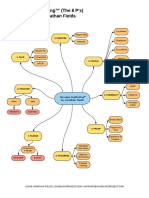
Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1091)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Ref 1150 PDFДокумент803 страницыRef 1150 PDFHarik Rafiry50% (2)
- Ken Draken Tokyo Revengers MBTIДокумент1 страницаKen Draken Tokyo Revengers MBTIÁngela Espinosa GonzálezОценок пока нет
- Edu 431 Reading Reflection CДокумент2 страницыEdu 431 Reading Reflection Capi-307185736Оценок пока нет
- Programme Guide - PGDMCH PDFДокумент58 страницProgramme Guide - PGDMCH PDFNJMU 2006Оценок пока нет
- Sastec2 - Technical Offer - 220kv Gis JSPL - Angul - Rev CДокумент18 страницSastec2 - Technical Offer - 220kv Gis JSPL - Angul - Rev CRakesh Kumar Singh (Phase 1B)Оценок пока нет
- Guidelines On Writing Master Thesis - 2012Документ21 страницаGuidelines On Writing Master Thesis - 2012soltoianu_irinaОценок пока нет
- Text Skimming and ScanningДокумент2 страницыText Skimming and ScanningJesus JaramilloОценок пока нет
- PISMДокумент3 страницыPISMKishore KumarОценок пока нет
- Molinos Eolicos VestasДокумент41 страницаMolinos Eolicos VestasOscar Männlich100% (1)
- PAGASA Philippines Weather Report 11 MARCH 2015Документ2 страницыPAGASA Philippines Weather Report 11 MARCH 2015asanesslightsОценок пока нет
- Glycolysis For NursesДокумент17 страницGlycolysis For NursesAaron WallaceОценок пока нет
- Deduction and InductionДокумент26 страницDeduction and InductionHania SohailОценок пока нет
- Arl TR 3567Документ72 страницыArl TR 3567AndrewScotsonОценок пока нет
- Lecture 9 MTH401 U2Документ25 страницLecture 9 MTH401 U2yunuzОценок пока нет
- Precise Software SolutionsДокумент2 страницыPrecise Software Solutionssaikat sarkarОценок пока нет
- Boundy8e PPT Ch03Документ29 страницBoundy8e PPT Ch03AndrewОценок пока нет
- Evaluation For Nonprint Materials (DepEd)Документ7 страницEvaluation For Nonprint Materials (DepEd)Shaira Grace Calderon67% (3)
- Kanji Dictionary for Foreigners Learning Japanese 2500 N5 to N1 by 志賀里美, 古田島聡美, 島崎英香, 王源Документ630 страницKanji Dictionary for Foreigners Learning Japanese 2500 N5 to N1 by 志賀里美, 古田島聡美, 島崎英香, 王源feyej100% (1)
- (Bruce H. Walker) Optical Design For Visual SystemДокумент166 страниц(Bruce H. Walker) Optical Design For Visual SystemDewata100% (3)
- 053 NAtional Library of WalesДокумент5 страниц053 NAtional Library of WalesDiana Teodora PiteiОценок пока нет
- NRB Bank ReportДокумент49 страницNRB Bank ReportTanvirBariОценок пока нет
- ReadMe KMSpico PortableДокумент4 страницыReadMe KMSpico PortableRez ShahОценок пока нет
- Limit State of Collapse Flexure (Theories and Examples)Документ21 страницаLimit State of Collapse Flexure (Theories and Examples)Aravind BhashyamОценок пока нет
- Success Scaffolding 8P 2018Документ1 страницаSuccess Scaffolding 8P 2018don_h_manzanoОценок пока нет
- VSSДокумент5 страницVSSAiman HakimОценок пока нет
- يَا نَبِي سَلَام عَلَيْكَДокумент1 страницаيَا نَبِي سَلَام عَلَيْكَAcengMNasruddinОценок пока нет
- Advanced Modal AnalysisДокумент8 страницAdvanced Modal Analysispriyankar007Оценок пока нет
- Schools Aglasem ComДокумент11 страницSchools Aglasem ComHarataRongpiОценок пока нет
- Record & Field Mapping For Fusion ReportsДокумент6 страницRecord & Field Mapping For Fusion ReportsRajiОценок пока нет
- Asd CabixДокумент22 страницыAsd CabixCanberk BinbayОценок пока нет