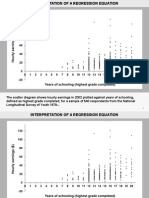
Вам также может понравиться
- AutocorrelationДокумент36 страницAutocorrelationIshanDograОценок пока нет
- Systems Development and Documentation TechniquesДокумент110 страницSystems Development and Documentation TechniquespriyankakumuduniОценок пока нет
- Chap4 Normality (Data Analysis) FVДокумент72 страницыChap4 Normality (Data Analysis) FVryad fki100% (1)
- AutocorrelationДокумент46 страницAutocorrelationBabar AdeebОценок пока нет
- Chapter 06 - HeteroskedasticityДокумент30 страницChapter 06 - HeteroskedasticityLê MinhОценок пока нет
- Assumption of Normality Dr. Azadeh AsgariДокумент27 страницAssumption of Normality Dr. Azadeh AsgariDr. Azadeh AsgariОценок пока нет
- Factorial Analysis of Variance PDFДокумент2 страницыFactorial Analysis of Variance PDFLaurenОценок пока нет
- Strategic Management Accounting PDFДокумент5 страницStrategic Management Accounting PDFMuhammad SadiqОценок пока нет
- Motives and Functions of A BusinessДокумент19 страницMotives and Functions of A BusinessDheandra Zeta ChandraОценок пока нет
- Detection of HeteroscadasticityДокумент6 страницDetection of HeteroscadasticityIshanDograОценок пока нет
- HeteroscedasticityДокумент7 страницHeteroscedasticityBristi RodhОценок пока нет
- Sampling: Gaurav Kumar Prajapat Sr. Audit Officer O/O Ag (Audit-Ii), Rajasthan JaipurДокумент61 страницаSampling: Gaurav Kumar Prajapat Sr. Audit Officer O/O Ag (Audit-Ii), Rajasthan JaipurNguyễn GiangОценок пока нет
- 5 - Ratio Regression and Difference Estimation - RevisedДокумент39 страниц5 - Ratio Regression and Difference Estimation - RevisedFiqry ZolkofiliОценок пока нет
- Logit Model For Binary DataДокумент50 страницLogit Model For Binary Datasoumitra2377Оценок пока нет
- Multivariate Analysis IBSДокумент20 страницMultivariate Analysis IBSrahul_arora_20Оценок пока нет
- Sampling Distribution and Simulation in RДокумент10 страницSampling Distribution and Simulation in RPremier PublishersОценок пока нет
- Sectors of Indian EcononyДокумент12 страницSectors of Indian EcononysheljanpdОценок пока нет
- Introduction To Multiple Linear RegressionДокумент49 страницIntroduction To Multiple Linear RegressionRennate MariaОценок пока нет
- AIS Presentation Section 3 Group 4Документ20 страницAIS Presentation Section 3 Group 4Meselech GirmaОценок пока нет
- 3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013Документ37 страниц3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013penyia100% (1)
- Manova and MancovaДокумент10 страницManova and Mancovakinhai_seeОценок пока нет
- Psychometrika VOL NO Arch DOI S: K.sijtsma@uvt - NLДокумент14 страницPsychometrika VOL NO Arch DOI S: K.sijtsma@uvt - NLCarlos RodriguezОценок пока нет
- RM 6Документ15 страницRM 6Vineeth Nambiar100% (1)
- Chapter 5 Indicators and VariablesДокумент24 страницыChapter 5 Indicators and Variablestemesgen yohannesОценок пока нет
- FALL 2012 - PSYC305 - Statistics For Experimental Design - SyllabusДокумент4 страницыFALL 2012 - PSYC305 - Statistics For Experimental Design - SyllabuscreativelyinspiredОценок пока нет
- Propensity Score Matching: A Primer For Educational ResearchersДокумент59 страницPropensity Score Matching: A Primer For Educational ResearchersMadam CashОценок пока нет
- ARCH ModelДокумент26 страницARCH ModelAnish S.MenonОценок пока нет
- Applied Multivariate Statistical Analysis Solution Manual PDFДокумент18 страницApplied Multivariate Statistical Analysis Solution Manual PDFALVYAN ARIFОценок пока нет
- Measurement and Scaling Fundamentals, Comparative and Non Comparative ScalingДокумент28 страницMeasurement and Scaling Fundamentals, Comparative and Non Comparative ScalingSavya JaiswalОценок пока нет
- Stnews 49Документ2 страницыStnews 49spsarathyОценок пока нет
- Sessions 21-24 Factor Analysis - Ppt-RevДокумент61 страницаSessions 21-24 Factor Analysis - Ppt-Revnandini swamiОценок пока нет
- Discretionary Revenues As A Measure of Earnings ManagementДокумент22 страницыDiscretionary Revenues As A Measure of Earnings ManagementmaulidiahОценок пока нет
- Research Methodology 2Документ29 страницResearch Methodology 2sohaibОценок пока нет
- Lecture 1 ECN 2331 (Scope of Statistical Methods For Economic Analysis) - 1Документ15 страницLecture 1 ECN 2331 (Scope of Statistical Methods For Economic Analysis) - 1sekelanilunguОценок пока нет
