Вам также может понравиться
- Unicode - Overview: ABAP SystemsДокумент2 страницыUnicode - Overview: ABAP SystemsAlyDedenОценок пока нет
- Code Reuse: A Historic PerspectiveДокумент40 страницCode Reuse: A Historic Perspectiveakbisoi1Оценок пока нет
- E-Science E-Business E-Government and Their Technologies: Core XMLДокумент195 страницE-Science E-Business E-Government and Their Technologies: Core XMLto_alkОценок пока нет
- OpenText StreamServe 5.6.2 Code Pages and Unicode Support User GuideДокумент30 страницOpenText StreamServe 5.6.2 Code Pages and Unicode Support User GuideAbdelmadjid BouamamaОценок пока нет
- OriginalДокумент34 страницыOriginalosravanthi041Оценок пока нет
- Basic Concepts: 1.1 Welcome To Assembly Language 1Документ18 страницBasic Concepts: 1.1 Welcome To Assembly Language 1shakra chaudhryОценок пока нет
- CkumarДокумент25 страницCkumarapi-3715867Оценок пока нет
- PP Innovative Features of Scripting LanguagesДокумент20 страницPP Innovative Features of Scripting Languages014 CSE Devamruth AG100% (1)
- UnicodeДокумент17 страницUnicodeharisreeramОценок пока нет
- ASCII, Unicode, character sets explainedДокумент3 страницыASCII, Unicode, character sets explainedSherif ShenkoОценок пока нет
- Problem Addressed by The TopicДокумент2 страницыProblem Addressed by The TopicAlestar RahmanОценок пока нет
- Introduction to .NET Framework in 40 CharactersДокумент77 страницIntroduction to .NET Framework in 40 CharactersRahul GuptaОценок пока нет
- L1 Compiler - DesignДокумент50 страницL1 Compiler - DesignDhruv Pasricha100% (1)
- The Inevitable Unicode Project: Tikkana Akurati, Upgrade & Unicode SpecialistДокумент11 страницThe Inevitable Unicode Project: Tikkana Akurati, Upgrade & Unicode Specialistkrithika_s_raman1531Оценок пока нет
- 33-International Considerations in SQL ServerДокумент10 страниц33-International Considerations in SQL ServerdivandannОценок пока нет
- Localization TestingДокумент4 страницыLocalization Testingapi-3817447100% (2)
- CLOUD COMPUTING and Character EncodingДокумент10 страницCLOUD COMPUTING and Character EncodingPeer MousabОценок пока нет
- ch 2 Intro to DOT Net FrameworkДокумент21 страницаch 2 Intro to DOT Net FrameworksolomongebreamanuelОценок пока нет
- Different Types of LanguagesДокумент56 страницDifferent Types of LanguagesUmair ArshadОценок пока нет
- Lecture 1 2Документ28 страницLecture 1 2Ahmed Imran KabirОценок пока нет
- Introduction To Computer ProgrammingДокумент31 страницаIntroduction To Computer ProgrammingDinesh LasanthaОценок пока нет
- AU14C04-Codepages_and_DB2Документ33 страницыAU14C04-Codepages_and_DB2schock.903777Оценок пока нет
- CMP 131 Introduction To Computer Programming: Violetta Cavalli-Sforza Week 1, LabДокумент26 страницCMP 131 Introduction To Computer Programming: Violetta Cavalli-Sforza Week 1, Labfriend4spicyОценок пока нет
- CNG242 Lecture 1a2023Документ20 страницCNG242 Lecture 1a2023Shmin SОценок пока нет
- Class 1Документ27 страницClass 1Spandan GuntiОценок пока нет
- Structured ProgrammingДокумент31 страницаStructured ProgrammingkakaboomОценок пока нет
- Understanding Unicode System in SAP UpgradeДокумент9 страницUnderstanding Unicode System in SAP Upgradeajit_akmОценок пока нет
- Computer Programming LanguageДокумент16 страницComputer Programming LanguageJackОценок пока нет
- IntroductionДокумент26 страницIntroductionKen MutaiОценок пока нет
- DotnetДокумент22 страницыDotnetKumar HarishОценок пока нет
