Вам также может понравиться
- Analysis of VarianceДокумент62 страницыAnalysis of VarianceJohnasse Sebastian NavalОценок пока нет
- Lec Set 1 Data AnalysisДокумент55 страницLec Set 1 Data AnalysisSmarika KulshresthaОценок пока нет
- Correlation-Regression 2019Документ76 страницCorrelation-Regression 2019ANCHURI NANDINIОценок пока нет
- FEM3004 Chapter 3 Sampling DistributionДокумент20 страницFEM3004 Chapter 3 Sampling DistributionCheng Kai WahОценок пока нет
- CH 135 Exam II A KeyДокумент6 страницCH 135 Exam II A Keynguyen ba trungОценок пока нет
- Identifikasi KationДокумент106 страницIdentifikasi KationHAIDAR RACHMANОценок пока нет
- Complexometric Titration: Complex (Coordination Compound)Документ13 страницComplexometric Titration: Complex (Coordination Compound)Ben AbellaОценок пока нет
- Ideal and Real GasesДокумент90 страницIdeal and Real GasesShubham KanungoОценок пока нет
- Vapor/Liquid Equilibrium-: ERT 206: Thermodynamics Miss Anis Atikah Ahmad Email: Anis Atikah@unimap - Edu.myДокумент51 страницаVapor/Liquid Equilibrium-: ERT 206: Thermodynamics Miss Anis Atikah Ahmad Email: Anis Atikah@unimap - Edu.myVũ LêОценок пока нет
- Lesson 5 - The Polarity of Molecule Based On Its ShapeДокумент22 страницыLesson 5 - The Polarity of Molecule Based On Its Shapetheresa balaticoОценок пока нет
- The Electronic Structure of AtomsДокумент54 страницыThe Electronic Structure of AtomsElijah PunzalanОценок пока нет
- Experiment 13cДокумент4 страницыExperiment 13cXazerco LaxОценок пока нет
- Chapter 11Документ30 страницChapter 11ta.ba100% (1)
- Lecture 4 Statistical Data Treatment and Evaluation ContdДокумент11 страницLecture 4 Statistical Data Treatment and Evaluation ContdRobert EdwardsОценок пока нет
- Band Broadening and Column Efficiency 2020 PDFДокумент23 страницыBand Broadening and Column Efficiency 2020 PDFSalix MattОценок пока нет
- Classification of ElementsДокумент26 страницClassification of ElementsSyeda Farzana Sadia BithiОценок пока нет
- Organic - Class 5 PDFДокумент42 страницыOrganic - Class 5 PDFSajan Singh LUCKYОценок пока нет
- Experiment 3:: Determination of Mixed AlkaliДокумент24 страницыExperiment 3:: Determination of Mixed AlkaliRaphael E. MiguelОценок пока нет
- F AlkanesAlkenesStereochemTutorial 3Документ4 страницыF AlkanesAlkenesStereochemTutorial 3Leong Yue YanОценок пока нет
- 1b - Physical Transformations of Pure SubstancesДокумент21 страница1b - Physical Transformations of Pure SubstancesakuhayuОценок пока нет
- Exercise-1: (For Jee Main) (Single Correct Answer Type) Henry Law, Osmotic PressureДокумент29 страницExercise-1: (For Jee Main) (Single Correct Answer Type) Henry Law, Osmotic PressureSumant KumarОценок пока нет
- Gas Laws: Pressure, Volume, and Hot AirДокумент58 страницGas Laws: Pressure, Volume, and Hot AirLiyana AziziОценок пока нет
- Organic Chem 2010Документ107 страницOrganic Chem 2010张浩天Оценок пока нет
- Conformations of Organic MoleculesДокумент21 страницаConformations of Organic MoleculesAkash KolliОценок пока нет
- Exercises 6,7,8 HandoutДокумент162 страницыExercises 6,7,8 HandoutErvi Festin PangilinanОценок пока нет
- What Is Chromatography?Документ54 страницыWhat Is Chromatography?MuhammadAfsarrazaОценок пока нет
