Вам также может понравиться
- Assessment of Knowledge, Attitude and Practices Concerning Food Safety Among Restaurant Workers in Putrajaya, MalaysiaДокумент10 страницAssessment of Knowledge, Attitude and Practices Concerning Food Safety Among Restaurant Workers in Putrajaya, MalaysiaAlexander DeckerОценок пока нет
- Assessment For The Improvement of Teaching and Learning of Christian Religious Knowledge in Secondary Schools in Awgu Education Zone, Enugu State, NigeriaДокумент11 страницAssessment For The Improvement of Teaching and Learning of Christian Religious Knowledge in Secondary Schools in Awgu Education Zone, Enugu State, NigeriaAlexander DeckerОценок пока нет
- Assessing The Effect of Liquidity On Profitability of Commercial Banks in KenyaДокумент10 страницAssessing The Effect of Liquidity On Profitability of Commercial Banks in KenyaAlexander DeckerОценок пока нет
- Analysis of Teachers Motivation On The Overall Performance ofДокумент16 страницAnalysis of Teachers Motivation On The Overall Performance ofAlexander DeckerОценок пока нет
- An Overview On Co-Operative Societies in BangladeshДокумент11 страницAn Overview On Co-Operative Societies in BangladeshAlexander DeckerОценок пока нет
- Analysis of Blast Loading Effect On High Rise BuildingsДокумент7 страницAnalysis of Blast Loading Effect On High Rise BuildingsAlexander DeckerОценок пока нет
- An Experiment To Determine The Prospect of Using Cocoa Pod Husk Ash As Stabilizer For Weak Lateritic SoilsДокумент8 страницAn Experiment To Determine The Prospect of Using Cocoa Pod Husk Ash As Stabilizer For Weak Lateritic SoilsAlexander DeckerОценок пока нет
- Agronomic Evaluation of Eight Genotypes of Hot Pepper (Capsicum SPP L.) in A Coastal Savanna Zone of GhanaДокумент15 страницAgronomic Evaluation of Eight Genotypes of Hot Pepper (Capsicum SPP L.) in A Coastal Savanna Zone of GhanaAlexander DeckerОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Topfast BRAND Catalogue Ingco 2021 MayДокумент116 страницTopfast BRAND Catalogue Ingco 2021 MayMoh AwadОценок пока нет
- General Mathematics SS3 2ND Term SchemeДокумент2 страницыGeneral Mathematics SS3 2ND Term Schemesam kaluОценок пока нет
- FDP VLSI Design at Deep Submicron Node PDFДокумент2 страницыFDP VLSI Design at Deep Submicron Node PDFpraneethshubОценок пока нет
- Pricelist 1Документ8 страницPricelist 1ChinangОценок пока нет
- All Siae Skus: SF Product Name SIAE Product Code Descrip:on Availability Product Family Unit LIST Price ($)Документ7 страницAll Siae Skus: SF Product Name SIAE Product Code Descrip:on Availability Product Family Unit LIST Price ($)Emerson Mayon SanchezОценок пока нет
- CompTIA A+ Lesson 3 Understanding, PATA, SATA, SCSIДокумент8 страницCompTIA A+ Lesson 3 Understanding, PATA, SATA, SCSIAli Ghalehban - علی قلعه بانОценок пока нет
- RESUME1Документ2 страницыRESUME1sagar09100% (5)
- Real Options BV Lec 14Документ49 страницReal Options BV Lec 14Anuranjan TirkeyОценок пока нет
- Ojt Evaluation Forms (Supervised Industry Training) SampleДокумент5 страницOjt Evaluation Forms (Supervised Industry Training) SampleJayJay Jimenez100% (3)
- Project Synopsis On LAN ConnectionДокумент15 страницProject Synopsis On LAN ConnectionডৰাজবংশীОценок пока нет
- Solution Documentation For Custom DevelopmentДокумент52 страницыSolution Documentation For Custom DevelopmentbayatalirezaОценок пока нет
- Analog Electronics-2 PDFДокумент20 страницAnalog Electronics-2 PDFAbhinav JangraОценок пока нет
- Clevite Bearing Book EB-40-07Документ104 страницыClevite Bearing Book EB-40-07lowelowelОценок пока нет
- List of Institutions With Ladderized Program Under Eo 358 JULY 2006 - DECEMBER 31, 2007Документ216 страницList of Institutions With Ladderized Program Under Eo 358 JULY 2006 - DECEMBER 31, 2007Jen CalaquiОценок пока нет
- BGP PDFДокумент100 страницBGP PDFJeya ChandranОценок пока нет
- ASM1 ProgramingДокумент14 страницASM1 ProgramingTran Cong Hoang (BTEC HN)Оценок пока нет
- Defenders of The Empire v1.4Документ13 страницDefenders of The Empire v1.4Iker Antolín MedinaОценок пока нет
- English ID Student S Book 1 - 015Документ1 страницаEnglish ID Student S Book 1 - 015Williams RoldanОценок пока нет
- Model Personal StatementДокумент2 страницыModel Personal StatementSwayam Tripathy100% (1)
- Philippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopДокумент45 страницPhilippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopAlorn CatibogОценок пока нет
- ParaphrasingДокумент11 страницParaphrasingAntiiSukmaОценок пока нет
- Citing Correctly and Avoiding Plagiarism: MLA Format, 7th EditionДокумент4 страницыCiting Correctly and Avoiding Plagiarism: MLA Format, 7th EditionDanish muinОценок пока нет
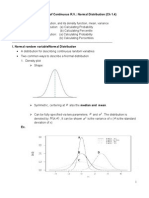
- Distribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsДокумент7 страницDistribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsPhạm Ngọc HòaОценок пока нет
- Diffrent Types of MapДокумент3 страницыDiffrent Types of MapIan GamitОценок пока нет
- Blackstone The Dash Model #1610 Owner's ManualДокумент53 страницыBlackstone The Dash Model #1610 Owner's ManualSydney Adam SteeleОценок пока нет
- Basics PDFДокумент21 страницаBasics PDFSunil KumarОценок пока нет
- 1207 - RTC-8065 II InglesДокумент224 страницы1207 - RTC-8065 II InglesGUILHERME SANTOSОценок пока нет
- Gol GumbazДокумент6 страницGol Gumbazmnv_iitbОценок пока нет
- Company Profile 4Документ54 страницыCompany Profile 4Khuloud JamalОценок пока нет
- Datasheet 6A8 FusívelДокумент3 страницыDatasheet 6A8 FusívelMluz LuzОценок пока нет