- Introduction To Computer Programming: Violetta Cavalli-SforzaДокумент25 страницIntroduction To Computer Programming: Violetta Cavalli-SforzaVladimir Pascua CanaoОценок пока нет
- Unicode in C and CДокумент8 страницUnicode in C and Cbksreejith4781Оценок пока нет
- Evolution of Programming Languages and the SDLCДокумент12 страницEvolution of Programming Languages and the SDLCJamal Ajamhs AbdullahiОценок пока нет
- Definitions: - Platform Is An Environment For Developing and Executing ApplicationДокумент16 страницDefinitions: - Platform Is An Environment For Developing and Executing ApplicationshahdoliОценок пока нет
- Unicode®: Character EncodingsДокумент11 страницUnicode®: Character EncodingsBenvindo XavierОценок пока нет
- Cape Notes Unit1 Module 3 Content 12Документ33 страницыCape Notes Unit1 Module 3 Content 12Rayando Rajae WilliamsОценок пока нет
- 2 Java Programming 1Документ59 страниц2 Java Programming 1SarahОценок пока нет
- Programming Languages and The Programming ProcessДокумент12 страницProgramming Languages and The Programming ProcessKamlesh KhatriОценок пока нет
- Software Categories: - System SW - Application SWДокумент23 страницыSoftware Categories: - System SW - Application SWSimbarashe MataireОценок пока нет
- An Introduction To Unicode - The Trainer's FriendДокумент52 страницыAn Introduction To Unicode - The Trainer's FriendLeandro Gabriel LópezОценок пока нет
- Evolution and History of Programming Languages: From Machine to ModernДокумент31 страницаEvolution and History of Programming Languages: From Machine to ModernnizamshaikОценок пока нет
- Computer LanguagesДокумент7 страницComputer LanguagesPoonam Mahesh PurohitОценок пока нет
- ABAP Language: New Features With Relases 6.10 and 6.20: Andreas Blumenthal, SAP AGДокумент153 страницыABAP Language: New Features With Relases 6.10 and 6.20: Andreas Blumenthal, SAP AGGürkan YılmazОценок пока нет
- Blogs Sap Com 2018 09 13 Holistic View of Unicode ConversionДокумент12 страницBlogs Sap Com 2018 09 13 Holistic View of Unicode ConversionPrasad BoddapatiОценок пока нет
- OverviewДокумент28 страницOverviewsumit67Оценок пока нет
- Unicode FundamentalsДокумент51 страницаUnicode Fundamentalsscribd_wakilsyedОценок пока нет
- Compiler ConstructionДокумент29 страницCompiler ConstructionMosam ShambharkarОценок пока нет
- Uni CodeДокумент4 страницыUni CodeElenaDiSavoiaОценок пока нет
- Scripting LanguagesДокумент23 страницыScripting Languageshariya100% (1)
- Introduction to ASP.NET - Understanding the .NET Framework ArchitectureДокумент40 страницIntroduction to ASP.NET - Understanding the .NET Framework ArchitectureDeep PatelОценок пока нет
- Programming Languages by Type GuideДокумент34 страницыProgramming Languages by Type GuideCleilson PereiraОценок пока нет
- Beyond UTR22: Complex Legacy-To-Unicode Mappings: 1. BackgroundДокумент16 страницBeyond UTR22: Complex Legacy-To-Unicode Mappings: 1. Backgroundatom999Оценок пока нет
- ECP Lect2Документ14 страницECP Lect2Gul HaiderОценок пока нет
- Week 1 PDFДокумент38 страницWeek 1 PDFJashan Bansal100% (1)
- RISC vs CISC: Phases of a CompilerДокумент16 страницRISC vs CISC: Phases of a Compilersukanta majumderОценок пока нет
- 01-02-Language Design IssuesДокумент39 страниц01-02-Language Design IssuesGebru GurmessaОценок пока нет
- "Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"От Everand"Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"Оценок пока нет
- Mod 4 - Computer LanguagesДокумент36 страницMod 4 - Computer LanguagesShanice NyairoОценок пока нет