- AP Ch. 14-15 Acids & Bases Review AnswersДокумент44 страницыAP Ch. 14-15 Acids & Bases Review AnswershksonnganОценок пока нет
- Chemistry Lab 1: Density of Aqueous Sodium Chloride SolutionsДокумент4 страницыChemistry Lab 1: Density of Aqueous Sodium Chloride SolutionsJHON SEBASTIAN OVIEDO ORTIZ0% (1)
- AMINES Anil HssliveДокумент9 страницAMINES Anil HssliveRanit MukherjeeОценок пока нет
- Chemical and Physical PropertiesДокумент42 страницыChemical and Physical Propertieskassandra mae celisОценок пока нет
- Redox TitrationДокумент23 страницыRedox TitrationSapna PandeyОценок пока нет
- Unit 15 - Reaction Rates and EquilibriumДокумент68 страницUnit 15 - Reaction Rates and EquilibriumGarett Berumen-RoqueОценок пока нет
- Physical Transformation of Pure Substances PDFДокумент29 страницPhysical Transformation of Pure Substances PDFR SuyaoОценок пока нет
- Formal Charge WorksheetДокумент3 страницыFormal Charge WorksheethbjvghcgОценок пока нет
- Intro To Organic Reactions CHM457Документ73 страницыIntro To Organic Reactions CHM457Zafrel ZaffОценок пока нет
- 8 1 Problem SetДокумент11 страниц8 1 Problem Setapi-182809945Оценок пока нет
- Chm256 c4 Part 1Документ32 страницыChm256 c4 Part 1shahera rosdi100% (1)
- Dimensional AnalysisДокумент14 страницDimensional AnalysisMark AbadiesОценок пока нет
- Specific Gravity (Ust Template)Документ22 страницыSpecific Gravity (Ust Template)JajaОценок пока нет
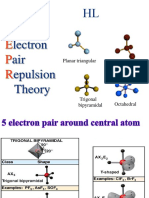
- Vsepr-HlДокумент25 страницVsepr-HlRyan BoukaaОценок пока нет
- Complexometric TitrationДокумент64 страницыComplexometric TitrationToyeba RahiОценок пока нет
- Module 1 Lec 2 - THERMODYNAMICS 2nd QTR SY1112 PDFДокумент8 страницModule 1 Lec 2 - THERMODYNAMICS 2nd QTR SY1112 PDFJason JohnsonОценок пока нет
- Name Date Period: - : This Worksheet Will Walk You Through How To Calculate Standard DeviationДокумент4 страницыName Date Period: - : This Worksheet Will Walk You Through How To Calculate Standard DeviationHumalaОценок пока нет
- 02 - Basic Concepts of Chemical BondingДокумент48 страниц02 - Basic Concepts of Chemical BondingAyulia Annisa100% (1)
- Parañaque Kings Enterprises, Inc. Vs Court of Appeals 268 SCRA 727. February 26, 1997Документ2 страницыParañaque Kings Enterprises, Inc. Vs Court of Appeals 268 SCRA 727. February 26, 1997Gerard Relucio OroОценок пока нет
- Oxidation and ReductionДокумент28 страницOxidation and ReductionCharlene LowОценок пока нет
- CHM256 Chapter 6Документ89 страницCHM256 Chapter 62022627178Оценок пока нет
- Elimination Reaction A.M.Документ46 страницElimination Reaction A.M.malik100% (1)
- Enthalpy ChangesДокумент2 страницыEnthalpy Changesapi-296833859100% (1)
- Lecture 2 2014 Random Errors in Chemical AnalysisДокумент24 страницыLecture 2 2014 Random Errors in Chemical AnalysisRobert EdwardsОценок пока нет
- Introduction To Legal ResearchДокумент4 страницыIntroduction To Legal ResearchAIZEL JOY POTOTОценок пока нет
- 6.thermodynamics AK 2018-19Документ15 страниц6.thermodynamics AK 2018-19XXXОценок пока нет
- Chapter 7 PDFДокумент80 страницChapter 7 PDFBaban BaidyaОценок пока нет