- Multinomial Probit: The Theory and Its Application to Demand ForecastingОт EverandMultinomial Probit: The Theory and Its Application to Demand ForecastingОценок пока нет
- Multiple Regression AnalysisДокумент77 страницMultiple Regression Analysishayati5823Оценок пока нет
- Applied Linear Regression Models 4th Ed NoteДокумент46 страницApplied Linear Regression Models 4th Ed Noteken_ng333Оценок пока нет
- Chapter Five Survey Research: Compiled by Workineh T. (Assistant Professor) 1Документ30 страницChapter Five Survey Research: Compiled by Workineh T. (Assistant Professor) 1Mebruka Abdul RahmanОценок пока нет
- Binary Dependent VarДокумент5 страницBinary Dependent VarManali PawarОценок пока нет
- Basic ProbДокумент47 страницBasic ProbAravind TaridaluОценок пока нет
- Non Parametric GuideДокумент5 страницNon Parametric GuideEnrico_LariosОценок пока нет
- Measuement and ScalingДокумент31 страницаMeasuement and Scalingagga1111Оценок пока нет
- Instalinotes - PREVMED IIДокумент24 страницыInstalinotes - PREVMED IIKenneth Cuballes100% (1)
- White TestДокумент2 страницыWhite TestfellipemartinsОценок пока нет
- Course Title: Data Pre-Processing and VisualizationДокумент11 страницCourse Title: Data Pre-Processing and VisualizationIntekhab Aslam100% (2)
- Multiple Choice Questions For Discussion. Part 2Документ20 страницMultiple Choice Questions For Discussion. Part 2BassamSheryan50% (2)
- Tests of HypothesisДокумент16 страницTests of HypothesisDilip YadavОценок пока нет
- Research Methodology Ty BBA Sem 5th Oct - 2009Документ23 страницыResearch Methodology Ty BBA Sem 5th Oct - 2009Abhishek Neogi100% (2)
- 4 Hypothesis Testing in The Multiple Regression ModelДокумент49 страниц4 Hypothesis Testing in The Multiple Regression ModelAbhishek RamОценок пока нет
- Statistics and Freq DistributionДокумент35 страницStatistics and Freq DistributionMuhammad UsmanОценок пока нет
- Multiple Regression Tutorial 3Документ5 страницMultiple Regression Tutorial 32plus5is7100% (2)
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignОт EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignОценок пока нет
- Chapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Документ91 страницаChapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Sahib Ullah MukhlisОценок пока нет
- Poisson Regression and Negative Binomial RegressionДокумент34 страницыPoisson Regression and Negative Binomial Regressiondanna ibanezОценок пока нет
- Applied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabОт EverandApplied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabОценок пока нет
- Types of Probability SamplingДокумент5 страницTypes of Probability SamplingSylvia NabwireОценок пока нет
- PPTДокумент114 страницPPTmrlyОценок пока нет
- Econometrics Model ExamДокумент10 страницEconometrics Model ExamTeddy DerОценок пока нет
- Moving Average MethodsДокумент48 страницMoving Average MethodsIshanDograОценок пока нет
- Detailed AnalysisДокумент4 страницыDetailed AnalysisIshanDograОценок пока нет
- Cost Effectiveness in The e Grocery BusinessДокумент10 страницCost Effectiveness in The e Grocery BusinessIshanDograОценок пока нет
- Exploratory AnalysisДокумент5 страницExploratory AnalysisIshanDograОценок пока нет
- Detailed AnalysisДокумент4 страницыDetailed AnalysisIshanDograОценок пока нет
- Mit PDFДокумент168 страницMit PDFIshanDograОценок пока нет
- Tesco Bakery Waste Analysis Tool FINALДокумент7 страницTesco Bakery Waste Analysis Tool FINALIshanDograОценок пока нет
- Dual 1Документ27 страницDual 1IshanDograОценок пока нет
- Role of Government in Corporate GovernanceДокумент2 страницыRole of Government in Corporate GovernanceIshanDograОценок пока нет
- Production-Shaft Driven BicycleДокумент3 страницыProduction-Shaft Driven BicycleIshanDograОценок пока нет
- Dual 1Документ27 страницDual 1IshanDograОценок пока нет
- Dual 2Документ25 страницDual 2IshanDograОценок пока нет
- Slope StrategyДокумент4 страницыSlope StrategyIshanDograОценок пока нет
- StrategyДокумент1 страницаStrategyIshanDograОценок пока нет
- Brandstorm 2016 - The Challenge PDFДокумент14 страницBrandstorm 2016 - The Challenge PDFAmit KumarОценок пока нет
- Detection of HeteroscadasticityДокумент6 страницDetection of HeteroscadasticityIshanDograОценок пока нет
