STEP 7 V11Grin GoОценок пока нет