- ANCOVAДокумент17 страницANCOVAErik Otarola-CastilloОценок пока нет
- Chapter 8 Vaporliquid EquilibriumДокумент61 страницаChapter 8 Vaporliquid EquilibriumYessy Dwi YuliantiОценок пока нет
- Practice Problem Set 7 Applications of UV Vis Absorption Spectroscopy9Документ6 страницPractice Problem Set 7 Applications of UV Vis Absorption Spectroscopy9Edna Lip AnerОценок пока нет
- Anova: Analysis of Variation: Math 243 Lecture R. PruimДокумент30 страницAnova: Analysis of Variation: Math 243 Lecture R. PruimLakshmi BurraОценок пока нет
- Anova: Analysis of Variation: Math 243 Lecture R. PruimДокумент30 страницAnova: Analysis of Variation: Math 243 Lecture R. PruimMohamed Abdelkhalek AbouelseoudОценок пока нет
- Anova: Analysis of Variation: Math 243 Lecture R. PruimДокумент30 страницAnova: Analysis of Variation: Math 243 Lecture R. Pruimsamiwarraich519Оценок пока нет
- ANOVA 2023 Aa 2564896Документ26 страницANOVA 2023 Aa 2564896Muhammad Javed IqbalОценок пока нет
- QTC TechДокумент124 страницыQTC TechMarc DenningerОценок пока нет
- Risk Based ThinkingДокумент31 страницаRisk Based ThinkingMahender Kumar100% (2)
- Advanced ManufacturingДокумент28 страницAdvanced ManufacturingMahender KumarОценок пока нет
- Gear DesignДокумент75 страницGear DesignMahender Kumar80% (5)
- VDA 6.3 2010 - enДокумент45 страницVDA 6.3 2010 - enMahender KumarОценок пока нет
- New Iso 14001-2015Документ72 страницыNew Iso 14001-2015Mahender Kumar100% (3)
- Gear QualityДокумент3 страницыGear QualityMahender KumarОценок пока нет
- Din 76-1Документ5 страницDin 76-1Emmanuel100% (1)
- Is 2102Документ8 страницIs 2102Sowmen Chakroborty100% (1)
- Rules and Concepts of GD&T PDFДокумент31 страницаRules and Concepts of GD&T PDFMahender KumarОценок пока нет
- Fos AsmeДокумент41 страницаFos AsmeMahender Kumar100% (1)
- CQI-10 Effective Problem Solving A GuidelineДокумент208 страницCQI-10 Effective Problem Solving A GuidelineNelson Rodríguez100% (2)
- ISO 2768 - 1 General Tolerances Part IДокумент7 страницISO 2768 - 1 General Tolerances Part IMahender KumarОценок пока нет
- ANSI and ISO Geometric Tolerancing Symbols1Документ5 страницANSI and ISO Geometric Tolerancing Symbols1Mahender KumarОценок пока нет
- 5 Whys Problem Solving Technique SimplifiedДокумент7 страниц5 Whys Problem Solving Technique SimplifiedMahender Kumar100% (1)
- T TableДокумент1 страницаT TableMahender KumarОценок пока нет
- What Is Kaizen: Kaizen A Change For BetterДокумент11 страницWhat Is Kaizen: Kaizen A Change For BetterMahender KumarОценок пока нет
- Global 8d Problem Solving - FordДокумент6 страницGlobal 8d Problem Solving - FordMahender KumarОценок пока нет
- GD & TДокумент43 страницыGD & TMahender Kumar100% (1)
- MACHINE LEARNING TipsДокумент10 страницMACHINE LEARNING TipsSomnath KadamОценок пока нет
- Prof. Massimo Guidolin: 20192 - Financial EconometricsДокумент12 страницProf. Massimo Guidolin: 20192 - Financial EconometricsDewi Setyawati PutriОценок пока нет
- Design ExperimentДокумент45 страницDesign ExperimentElias LibayОценок пока нет
- Practice Multiple Choice Questions and FДокумент13 страницPractice Multiple Choice Questions and FVinayak GahloutОценок пока нет