- C01F03 2012 10 28Документ21 страницаC01F03 2012 10 28IshanDograОценок пока нет
- The Factories Act, 1948 INDIAДокумент71 страницаThe Factories Act, 1948 INDIAArun KumarОценок пока нет
- Econometrics and Business Forecasting - Handouts - RudraДокумент2 страницыEconometrics and Business Forecasting - Handouts - RudraIshanDograОценок пока нет
- Modeling and Simulation With Bizagi Process Modeler: Christian GijselsДокумент5 страницModeling and Simulation With Bizagi Process Modeler: Christian GijselsIshanDograОценок пока нет
- NewДокумент1 страницаNewIshanDograОценок пока нет
- Fabry PerotДокумент11 страницFabry PerotG. P HrishikeshОценок пока нет
- Design Constraint ReportДокумент11 страницDesign Constraint ReportCam MillerОценок пока нет
- Heat Exchanger-Design and ConstructionДокумент46 страницHeat Exchanger-Design and ConstructionMohd Jamal Mohd Moktar100% (2)
- MATHSДокумент221 страницаMATHSAbdulai FornahОценок пока нет
- Horizontal Vessel Support: Vertical Saddle ReactionsДокумент12 страницHorizontal Vessel Support: Vertical Saddle ReactionsSanket BhaleraoОценок пока нет
- EEMДокумент17 страницEEMSandaruwan සුජීවОценок пока нет
- Important QuestionsДокумент8 страницImportant QuestionsdineshbabuОценок пока нет
- Lesson Plan in Remainders TheoremДокумент5 страницLesson Plan in Remainders TheoremJune SabatinОценок пока нет
- The Basics of Thread Rolling: Tools, Tips & Design ConsiderationsДокумент108 страницThe Basics of Thread Rolling: Tools, Tips & Design ConsiderationsVictor ParvanОценок пока нет
- RLC-circuits With Cobra4 Xpert-Link: (Item No.: P2440664)Документ14 страницRLC-circuits With Cobra4 Xpert-Link: (Item No.: P2440664)fatjonmusli2016100% (1)
- Calculations QuestionssДокумент42 страницыCalculations QuestionssAlluringcharmsОценок пока нет
- Ijtmsr201919 PDFДокумент5 страницIjtmsr201919 PDFPrakash InturiОценок пока нет
- Lecture 4 - IP Addressing-New PDFДокумент51 страницаLecture 4 - IP Addressing-New PDFKhông Có TênОценок пока нет
- Tutorial 1 PDFДокумент9 страницTutorial 1 PDFMuaz Mohd ZahidinОценок пока нет
- Lecture 4 Maps Data Entry Part 1Документ80 страницLecture 4 Maps Data Entry Part 1arifОценок пока нет
- PRINCIPLES OF SURGERY (James R. Hupp Chapter 3 Notes) : 1. Develop A Surgical DiagnosisДокумент5 страницPRINCIPLES OF SURGERY (James R. Hupp Chapter 3 Notes) : 1. Develop A Surgical DiagnosisSonia LeeОценок пока нет
- Department of Mechanical Engineering Question Bank Subject Name: Heat & Mass Transfer Unit - I Conduction Part - AДокумент3 страницыDepartment of Mechanical Engineering Question Bank Subject Name: Heat & Mass Transfer Unit - I Conduction Part - AkarthikОценок пока нет
- Lista Ejercicios 3 PPEДокумент25 страницLista Ejercicios 3 PPEKarla HermorОценок пока нет
- 02a-2 V-Can2 Xlrteh4300g033850Документ1 страница02a-2 V-Can2 Xlrteh4300g033850Daniel PricopОценок пока нет
- V-Belt Sizing and Selection Guide: Standard V Belt Sizes FHP (Fractional Horsepower) V-Belts 3L, 4L, 5LДокумент1 страницаV-Belt Sizing and Selection Guide: Standard V Belt Sizes FHP (Fractional Horsepower) V-Belts 3L, 4L, 5LVijay ParmarОценок пока нет
- User ManualДокумент91 страницаUser ManualJorge Luis SoriaОценок пока нет
- 16 Kinetics Rigid BodiesДокумент30 страниц16 Kinetics Rigid BodiesNkoshiEpaphrasShoopalaОценок пока нет
- PDFДокумент1 страницаPDFdhaktodesatyajitОценок пока нет
- Mechanics of Solids by Crandall, Dahl, Lardner, 2nd ChapterДокумент118 страницMechanics of Solids by Crandall, Dahl, Lardner, 2nd Chapterpurijatin100% (2)
- DI CaseletesДокумент9 страницDI Caseletessprem4353Оценок пока нет
- Motor Protection: Module #2Документ32 страницыMotor Protection: Module #2Reymart Manablug50% (2)
- Mrs - Sanjana Jadhav: Mobile No-9422400137Документ3 страницыMrs - Sanjana Jadhav: Mobile No-9422400137Sanjana JadhavОценок пока нет
- Microstation Tutorial 01Документ85 страницMicrostation Tutorial 01Anonymous 82KmGf6Оценок пока нет
- Biomimetic Dentistry: Basic Principles and Protocols: December 2020Документ4 страницыBiomimetic Dentistry: Basic Principles and Protocols: December 2020Bence KlusóczkiОценок пока нет
- Anthony Hans HL Biology Ia Database WM PDFДокумент12 страницAnthony Hans HL Biology Ia Database WM PDFYadhira IbañezОценок пока нет