Вам также может понравиться
- Assignment 03Документ9 страницAssignment 03dilhaniОценок пока нет
- E2309 137950-1Документ8 страницE2309 137950-1Sarvesh MishraОценок пока нет
- Assignment 03Документ2 страницыAssignment 03Molto falsoОценок пока нет
- Ranked RetrievalДокумент52 страницыRanked RetrievalInstall MacОценок пока нет
- Tif Idf Cosine SimilarityДокумент44 страницыTif Idf Cosine SimilarityVaibhav GargОценок пока нет
- Lecture6 TfidfДокумент45 страницLecture6 TfidfHamzaОценок пока нет
- WordembeddingДокумент25 страницWordembeddingLayla El OuedeghyryОценок пока нет
- IRS BZU Lecture 7 Jan23Документ27 страницIRS BZU Lecture 7 Jan23jafarsadeeqi.pfaОценок пока нет
- Introduction To: Information RetrievalДокумент44 страницыIntroduction To: Information Retrievalnul loОценок пока нет
- Vector Space and IR EvaluationДокумент41 страницаVector Space and IR Evaluationahmeddoad79Оценок пока нет
- AI6122 Text Data Management & Analysis: TFIDF and Vector Space ModelДокумент27 страницAI6122 Text Data Management & Analysis: TFIDF and Vector Space ModelYujia TianОценок пока нет
- IR Unit 2Документ54 страницыIR Unit 2jaganbecsОценок пока нет
- Tf-Idf: David Kauchak cs160 Fall 2009Документ51 страницаTf-Idf: David Kauchak cs160 Fall 2009Vishal YadavОценок пока нет
- Vector Space Model: TF - IDF: Adapted From Lectures byДокумент37 страницVector Space Model: TF - IDF: Adapted From Lectures byJati Hamengku GatiОценок пока нет
- Term Weighting and Similarity Measures ExplainedДокумент54 страницыTerm Weighting and Similarity Measures Explainedendris yimer0% (1)
- 02 Boolean RetrievalДокумент52 страницы02 Boolean RetrievalDharmendra PatelОценок пока нет
- Introduction To: Information RetrievalДокумент40 страницIntroduction To: Information RetrievalVidit GoelОценок пока нет
- Ex. No.: Text Mining On Commercial Application Date: MotivationДокумент9 страницEx. No.: Text Mining On Commercial Application Date: MotivationRamkumardevendiranDevenОценок пока нет
- CSE442 TextДокумент89 страницCSE442 Textsanskritiiiii.2002Оценок пока нет
- Midterm SolДокумент6 страницMidterm SolMohasin Azeez KhanОценок пока нет
- Cumulative DistributionДокумент68 страницCumulative Distributionorang_gantengОценок пока нет
- Unit - 2.2Документ14 страницUnit - 2.2Dr.K. BhuvaneswariОценок пока нет
- Chapter 2 - Representing Sample Data: Graphical DisplaysДокумент16 страницChapter 2 - Representing Sample Data: Graphical DisplaysdeimanciukasОценок пока нет
- Acquisition and Analysis of Neural Data: Analytical Problem Set 1Документ3 страницыAcquisition and Analysis of Neural Data: Analytical Problem Set 1PritamSenОценок пока нет
- Information Retrieval (CS6370) : Maunendra Sankar DesarkarДокумент44 страницыInformation Retrieval (CS6370) : Maunendra Sankar DesarkarbhagatОценок пока нет
- 3 TermweightingДокумент34 страницы3 TermweightinggcrossnОценок пока нет
- 3 TermweightingДокумент41 страница3 TermweightingHailemariam SetegnОценок пока нет
- Reliab 3 BagusДокумент22 страницыReliab 3 BagusMuhamad YusufОценок пока нет
- SOLUTIONS : Midterm Exam For Simulation (CAP 4800)Документ14 страницSOLUTIONS : Midterm Exam For Simulation (CAP 4800)Amit DostОценок пока нет
- On Information RetrivalДокумент23 страницыOn Information RetrivalSamiran PandaОценок пока нет
- Boolean Retrieval: Design and data structures of a simple information retrieval systemДокумент60 страницBoolean Retrieval: Design and data structures of a simple information retrieval systemBirhane Bekele KebedeОценок пока нет
- Time Series AnalysisДокумент66 страницTime Series AnalysisShiv Ganesh SОценок пока нет
- Chapter-3 TermweightingДокумент17 страницChapter-3 Termweightingabraham getuОценок пока нет
