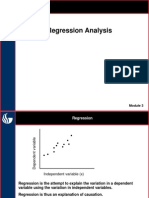
Вам также может понравиться
- Regression Equation GuideДокумент12 страницRegression Equation GuideKainaat YaseenОценок пока нет
- A-level Maths Revision: Cheeky Revision ShortcutsОт EverandA-level Maths Revision: Cheeky Revision ShortcutsРейтинг: 3.5 из 5 звезд3.5/5 (8)
- Simple Linear Regression GuideДокумент58 страницSimple Linear Regression Guideruchit2809Оценок пока нет
- Simple RegressionДокумент35 страницSimple RegressionHimanshu JainОценок пока нет
- Chapter 7 CДокумент27 страницChapter 7 CMahip Singh PathaniaОценок пока нет
- Simple Linear Regression AnalysisДокумент7 страницSimple Linear Regression AnalysiscarixeОценок пока нет
- Question 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1Документ9 страницQuestion 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1yaqoob008Оценок пока нет
- Correlation and Regression Analysis ExplainedДокумент30 страницCorrelation and Regression Analysis ExplainedgraCEОценок пока нет
- X X B X B X B y X X B X B N B Y: QMDS 202 Data Analysis and ModelingДокумент6 страницX X B X B X B y X X B X B N B Y: QMDS 202 Data Analysis and ModelingFaithОценок пока нет
- Regression Explains Variation in Dependent VariablesДокумент15 страницRegression Explains Variation in Dependent VariablesJuliefil Pheng AlcantaraОценок пока нет
- Water Resource-1Документ7 страницWater Resource-1Raman LuxОценок пока нет
- Simple Linear RegressionДокумент95 страницSimple Linear RegressionPooja GargОценок пока нет
- CPT Section D Quantitative Aptitude Chapter12 Regression AnalysisДокумент66 страницCPT Section D Quantitative Aptitude Chapter12 Regression AnalysisRanga SriОценок пока нет
- Simple Linear RegressionДокумент8 страницSimple Linear RegressionMarie BtaichОценок пока нет
- Univariate RegressionДокумент6 страницUnivariate RegressionSree NivasОценок пока нет
- Regression and Correlation Analysis ExplainedДокумент21 страницаRegression and Correlation Analysis ExplainedXtremo ManiacОценок пока нет
- Chapter Two: Bivariate Regression ModeДокумент54 страницыChapter Two: Bivariate Regression ModenahomОценок пока нет
- Linear Regression and Correlation: - 0 Positive Association - 0 Negative Association - 0 No AssociationДокумент31 страницаLinear Regression and Correlation: - 0 Positive Association - 0 Negative Association - 0 No AssociationSodhi NirdeepОценок пока нет
- Regression and Multiple Regression AnalysisДокумент21 страницаRegression and Multiple Regression AnalysisRaghu NayakОценок пока нет
- Regression and CorrelationДокумент13 страницRegression and CorrelationMireille KirstenОценок пока нет
- Correlation and Regression AnalysisДокумент10 страницCorrelation and Regression AnalysisPingotMagangaОценок пока нет
- 2b Multiple Linear RegressionДокумент14 страниц2b Multiple Linear RegressionNamita DeyОценок пока нет
- Econometrics Assignment AnswerДокумент13 страницEconometrics Assignment Answertigistugizaw37Оценок пока нет
- Stats and MathsДокумент29 страницStats and MathsMystiquemashalОценок пока нет
- Desingn of Experiments ch10Документ5 страницDesingn of Experiments ch10kannappanrajendranОценок пока нет
- QTIA Report 2012 IQRA UNIVERSITYДокумент41 страницаQTIA Report 2012 IQRA UNIVERSITYSyed Asfar Ali kazmiОценок пока нет
- Regression Analysis Techniques and AssumptionsДокумент43 страницыRegression Analysis Techniques and AssumptionsAmer RahmahОценок пока нет
- Regression Analysis ExplainedДокумент28 страницRegression Analysis ExplainedRobin GuptaОценок пока нет
- Multipple RegressionДокумент17 страницMultipple RegressionAngger Subagus UtamaОценок пока нет