- Assembly Language:Simple, Short, And Straightforward Way Of Learning Assembly ProgrammingОт EverandAssembly Language:Simple, Short, And Straightforward Way Of Learning Assembly ProgrammingРейтинг: 2 из 5 звезд2/5 (1)
- HallTicket PDFДокумент1 страницаHallTicket PDFKamal KantОценок пока нет
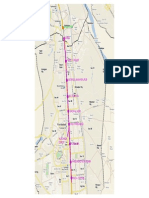
- 1badarpur - Faridabad Ext-Model PDFДокумент1 страница1badarpur - Faridabad Ext-Model PDFKamal KantОценок пока нет
- Chapter2 l2Документ25 страницChapter2 l2Raju RanjanОценок пока нет
- The ant and the dove: An unlikely friendship forms through selfless acts of kindnessДокумент1 страницаThe ant and the dove: An unlikely friendship forms through selfless acts of kindnessKamal KantОценок пока нет
- Basis ReportsДокумент1 страницаBasis ReportsKamal KantОценок пока нет
- Tugas Bing Short StoryДокумент1 страницаTugas Bing Short StorybayumdpratamaОценок пока нет
- SAP Basis Training IДокумент22 страницыSAP Basis Training IAmarnath100% (19)
- KG Dialogues March-April 2011Документ12 страницKG Dialogues March-April 2011Kamal KantОценок пока нет
- Change LoginScreen LogoДокумент8 страницChange LoginScreen LogoKamal KantОценок пока нет
- Ref: "Maruti Suzuki" Direct Recruitments OfferДокумент2 страницыRef: "Maruti Suzuki" Direct Recruitments OfferKamal KantОценок пока нет
- 5Документ1 страница5Kamal KantОценок пока нет
- Be A SMART Businessman!!: We Invite You To Become A JEEVAN FranchiseeДокумент2 страницыBe A SMART Businessman!!: We Invite You To Become A JEEVAN FranchiseeKamal KantОценок пока нет
- 6Документ2 страницы6Kamal KantОценок пока нет
- Monkey and Dolphin Story: Animal Friends Save Each OtherДокумент1 страницаMonkey and Dolphin Story: Animal Friends Save Each OtherKamal KantОценок пока нет
- Kamal Interview QuestionДокумент2 страницыKamal Interview QuestionKamal KantОценок пока нет
- Seeking Assignments As SAP BASIS Technology Consultant With A Technology-Driven Organisation of Repute Educational CredentialsДокумент3 страницыSeeking Assignments As SAP BASIS Technology Consultant With A Technology-Driven Organisation of Repute Educational CredentialsKamal KantОценок пока нет
- SAP Workflow MonitoringДокумент61 страницаSAP Workflow MonitoringKamal Kant100% (1)
- Fresher BPO Resume Format - 1Документ2 страницыFresher BPO Resume Format - 1Kamal KantОценок пока нет
- Sap Print GuideДокумент25 страницSap Print GuideKamal KantОценок пока нет
- Seal Java Maintainers GuideДокумент10 страницSeal Java Maintainers GuideKamal KantОценок пока нет
- SAP ABAP Expert ResumeДокумент2 страницыSAP ABAP Expert ResumeKamal KantОценок пока нет
- Local SettingsДокумент11 страницLocal SettingsKamal KantОценок пока нет
- S LicenseДокумент6 страницS LicenseKamal KantОценок пока нет
- Cert OverrideДокумент1 страницаCert OverrideKamal KantОценок пока нет
- SAP ABAP Expert ResumeДокумент2 страницыSAP ABAP Expert ResumeKamal KantОценок пока нет
- Configuration of Mailing Server: Go To Tcode-: Expand All Nodes (Tree)Документ5 страницConfiguration of Mailing Server: Go To Tcode-: Expand All Nodes (Tree)Kamal KantОценок пока нет
- CV Oracle DBA SAP Basis ConsultantДокумент2 страницыCV Oracle DBA SAP Basis ConsultantKamal KantОценок пока нет
- NtbtlogДокумент38 страницNtbtlogKamal KantОценок пока нет
- Disable Transport AllДокумент3 страницыDisable Transport AllKamal KantОценок пока нет
- 02 Sap - All Movement TypesДокумент5 страниц02 Sap - All Movement TypesKamal KantОценок пока нет