- 01 IntroДокумент145 страниц01 IntroRajput SinghОценок пока нет
- Survival Analysis in R PDFДокумент16 страницSurvival Analysis in R PDFmarciodoamaralОценок пока нет
- Lecture 5: Evaluation: Information Retrieval Computer Science Tripos Part IIДокумент58 страницLecture 5: Evaluation: Information Retrieval Computer Science Tripos Part IIBemenet BiniyamОценок пока нет
- Order of Magnitude-2017Документ6 страницOrder of Magnitude-2017anon_865386332Оценок пока нет
- Enviro Data Analysis with MatLab Lecture 18: Cross-CorrДокумент46 страницEnviro Data Analysis with MatLab Lecture 18: Cross-CorrAnouar AttnОценок пока нет
- HW 3Документ4 страницыHW 3Hassan GDOURAОценок пока нет
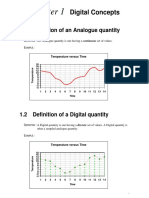
- Digital Concepts: 1.1 Definition of An Analogue QuantityДокумент6 страницDigital Concepts: 1.1 Definition of An Analogue QuantityKiran DОценок пока нет
- NRE Lecture 1Документ8 страницNRE Lecture 1yaregalОценок пока нет
- Computing Sensitivities of Cva Using AadДокумент58 страницComputing Sensitivities of Cva Using Aadtracy powellОценок пока нет
- Introduction To: Information RetrievalДокумент32 страницыIntroduction To: Information RetrievalTamizharasi AОценок пока нет
- Sistem Temu KembaliДокумент6 страницSistem Temu KembaliErwan SetiawanОценок пока нет
- Taylor Series: F (X) DF (X) DXДокумент4 страницыTaylor Series: F (X) DF (X) DXMrsriyansyahОценок пока нет
- Stanford University Computer Science Department Solved CS347 Spring 2001 Mid-TermДокумент5 страницStanford University Computer Science Department Solved CS347 Spring 2001 Mid-TermErwan SetiawanОценок пока нет
- Cosine TF Idf ExampleДокумент2 страницыCosine TF Idf Exampleysrome100% (1)
- Solved-Midterm Sistem Temu KembaliДокумент5 страницSolved-Midterm Sistem Temu KembaliErwan SetiawanОценок пока нет
- BIOMathДокумент14 страницBIOMathAnyaОценок пока нет
- 38 3 Exp DistДокумент5 страниц38 3 Exp DistEbookcrazeОценок пока нет
- Probabilistic Reasoning Over TimeДокумент62 страницыProbabilistic Reasoning Over TimeSHR extremeОценок пока нет
- Computer Exercise 1 in Stationary Stochastic Processes, HT 21Документ7 страницComputer Exercise 1 in Stationary Stochastic Processes, HT 21David BorgerОценок пока нет
- Dynare Examples PDFДокумент21 страницаDynare Examples PDFAnonymous T2LhplUОценок пока нет
- ScoringДокумент49 страницScoringMariem El MechryОценок пока нет
- Logarhitm ApplicationsДокумент21 страницаLogarhitm ApplicationsMario Caredo ManjarrezОценок пока нет
- Full PDFДокумент157 страницFull PDFSumit BhanwalaОценок пока нет
- Term Weighting and Similarity MeasuresДокумент35 страницTerm Weighting and Similarity Measuresmilkikoo shiferaОценок пока нет
- Problem Sheet 10aДокумент2 страницыProblem Sheet 10ach22b039Оценок пока нет
- Wavelets in RДокумент43 страницыWavelets in REsdras Jafet100% (1)
- Ranked Retrieval & Vector Space Model ExplainedДокумент72 страницыRanked Retrieval & Vector Space Model ExplainedInstall MacОценок пока нет
- A Many-Sorted Calculus Based on Resolution and ParamodulationОт EverandA Many-Sorted Calculus Based on Resolution and ParamodulationОценок пока нет
- Technical Report FRДокумент4 страницыTechnical Report FRmdkamrul.hasanОценок пока нет
- Curriculum VitaДокумент4 страницыCurriculum Vitamdkamrul.hasanОценок пока нет
- Research Paper FRДокумент5 страницResearch Paper FRmdkamrul.hasanОценок пока нет
- Curriculum VitaДокумент4 страницыCurriculum Vitamdkamrul.hasanОценок пока нет
- Sura Ar Rahman Slide2Документ78 страницSura Ar Rahman Slide2mdkamrul.hasanОценок пока нет
- Cover LetterДокумент1 страницаCover Lettermdkamrul.hasanОценок пока нет
- Sura Ar RahmanДокумент78 страницSura Ar Rahmanmdkamrul.hasan100% (4)