- RegressionДокумент6 страницRegressionMansi ChughОценок пока нет
- Forecasting Cable Subscriber Numbers with Multiple RegressionДокумент100 страницForecasting Cable Subscriber Numbers with Multiple RegressionNilton de SousaОценок пока нет
- Inference For RegressionДокумент24 страницыInference For RegressionJosh PotashОценок пока нет
- Regression AnalysisДокумент5 страницRegression AnalysisAllen Kurt RamosОценок пока нет
- Intro Econometrics Minitests Regression AnalysisДокумент11 страницIntro Econometrics Minitests Regression AnalysisSabinaОценок пока нет
- Econometrics: Two Variable Regression: The Problem of EstimationДокумент28 страницEconometrics: Two Variable Regression: The Problem of EstimationsajidalirafiqueОценок пока нет
- SRT 605 - Topic (10) SLRДокумент39 страницSRT 605 - Topic (10) SLRpugОценок пока нет
- 09 Inference For Regression Part1Документ12 страниц09 Inference For Regression Part1Rama DulceОценок пока нет
- Bat-604 QTM Unit 2 FinalДокумент22 страницыBat-604 QTM Unit 2 FinalAditi MittalОценок пока нет
- Econometrics AssignmentДокумент40 страницEconometrics AssignmentMANAV ASHRAFОценок пока нет
- IGNOU AssignmentДокумент9 страницIGNOU AssignmentAbhilasha Shukla0% (1)
- Chapter 16Документ6 страницChapter 16maustroОценок пока нет
- 9 Correlation RegressionДокумент24 страницы9 Correlation RegressionZuera OpeqОценок пока нет
- Quiz Questions on Regression Analysis and CorrelationДокумент10 страницQuiz Questions on Regression Analysis and CorrelationHarsh ShrinetОценок пока нет
- CH4304EXPTSДокумент30 страницCH4304EXPTSAhren PageОценок пока нет
- Quess 2: The 95% Confidence Interval For The Population Proportion P Is (0.1608, 0.2392)Документ7 страницQuess 2: The 95% Confidence Interval For The Population Proportion P Is (0.1608, 0.2392)Tajinder SinghОценок пока нет
- TP06 Econometrics p2Документ20 страницTP06 Econometrics p2tommy.santos2Оценок пока нет
- Applied Business Forecasting and Planning: Multiple Regression AnalysisДокумент100 страницApplied Business Forecasting and Planning: Multiple Regression AnalysisRobby PangestuОценок пока нет
- RegressionДокумент43 страницыRegressionNikhil AggarwalОценок пока нет
- STAT741 Regression Analysis: Quiz #1 9pm, Wednesday, 1/31: y X y X y X y XДокумент3 страницыSTAT741 Regression Analysis: Quiz #1 9pm, Wednesday, 1/31: y X y X y X y XDayrine de la CruzОценок пока нет
- Regression and CorrelationДокумент14 страницRegression and CorrelationAhmed AyadОценок пока нет
- Simple Regression AnalysisДокумент4 страницыSimple Regression AnalysisFitriana SusantiОценок пока нет
- Regression Analysis: Understanding the Key Concepts of Regression ModelsДокумент39 страницRegression Analysis: Understanding the Key Concepts of Regression ModelsNavneet KumarОценок пока нет
- MAE 300 TextbookДокумент95 страницMAE 300 Textbookmgerges15Оценок пока нет
- Linear Regression Analysis and Least Square MethodsДокумент65 страницLinear Regression Analysis and Least Square MethodslovekeshthakurОценок пока нет
- Chat PasswordДокумент4 страницыChat PasswordDemis AsefaОценок пока нет
- Introduction To Multiple Regression: Dale E. Berger Claremont Graduate UniversityДокумент14 страницIntroduction To Multiple Regression: Dale E. Berger Claremont Graduate UniversityAhmad Ramadan IqbalОценок пока нет
- Chapter 8 Model Checking: Model Class Some Models ConclusionsДокумент7 страницChapter 8 Model Checking: Model Class Some Models ConclusionsjuntujuntuОценок пока нет
- Probability and Statistics: Simple Linear RegressionДокумент37 страницProbability and Statistics: Simple Linear RegressionNguyễn Linh ChiОценок пока нет
