Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Electrical Resume Boyet PascuaДокумент2 страницыElectrical Resume Boyet PascuaAucsap BoyetОценок пока нет
- Lesson 3 - Equipment and FacilitiesДокумент15 страницLesson 3 - Equipment and FacilitiesRishiel Dimple BalonesОценок пока нет
- Land Rover Popular PartsДокумент25 страницLand Rover Popular Partseleanor shelbyОценок пока нет
- Licensing Electrical Cables JointersДокумент17 страницLicensing Electrical Cables Jointersraedkaissi5096100% (2)
- Boiler Safety ProgramДокумент8 страницBoiler Safety ProgramHussain KhanОценок пока нет
- QA QC: ApproachДокумент3 страницыQA QC: ApproachSherif EltoukhiОценок пока нет
- Exact Solution Tank DrainageДокумент8 страницExact Solution Tank DrainageFelipe CastОценок пока нет
- MP-20x Datasheet 1Документ2 страницыMP-20x Datasheet 1Francisco MoragaОценок пока нет
- Casting Slides 103-130Документ28 страницCasting Slides 103-130Swaraj PrakashОценок пока нет
- Mine Survey CertificationДокумент37 страницMine Survey CertificationAgustin Eliasta Ginting100% (1)
- Outline Spesifikasi BPKPДокумент44 страницыOutline Spesifikasi BPKPnadyaОценок пока нет
- Flow Meters Butt WeldДокумент3 страницыFlow Meters Butt WeldPan GulfОценок пока нет
- Transformer Design and Optimization A Literature Survey PDFДокумент26 страницTransformer Design and Optimization A Literature Survey PDFRushikesh MaliОценок пока нет
- Methodology - Static Load Test PDFДокумент5 страницMethodology - Static Load Test PDFEngr. MahmudОценок пока нет
- Office Automation & Attendance System Using IoTДокумент4 страницыOffice Automation & Attendance System Using IoTAnonymous kw8Yrp0R5rОценок пока нет
- Manesar AutomotiveДокумент101 страницаManesar Automotiveshriya shettiwarОценок пока нет
- The Radio ClubДокумент7 страницThe Radio ClubDom CasualОценок пока нет
- CSC204 - Chapter 3.1Документ30 страницCSC204 - Chapter 3.1Alif HaiqalОценок пока нет
- Simple DistillationДокумент2 страницыSimple DistillationHarvey A. JuicoОценок пока нет
- GasesДокумент102 страницыGasesLya EscoteОценок пока нет
- CVision AVR Man3 PDFДокумент513 страницCVision AVR Man3 PDFsigiloОценок пока нет
- Assessing The Feasibility of Using The Heat Demand-Outdoor Temperature Function For A Long-Term District Heat Demand ForecastДокумент5 страницAssessing The Feasibility of Using The Heat Demand-Outdoor Temperature Function For A Long-Term District Heat Demand ForecastmohammedelamenОценок пока нет
- Workshop Microproject ListДокумент2 страницыWorkshop Microproject ListABDUL KADIR MUZAMMIL HUSAIN KHANОценок пока нет
- Fluid Mechanics 2 Momentum Equ. 2Документ3 страницыFluid Mechanics 2 Momentum Equ. 2Mohamed Al AminОценок пока нет
- AcetophenoneДокумент1 страницаAcetophenoneDinda Melissa ArdiОценок пока нет
- PTWДокумент3 страницыPTWAngel Silva VicenteОценок пока нет
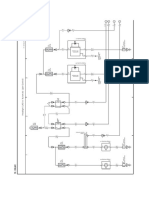
- Overall EWD Vehicle Exterior Rear Fog LightДокумент10 страницOverall EWD Vehicle Exterior Rear Fog Lightgabrielzinho43Оценок пока нет
- Fastshapes - Sprocket: Typical ApplicationsДокумент23 страницыFastshapes - Sprocket: Typical ApplicationsJimmy MyОценок пока нет
- Fuji Xerox cp105b Service Manual PDFДокумент2 страницыFuji Xerox cp105b Service Manual PDFSyaf RoniОценок пока нет
- Foreword by Brett Queener - Agile Product Management With Scrum - Creating Products That Customers LoveДокумент3 страницыForeword by Brett Queener - Agile Product Management With Scrum - Creating Products That Customers LoveJoao Paulo MouraОценок пока нет