Вам также может понравиться
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- MUFF WIGGLER - View Topic - Wiard 1200 Series Info PDFДокумент19 страницMUFF WIGGLER - View Topic - Wiard 1200 Series Info PDFMat DalgleishОценок пока нет
- A Neighborhood of Infinity - Constraining Types With Regular ExpressionsДокумент14 страницA Neighborhood of Infinity - Constraining Types With Regular ExpressionsDan Piponi100% (1)
- A Neighborhood of Infinity: Cofree Meets FreeДокумент11 страницA Neighborhood of Infinity: Cofree Meets FreeDan PiponiОценок пока нет
- On Removing Singularities From Rational FunctionsДокумент7 страницOn Removing Singularities From Rational FunctionsDan PiponiОценок пока нет
- On Removing Singularities From Rational FunctionsДокумент7 страницOn Removing Singularities From Rational FunctionsDan PiponiОценок пока нет
- Buffon's Needle Problem Solved SimplyДокумент9 страницBuffon's Needle Problem Solved SimplyDan PiponiОценок пока нет
- What's The Use of A Transfinite Ordinal?Документ7 страницWhat's The Use of A Transfinite Ordinal?Dan PiponiОценок пока нет
- What's The Use of A Transfinite OrdinalДокумент6 страницWhat's The Use of A Transfinite OrdinalDan PiponiОценок пока нет
- Distributed Computing With Alien Technology PDFДокумент8 страницDistributed Computing With Alien Technology PDFDan PiponiОценок пока нет
- How Can It Possibly Be That We Can Exhaustively Search An Infinite Space in A Finite Time?Документ11 страницHow Can It Possibly Be That We Can Exhaustively Search An Infinite Space in A Finite Time?Dan PiponiОценок пока нет
- Arboreal Isomorphisms From Nuclear PenniesДокумент10 страницArboreal Isomorphisms From Nuclear PenniesDan PiponiОценок пока нет
- What Stops Us Defining Truth?Документ9 страницWhat Stops Us Defining Truth?Dan PiponiОценок пока нет
- Using Thermonuclear Pennies To Embed Complex Numbers As TypesДокумент12 страницUsing Thermonuclear Pennies To Embed Complex Numbers As TypesDan PiponiОценок пока нет
- A Neighborhood of Infinity - A Pictorial Proof of The Hairy Ball TheoremДокумент9 страницA Neighborhood of Infinity - A Pictorial Proof of The Hairy Ball TheoremDan PiponiОценок пока нет
- Fast and Exact Convolution With Polygonal FiltersДокумент12 страницFast and Exact Convolution With Polygonal FiltersDan PiponiОценок пока нет
- Shuffles, Bayes' Theorem and ContinuationsДокумент7 страницShuffles, Bayes' Theorem and ContinuationsDan PiponiОценок пока нет
- EulerДокумент6 страницEulerDan Piponi100% (1)
- Derivatives of Regular ExpressionsДокумент14 страницDerivatives of Regular ExpressionsDan PiponiОценок пока нет
- PMPДокумент12 страницPMPDan PiponiОценок пока нет
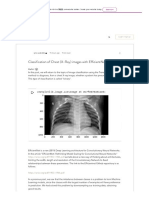
- Classification of Chest (X-Ray) Images With EfficientNet CODEДокумент17 страницClassification of Chest (X-Ray) Images With EfficientNet CODETimothy SurajОценок пока нет
- Information Gain CalculatorДокумент14 страницInformation Gain CalculatorfansafirОценок пока нет
- Eco Survey 2017-18 SummaryДокумент1 страницаEco Survey 2017-18 SummarySarojkumar BhosleОценок пока нет
- ECE Question Bank 2017-2021Документ378 страницECE Question Bank 2017-2021menakadevieceОценок пока нет
- Chap 18Документ51 страницаChap 18Ahmed HussainОценок пока нет
- Information-Theoretic IdentitiesДокумент29 страницInformation-Theoretic IdentitiesprapunОценок пока нет
- VIP Course OverviewДокумент23 страницыVIP Course OverviewdialauchennaОценок пока нет
- Neural Nets (Wrap-Up) and Decision Trees: CS 188: Artificial IntelligenceДокумент26 страницNeural Nets (Wrap-Up) and Decision Trees: CS 188: Artificial IntelligenceMihai IlieОценок пока нет
- Ble 97Документ303 страницыBle 97Taye ToluОценок пока нет
- Ec 2252 Communication Theory Lecture NotesДокумент120 страницEc 2252 Communication Theory Lecture NotesChoco BoxОценок пока нет
- Entropy Handbook GuideДокумент22 страницыEntropy Handbook GuideDiego Ernesto Hernandez JimenezОценок пока нет
- CSR2 - Week 3 - QuizДокумент5 страницCSR2 - Week 3 - QuizCSRRS67% (3)
- Active Learning With Sampling by Uncertainty and Density For WordДокумент8 страницActive Learning With Sampling by Uncertainty and Density For WordgabrielgonzaloОценок пока нет
- 15-359: Probability and Computing Inequalities: N J N JДокумент11 страниц15-359: Probability and Computing Inequalities: N J N JthelastairanandОценок пока нет
- Basic limits on protocol information in data communication networksДокумент14 страницBasic limits on protocol information in data communication networksNadeem ChannaОценок пока нет
- Communication Theory of Secrecy SystemsДокумент57 страницCommunication Theory of Secrecy SystemsTomJeffriesОценок пока нет
- Entropy and Its PropertiesДокумент6 страницEntropy and Its Propertiesece.kavitha mamcetОценок пока нет
- Science - Abo7257 SMДокумент105 страницScience - Abo7257 SM张议Оценок пока нет
- Entropy CodingДокумент18 страницEntropy CodingRakesh InaniОценок пока нет
- Multimedia Communication - ECE - VTU - 8th Sem - Unit 3 - Text and Image Compression, RamisuniverseДокумент30 страницMultimedia Communication - ECE - VTU - 8th Sem - Unit 3 - Text and Image Compression, Ramisuniverseramisuniverse83% (6)
- Block Arithmetic Coding Source Compression: AbstructДокумент9 страницBlock Arithmetic Coding Source Compression: AbstructGabbu GoshaОценок пока нет
- CCS Password Metric MeasurementДокумент14 страницCCS Password Metric Measurementparama777Оценок пока нет
- Stochastic thermodynamics interpretation of information geometryДокумент13 страницStochastic thermodynamics interpretation of information geometryAlessio GagliardiОценок пока нет
- CommsII Problem Set 3 With AddendumДокумент2 страницыCommsII Problem Set 3 With AddendumMarlon BoucaudОценок пока нет
- Binary Cross Entropy and Categorical Cross EntropyДокумент19 страницBinary Cross Entropy and Categorical Cross EntropyLAKSHYA SINGHОценок пока нет
- Probability and Information Theory: Key ConceptsДокумент26 страницProbability and Information Theory: Key ConceptsIndra Kelana JayaОценок пока нет
- Information Theory & Source CodingДокумент14 страницInformation Theory & Source CodingmarxxОценок пока нет
- EE5143 Tutorial1Документ5 страницEE5143 Tutorial1Sayan Rudra PalОценок пока нет
- Bits Signals and PacketsДокумент98 страницBits Signals and PacketsrashidОценок пока нет