- HEC Chairman's Letter on University Achievements Showcasing EventsДокумент1 страницаHEC Chairman's Letter on University Achievements Showcasing EventsMuhammad TariqОценок пока нет
- Marketing CaseДокумент2 страницыMarketing CaseMuhammad TariqОценок пока нет
- Marketing: Case StudiesДокумент21 страницаMarketing: Case StudiesVanya Ivanova100% (1)
- CFP 2018 ICOSST Version2-1Документ1 страницаCFP 2018 ICOSST Version2-1Muhammad TariqОценок пока нет
- Marketing: Case StudiesДокумент21 страницаMarketing: Case StudiesVanya Ivanova100% (1)
- CH 18Документ62 страницыCH 18Muhammad TariqОценок пока нет
- Advt. No.6-2018 - 0Документ9 страницAdvt. No.6-2018 - 0Muhammad FurquanОценок пока нет
- Advt. No.6-2018 - 0Документ12 страницAdvt. No.6-2018 - 0Muhammad TariqОценок пока нет
- 1.Ch 1 Sociological PerspectiveДокумент43 страницы1.Ch 1 Sociological PerspectiveMuhammad TariqОценок пока нет
- Afs InterpretationДокумент5 страницAfs InterpretationMuhammad TariqОценок пока нет
- Work of LoadДокумент30 страницWork of LoadMuhammad TariqОценок пока нет
- ABCДокумент1 страницаABCMuhammad TariqОценок пока нет
- IQRAДокумент3 страницыIQRAMuhammad TariqОценок пока нет
- Iqra University: Asian Institute of Computer ScienceДокумент5 страницIqra University: Asian Institute of Computer ScienceMuhammad TariqОценок пока нет
- Ms AssignmentДокумент26 страницMs AssignmentMuhammad TariqОценок пока нет
- Bent Soren CointegrationДокумент12 страницBent Soren Cointegrationucbfsae2039Оценок пока нет
- Data FileДокумент5 страницData FileMuhammad TariqОценок пока нет
- Cadbury Pakistan's Mission and ProductsДокумент11 страницCadbury Pakistan's Mission and ProductsMuhammad TariqОценок пока нет
- Analysis of FactsДокумент7 страницAnalysis of FactsMuhammad TariqОценок пока нет
- Propositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatДокумент4 страницыPropositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatMuhammad TariqОценок пока нет
- Propositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatДокумент4 страницыPropositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatMuhammad TariqОценок пока нет
- Propositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatДокумент4 страницыPropositional Logic, Also Known As Sentential Logic and Statement Logic, Is The Branch of Logic ThatMuhammad TariqОценок пока нет
- Economics DemandДокумент5 страницEconomics DemandMuhammad Tariq100% (2)
- Marketing Plan RepositionДокумент19 страницMarketing Plan RepositionMuhammad TariqОценок пока нет
- Numerical. of Islamic ProductsДокумент19 страницNumerical. of Islamic ProductsMuhammad TariqОценок пока нет
- Nissan Marketing PlanДокумент47 страницNissan Marketing PlanNadeem80% (15)
- Islamic Finance Faces The Challenges of Conventional MonetaryДокумент20 страницIslamic Finance Faces The Challenges of Conventional MonetaryMuhammad TariqОценок пока нет
- Panera Bread's Success Through Adaptability and Customer FocusДокумент5 страницPanera Bread's Success Through Adaptability and Customer FocusMuhammad Tariq0% (3)
- Marketing Relaunch of Nestle Lemo and MaltaДокумент40 страницMarketing Relaunch of Nestle Lemo and MaltaMuhammad TariqОценок пока нет
- Financial Performance of Indian Pharmaceutical IndustryДокумент15 страницFinancial Performance of Indian Pharmaceutical IndustryRupal MuduliОценок пока нет
- Sternberg On Intelligences PDFДокумент11 страницSternberg On Intelligences PDFJoseph BartolataОценок пока нет