- Introduction To Competitive ProgrammingДокумент11 страницIntroduction To Competitive ProgrammingBinaryОценок пока нет
- Asmita Tiwari Mis PresentationДокумент22 страницыAsmita Tiwari Mis PresentationAniruddh VermaОценок пока нет
- Vulnerability Mapping Using Easy AHP - CBS UYGULAMAДокумент9 страницVulnerability Mapping Using Easy AHP - CBS UYGULAMAmarnoonpvОценок пока нет
- White Paper Chain X 1Документ20 страницWhite Paper Chain X 1Ishan PandeyОценок пока нет
- Creating Mobile Apps With Xamarin - FormsДокумент117 страницCreating Mobile Apps With Xamarin - FormsShoriful IslamОценок пока нет
- Manjaro-Documentation-0 8 10 PDFДокумент96 страницManjaro-Documentation-0 8 10 PDFSergio Eu CaОценок пока нет
- Sampling TheoremДокумент92 страницыSampling TheoremvijaybabukoreboinaОценок пока нет
- Writing Games with PygameДокумент25 страницWriting Games with PygameAline OliveiraОценок пока нет
- (WWW - Entrance-Exam - Net) - DOEACC B Level-Network Management & Information Security Sample Paper 1Документ2 страницы(WWW - Entrance-Exam - Net) - DOEACC B Level-Network Management & Information Security Sample Paper 1DEBLEENA VIJAYОценок пока нет
- Efficient DFT CalculationДокумент9 страницEfficient DFT Calculationapi-3695801100% (1)
- CENTURION INSTITUTE VLSI SYSTEM ARCHITECTUREДокумент2 страницыCENTURION INSTITUTE VLSI SYSTEM ARCHITECTUREshreetam beheraОценок пока нет
- Mysql Commands NotesДокумент23 страницыMysql Commands NotesShashwat & ShanayaОценок пока нет
- SAP Correspondence Tutorial - Configuration, Generation, Printing & EmailДокумент13 страницSAP Correspondence Tutorial - Configuration, Generation, Printing & Emailsrinivas100% (1)
- DP Biometric 14060 DriversДокумент159 страницDP Biometric 14060 Driversberto_716Оценок пока нет
- Self Organizing Maps - ApplicationsДокумент714 страницSelf Organizing Maps - ApplicationsGeorge CuniaОценок пока нет
- PPS - Practical - Assignment - 1 To 5 PDFДокумент10 страницPPS - Practical - Assignment - 1 To 5 PDFAthul Rajan100% (2)
- Esp32 Datasheet enДокумент43 страницыEsp32 Datasheet enRenato HernandezОценок пока нет
- Lab 4Документ4 страницыLab 4KianJohnCentenoTuricoОценок пока нет
- Implementing The Euro As Functional Currency For Oracle HRMS Release 12.1 HRMS RUP5 - 2015Документ67 страницImplementing The Euro As Functional Currency For Oracle HRMS Release 12.1 HRMS RUP5 - 2015Saken RysbekovОценок пока нет
- Java Programming: Step by Step - Sample Programs Supplement To The Video TutorialДокумент58 страницJava Programming: Step by Step - Sample Programs Supplement To The Video TutorialIsuri_PabasaraОценок пока нет
- Ques SetДокумент3 страницыQues SetTECH IS FUNОценок пока нет
- PCI Express BasicsДокумент34 страницыPCI Express Basicsteo2005100% (1)
- APCS BookДокумент543 страницыAPCS BookEdmundo Coup0% (1)
- Unit 1Документ22 страницыUnit 1Cookie SarwarОценок пока нет
- Test Script CBS Olibs 724 - User ManagementДокумент26 страницTest Script CBS Olibs 724 - User ManagementSagita RahayuОценок пока нет
- API Dev GuideДокумент94 страницыAPI Dev GuideMel CooperОценок пока нет
- Flynn's ClassificationДокумент46 страницFlynn's ClassificationmasumiОценок пока нет
- 0012 MACH-Pro SeriesДокумент2 страницы0012 MACH-Pro SeriesLê Quốc KhánhОценок пока нет
- 3D Coordinate Rotation G700 Code For Automation: Application EngineeringДокумент7 страниц3D Coordinate Rotation G700 Code For Automation: Application EngineeringKurtОценок пока нет
- Data Encryption StandardДокумент44 страницыData Encryption StandardAnkur AgrawalОценок пока нет