- Straight and Crooked ThinkingДокумент127 страницStraight and Crooked Thinkingy9835679100% (2)
- 2Документ28 страниц2Arvic John BresenioОценок пока нет
- Continuous Improvement: More Advanced, Including Taguchi and Six SigmaДокумент49 страницContinuous Improvement: More Advanced, Including Taguchi and Six SigmaV CutОценок пока нет
- Statsmodel Python ExampleДокумент2 страницыStatsmodel Python ExampleKarloОценок пока нет
- LESSON 3 Types and Purpose of ResearchДокумент78 страницLESSON 3 Types and Purpose of ResearchAdanalee SolinapОценок пока нет
- Hif02001 PDFДокумент426 страницHif02001 PDFRUMMОценок пока нет
- Relationship Between Emotional Intelligence and Students Academic Performance - Role of Ethnic FactorДокумент13 страницRelationship Between Emotional Intelligence and Students Academic Performance - Role of Ethnic Factorمعن الفاعوريОценок пока нет
- Group 6 (T-Test)Документ32 страницыGroup 6 (T-Test)Laezel Ann Tahil100% (1)
- Practical Research 2 Module Nov. 2 6 Data Collection TechniquesДокумент27 страницPractical Research 2 Module Nov. 2 6 Data Collection Techniquesxx yyОценок пока нет
- A Comparison of 1-Regularizion, PCA, KPCA and ICA For Dimensionality Reduction in Logistic RegressionДокумент20 страницA Comparison of 1-Regularizion, PCA, KPCA and ICA For Dimensionality Reduction in Logistic RegressionManole Eduard MihaitaОценок пока нет
- E Busi8Документ12 страницE Busi8Prof. S. ShinyОценок пока нет
- A Python Library For Teaching Computation To Seismology StudentsДокумент7 страницA Python Library For Teaching Computation To Seismology StudentsFrancisco Javier Acuña OlateОценок пока нет
- SNR Maths Methods 19 Ia1 Asr High PSMTДокумент15 страницSNR Maths Methods 19 Ia1 Asr High PSMTVickyОценок пока нет
- SimRunner User GuideДокумент56 страницSimRunner User GuideJose ManzoОценок пока нет
- W. H. Auden's The Unknown CitizenДокумент18 страницW. H. Auden's The Unknown CitizenNo NameОценок пока нет
- 5 ENVI Geologic - Hyperspectral PDFДокумент5 страниц5 ENVI Geologic - Hyperspectral PDFLuiz BecerraОценок пока нет
- Thesis - Chapter 1-3 (Parental Involvement)Документ25 страницThesis - Chapter 1-3 (Parental Involvement)Karen May Pascual Urlanda100% (6)
- Working Capital PresentationДокумент40 страницWorking Capital PresentationDaman Deep Singh ArnejaОценок пока нет
- BRM MCQs For PG - MergedДокумент57 страницBRM MCQs For PG - MergedNarmadha DeviОценок пока нет
- BooksДокумент16 страницBooksAhmedОценок пока нет
- Demand Planning and ForecastingДокумент10 страницDemand Planning and Forecastingskabbas1Оценок пока нет
- Bsedmathcurriculum EDITrevisedДокумент19 страницBsedmathcurriculum EDITrevisedJoni Czarina AmoraОценок пока нет
- Relationships Among The Sport Competition Anxiety Test, The Sport Anxiety Scale, and The Collegiate Hockey Worry ScaleДокумент19 страницRelationships Among The Sport Competition Anxiety Test, The Sport Anxiety Scale, and The Collegiate Hockey Worry ScaleshekoembangОценок пока нет
- QMB 3200 Su23 hw5 1Документ4 страницыQMB 3200 Su23 hw5 1api-681093860Оценок пока нет
- SyllabusДокумент7 страницSyllabusfarhad shahryarpoorОценок пока нет
- Instructor SupportДокумент150 страницInstructor Supportscribdsiv100% (1)