- Evaluating The Uncertainty of Polynomial Regression Models Using ExcelДокумент18 страницEvaluating The Uncertainty of Polynomial Regression Models Using ExcelSatria WijayaОценок пока нет
- Applied Eco No Metrics With StataДокумент170 страницApplied Eco No Metrics With Stataaba2nbОценок пока нет
- Gloss PDFДокумент8 страницGloss PDFSaadat Ullah KhanОценок пока нет
- Effects of Aggressive Traits On Cyberbullying: Mediated Moderation or Moderated Mediation?Документ13 страницEffects of Aggressive Traits On Cyberbullying: Mediated Moderation or Moderated Mediation?Warisur RahmanОценок пока нет
- 2016-Determinants of Supply Chain Responsiveness Among Firms in The Manufacturing Industry in MalaysiaДокумент7 страниц2016-Determinants of Supply Chain Responsiveness Among Firms in The Manufacturing Industry in MalaysiaRaajKumarОценок пока нет
- Parents' Reports of Sexual Communication With Children in Kindergarden To Grade 8, Byers, Sears, Weaver, 2008Документ12 страницParents' Reports of Sexual Communication With Children in Kindergarden To Grade 8, Byers, Sears, Weaver, 2008Titouan FantoniОценок пока нет
- ML Unit 2Документ21 страницаML Unit 22306603Оценок пока нет
- 62-73 - Kovac Leskosek StrelДокумент12 страниц62-73 - Kovac Leskosek StrelUPTOS SPORTОценок пока нет
- Determinants of Capital Structure in Ethiopian Commercial BanksДокумент92 страницыDeterminants of Capital Structure in Ethiopian Commercial Banksyebegashet100% (1)
- Project Report Submitted in The Partial Fulfillment of The Requirements For The Award of The Degree ofДокумент34 страницыProject Report Submitted in The Partial Fulfillment of The Requirements For The Award of The Degree ofpython developerОценок пока нет
- 15 - A Statistical Approach Linking Energy Management To Maintenance and Production FactorsДокумент15 страниц15 - A Statistical Approach Linking Energy Management To Maintenance and Production FactorsDanielle Alexandra CureОценок пока нет
- MPP 813 - Session 7 - NBK - Categorical Data AnalysisДокумент52 страницыMPP 813 - Session 7 - NBK - Categorical Data AnalysisEndang Dyah SetiariОценок пока нет
- Premarital Sex and Pregnancy I PDFДокумент23 страницыPremarital Sex and Pregnancy I PDFRoyyan MursyidanОценок пока нет
- DOS - Toll RoadДокумент11 страницDOS - Toll RoadDENNY SATYA ARIBOWOОценок пока нет
- Chapter 6 (Part I)Документ40 страницChapter 6 (Part I)Natasha Ghazali0% (1)
- Quiz 2Документ3 страницыQuiz 2api-235225555Оценок пока нет
- Bozorgzadeh Et Al. (2018) - Comp. Stat. Analysis of Intact Rock Strength For Reliability-Based DesignДокумент14 страницBozorgzadeh Et Al. (2018) - Comp. Stat. Analysis of Intact Rock Strength For Reliability-Based DesignSergio CastroОценок пока нет
- Tutorial LavaanДокумент49 страницTutorial LavaanMargareth BakesОценок пока нет
- System Identification Toolbox - Reference MatlabДокумент1 249 страницSystem Identification Toolbox - Reference MatlabWillian Leão100% (1)
- DocumentДокумент7 страницDocumentvasanthi_cyberОценок пока нет
- Research ReflectionДокумент2 страницыResearch ReflectionMaki CristobalОценок пока нет
- Identify The Controls and VariablesДокумент3 страницыIdentify The Controls and Variablesvaulted armorОценок пока нет
- The Influence of Training Towards Nurse Performance in Emergency Unit at Cibabat General Hospital CimahiДокумент10 страницThe Influence of Training Towards Nurse Performance in Emergency Unit at Cibabat General Hospital CimahiArya KresnadanaОценок пока нет
- SSRN Id4366801Документ4 страницыSSRN Id4366801NoonaОценок пока нет
- Module 4 BDA NOTESДокумент75 страницModule 4 BDA NOTESshashwatОценок пока нет
- NotesДокумент10 страницNotesMitul PatelОценок пока нет
