Вам также может понравиться
- RTP May 2019 EngДокумент162 страницыRTP May 2019 EngVarun SahaniОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- Cygwin Must Have PackageДокумент2 страницыCygwin Must Have PackageVarun SahaniОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- MatlaB Lab Manual APДокумент63 страницыMatlaB Lab Manual APVarun SahaniОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Circov PDFДокумент1 страницаCircov PDFVarun SahaniОценок пока нет
- Women & Child Safety SystemДокумент19 страницWomen & Child Safety SystemVarun SahaniОценок пока нет
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
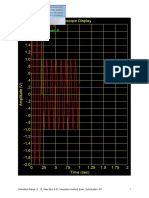
- Oscilloscope Display 1.8 2.0: Chan AДокумент1 страницаOscilloscope Display 1.8 2.0: Chan AVarun SahaniОценок пока нет
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- WML Lab FileДокумент42 страницыWML Lab FileVarun SahaniОценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Microelectronics FilesДокумент17 страницMicroelectronics FilesVarun SahaniОценок пока нет
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Advance Vlsi Design Practical File: Varun Sahani 04216412811 M.Tech (ECE) 2 SemДокумент12 страницAdvance Vlsi Design Practical File: Varun Sahani 04216412811 M.Tech (ECE) 2 SemVarun SahaniОценок пока нет
- Oscilloscope Display 1.375 1.500: Chan AДокумент1 страницаOscilloscope Display 1.375 1.500: Chan AVarun SahaniОценок пока нет
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Mobile Lab Final FileДокумент43 страницыMobile Lab Final FileVarun SahaniОценок пока нет
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- PC12 Customizing 2022Документ176 страницPC12 Customizing 2022Thenut PaisantaraОценок пока нет
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- DBMS PraticalДокумент90 страницDBMS PraticalNitesh BhuraОценок пока нет
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Case Study GithubДокумент2 страницыCase Study GithubEranga UdeshОценок пока нет
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Bismillah MTAДокумент24 страницыBismillah MTAHariyanaОценок пока нет
- School Management SystemДокумент59 страницSchool Management SystemAB ArthurОценок пока нет
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- CS6303 - Database Management Systems (DBMS) SasuriДокумент185 страницCS6303 - Database Management Systems (DBMS) SasuriJohn Downey Jr.Оценок пока нет
- The Main Scan FunctionДокумент7 страницThe Main Scan FunctionGreg MavhungaОценок пока нет
- Apostila Curso C#Документ11 страницApostila Curso C#Elder MoraisОценок пока нет
- HR Analytics (20mba Hr304)Документ25 страницHR Analytics (20mba Hr304)kavya halagani006Оценок пока нет
- FinalДокумент23 страницыFinalMariana BraileanuОценок пока нет
- SQL TutorialДокумент33 страницыSQL Tutorialapi-3774693Оценок пока нет
- Epoque Quick Ref Guide 3rd EditionДокумент119 страницEpoque Quick Ref Guide 3rd EditionSaid NafikОценок пока нет
- Top 50 SQL Interview Questions and Answers For Experienced & Freshers (2021 Update)Документ15 страницTop 50 SQL Interview Questions and Answers For Experienced & Freshers (2021 Update)KrupanandareddyYarragudiОценок пока нет
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Performance Tuning Guidelines For Siebel On Oracle Database December 2010Документ28 страницPerformance Tuning Guidelines For Siebel On Oracle Database December 201094050668100% (1)
- DB2 Questions SeshaДокумент5 страницDB2 Questions SesharamanasaiОценок пока нет
- Intrvw 50Документ9 страницIntrvw 50NIZAR MOHAMMEDОценок пока нет
- Combining Data in Pandas With Merge, .Join, and Concat - Real PythonДокумент2 страницыCombining Data in Pandas With Merge, .Join, and Concat - Real PythonJorge ForeroОценок пока нет
- Splunk Data Life Cycle Determining When and Where To Roll DataДокумент45 страницSplunk Data Life Cycle Determining When and Where To Roll DatarajuyjОценок пока нет
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Ax2012 Enus Devi 02Документ32 страницыAx2012 Enus Devi 02sergio_741Оценок пока нет
- People Soft FAQ'sДокумент45 страницPeople Soft FAQ'sHidayathulla MohammedОценок пока нет
- Informatica TransformationДокумент86 страницInformatica TransformationHanan AnsariОценок пока нет
- 5 Access DataBaseДокумент80 страниц5 Access DataBaseKhaled MohamedОценок пока нет
- A00 212 SДокумент20 страницA00 212 SLudovic Le BretonОценок пока нет
- Securities Capital Gains TaxДокумент28 страницSecurities Capital Gains Taxsharath.npОценок пока нет
- Explaining The EXPLAIN - Part 1: Joe RamonДокумент41 страницаExplaining The EXPLAIN - Part 1: Joe Ramonhyd.rasoolОценок пока нет
- Assessment Brief 3 - Individual ProjectДокумент4 страницыAssessment Brief 3 - Individual Projectriley jonesОценок пока нет
- Z17520020220174028New PPT Ch10Документ30 страницZ17520020220174028New PPT Ch10Melissa Indah FiantyОценок пока нет
- Fs ManualДокумент7 страницFs ManualDeepuОценок пока нет
- H 2Документ181 страницаH 2Yorbin1994Оценок пока нет
- TAble SpaceДокумент5 страницTAble SpacePunit DosiОценок пока нет