- FastMap - A Fast Algorithm For Indexing Data Mining and Visualization of Traditional and Multimedia DatasetsДокумент26 страницFastMap - A Fast Algorithm For Indexing Data Mining and Visualization of Traditional and Multimedia Datasetsmdkamrul.hasanОценок пока нет
- NIH Strategic Plan For Data ScienceДокумент26 страницNIH Strategic Plan For Data ScienceAristide AhonzoОценок пока нет
- Business English Syllabus GuideДокумент48 страницBusiness English Syllabus Guidenicoler1110% (1)
- Vegetation of PakistanДокумент10 страницVegetation of PakistanAhmad sadiqОценок пока нет
- Nikita S ResumeДокумент2 страницыNikita S ResumeNikita SrivastavaОценок пока нет
- 1000arepas Maythuna Aceituna Una YogaДокумент164 страницы1000arepas Maythuna Aceituna Una YogaDaniel Medvedov - ELKENOS ABE100% (1)
- Individual Assignment I Google Search Network CampaignДокумент15 страницIndividual Assignment I Google Search Network CampaignMokshita VajawatОценок пока нет
- Module 1 Sociological PerspectivesДокумент39 страницModule 1 Sociological PerspectivesCristine BalocaОценок пока нет
- 05 Mesina v. PeopleДокумент7 страниц05 Mesina v. PeopleJason ToddОценок пока нет
- Pope Francis' Call to Protect Human Dignity and the EnvironmentДокумент5 страницPope Francis' Call to Protect Human Dignity and the EnvironmentJulie Ann BorneoОценок пока нет
- Assessment - The Bridge Between Teaching and Learning (VFTM 2013)Документ6 страницAssessment - The Bridge Between Teaching and Learning (VFTM 2013)Luis CYОценок пока нет
- English 7 1st Lesson Plan For 2nd QuarterДокумент4 страницыEnglish 7 1st Lesson Plan For 2nd QuarterDiane LeonesОценок пока нет
- Unit 8Документ2 страницыUnit 8The Four QueensОценок пока нет
- Coordinates: Primary Practice QuestionsДокумент10 страницCoordinates: Primary Practice QuestionsJames KeruОценок пока нет
- 7 Basic Control ActionsДокумент27 страниц7 Basic Control ActionsAhmad ElsheemyОценок пока нет
- Affidavit of DesistanceДокумент6 страницAffidavit of Desistancesalasvictor319Оценок пока нет
- Demand Letter Jan 16Документ8 страницDemand Letter Jan 16jhean0215Оценок пока нет
- November 2008Документ14 страницNovember 2008Aldrin ThomasОценок пока нет
- Book Review: Alain de Botton's The Art of TravelДокумент8 страницBook Review: Alain de Botton's The Art of TravelharroweenОценок пока нет
- The Church of The Nazarene in The U.S. - Race Gender and Class in The Struggle With Pentecostalism and Aspirations Toward Respectability 1895 1985Документ238 страницThe Church of The Nazarene in The U.S. - Race Gender and Class in The Struggle With Pentecostalism and Aspirations Toward Respectability 1895 1985Luís Felipe Nunes BorduamОценок пока нет
- Assessing Learning Methods and TestsДокумент2 страницыAssessing Learning Methods and TestsZarah Joyce SegoviaОценок пока нет
- The Transformation of PhysicsДокумент10 страницThe Transformation of PhysicsVíctor Manuel Hernández MárquezОценок пока нет
- Commercial Bank of Africa Market ResearchДокумент27 страницCommercial Bank of Africa Market Researchprince185Оценок пока нет
- Ebook Torrance (Dalam Stanberg) - 1-200 PDFДокумент200 страницEbook Torrance (Dalam Stanberg) - 1-200 PDFNisrina NurfajriantiОценок пока нет
- CSE Qualifications and PointersДокумент9 страницCSE Qualifications and PointersChristopher de LeonОценок пока нет
- Function Point and Cocomo ModelДокумент31 страницаFunction Point and Cocomo ModelParinyas SinghОценок пока нет
- Bangla Ebook History of oUR LANDДокумент106 страницBangla Ebook History of oUR LANDbiddut100% (6)
- The CIA Tavistock Institute and The GlobalДокумент34 страницыThe CIA Tavistock Institute and The GlobalAnton Crellen100% (4)
- Year 9 Autumn 1 2018Документ55 страницYear 9 Autumn 1 2018andyedwards73Оценок пока нет