- Graduate Admission Prediction Using Machine Learning: December 2020Документ6 страницGraduate Admission Prediction Using Machine Learning: December 2020VaradОценок пока нет
- Crop Growth Modeling and Its Applications in Agricultural MeteorologyДокумент27 страницCrop Growth Modeling and Its Applications in Agricultural MeteorologySabri Bou0% (1)
- Practical Guides to Testing and Commissioning of Mechanical, Electrical and Plumbing (Mep) InstallationsОт EverandPractical Guides to Testing and Commissioning of Mechanical, Electrical and Plumbing (Mep) InstallationsРейтинг: 3.5 из 5 звезд3.5/5 (3)
- Hyperspace: A Scientific Odyssey Through Parallel Universes, Time Warps, and the 10th DimensionОт EverandHyperspace: A Scientific Odyssey Through Parallel Universes, Time Warps, and the 10th DimensionРейтинг: 4.5 из 5 звезд4.5/5 (3)
- Piping and Pipeline Calculations Manual: Construction, Design Fabrication and ExaminationОт EverandPiping and Pipeline Calculations Manual: Construction, Design Fabrication and ExaminationРейтинг: 4 из 5 звезд4/5 (18)
- Einstein's Fridge: How the Difference Between Hot and Cold Explains the UniverseОт EverandEinstein's Fridge: How the Difference Between Hot and Cold Explains the UniverseРейтинг: 4.5 из 5 звезд4.5/5 (50)
- The Laws of Thermodynamics: A Very Short IntroductionОт EverandThe Laws of Thermodynamics: A Very Short IntroductionРейтинг: 4.5 из 5 звезд4.5/5 (10)
- Pressure Vessels: Design, Formulas, Codes, and Interview Questions & Answers ExplainedОт EverandPressure Vessels: Design, Formulas, Codes, and Interview Questions & Answers ExplainedРейтинг: 5 из 5 звезд5/5 (1)
- Introduction to Applied Thermodynamics: The Commonwealth and International Library: Mechanical Engineering DivisionОт EverandIntroduction to Applied Thermodynamics: The Commonwealth and International Library: Mechanical Engineering DivisionРейтинг: 2.5 из 5 звезд2.5/5 (3)
- Handbook of Mechanical and Materials EngineeringОт EverandHandbook of Mechanical and Materials EngineeringРейтинг: 5 из 5 звезд5/5 (4)
- Quantum Mechanics 4: Spin, Lasers, Pauli Exclusion & Barrier PenetrationОт EverandQuantum Mechanics 4: Spin, Lasers, Pauli Exclusion & Barrier PenetrationРейтинг: 1 из 5 звезд1/5 (1)
- Rolling Bearing Tribology: Tribology and Failure Modes of Rolling Element BearingsОт EverandRolling Bearing Tribology: Tribology and Failure Modes of Rolling Element BearingsОценок пока нет
- 1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideОт Everand1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideРейтинг: 3.5 из 5 звезд3.5/5 (7)
- Waves and Beaches: The Powerful Dynamics of Sea and CoastОт EverandWaves and Beaches: The Powerful Dynamics of Sea and CoastРейтинг: 4 из 5 звезд4/5 (1)
- Formulas and Calculations for Drilling, Production, and Workover: All the Formulas You Need to Solve Drilling and Production ProblemsОт EverandFormulas and Calculations for Drilling, Production, and Workover: All the Formulas You Need to Solve Drilling and Production ProblemsОценок пока нет
- Operational Amplifier Circuits: Analysis and DesignОт EverandOperational Amplifier Circuits: Analysis and DesignРейтинг: 4.5 из 5 звезд4.5/5 (2)
- Machinery Failure Analysis Handbook: Sustain Your Operations and Maximize UptimeОт EverandMachinery Failure Analysis Handbook: Sustain Your Operations and Maximize UptimeРейтинг: 3.5 из 5 звезд3.5/5 (4)
- Basic Alarm Electronics: Toolbox Guides for Security TechniciansОт EverandBasic Alarm Electronics: Toolbox Guides for Security TechniciansJohn SangerРейтинг: 4 из 5 звезд4/5 (1)