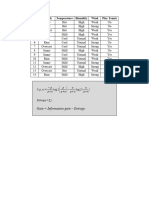
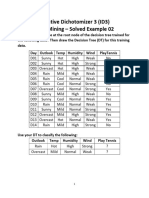
Вам также может понравиться
- De Moiver's Theorem (Trigonometry) Mathematics Question BankОт EverandDe Moiver's Theorem (Trigonometry) Mathematics Question BankОценок пока нет
- Decision Tree TutorialДокумент9 страницDecision Tree TutorialMuhammad UsmanОценок пока нет
- 7-Decision Trees LearningДокумент51 страница7-Decision Trees Learningyshu1Оценок пока нет
- Data DescriptionДокумент1 страницаData DescriptionAyele NugusieОценок пока нет
- Dec TreeДокумент17 страницDec TreeVan BlizzardОценок пока нет
- AT3 - Decision Tree ExampleДокумент17 страницAT3 - Decision Tree ExampleramadeviОценок пока нет
- Decision Trees CLSДокумент43 страницыDecision Trees CLSAshish TiwariОценок пока нет
- Decision TreeДокумент5 страницDecision TreePriyanka pawarОценок пока нет
- Module 3-Decision Tree LearningДокумент33 страницыModule 3-Decision Tree Learningramya100% (1)
- Decision Trees: Kazi Shah Nawaz Ripon - Faculty of Computer Sciences 1 27.01.2021Документ44 страницыDecision Trees: Kazi Shah Nawaz Ripon - Faculty of Computer Sciences 1 27.01.2021Waqas HameedОценок пока нет
- 15-381 Spring 2007 Assignment 6: LearningДокумент14 страниц15-381 Spring 2007 Assignment 6: LearningsandeepanОценок пока нет
- Decision Tree (Class 37-38) 169692509554958626652505a71d481Документ45 страницDecision Tree (Class 37-38) 169692509554958626652505a71d48123mb0072Оценок пока нет
- Decision TreesДокумент53 страницыDecision TreesRashid MahmoodОценок пока нет
- Classification and PredictionДокумент81 страницаClassification and PredictionKrishnan SwamiОценок пока нет
- Machine LearningДокумент52 страницыMachine LearningaimahsiddОценок пока нет
- (Lec 6) Decision Tree MLДокумент26 страниц(Lec 6) Decision Tree MLMuhtasim Jawad NafiОценок пока нет
- Classification: Decision TreesДокумент30 страницClassification: Decision TreesAshish TiwariОценок пока нет
- Decision and Regression Tree LearningДокумент51 страницаDecision and Regression Tree LearningMOOKAMBIGA A100% (1)
- Decision Tree Learning and Inductive InferenceДокумент37 страницDecision Tree Learning and Inductive InferenceLuisa GrigorescuОценок пока нет
- Lab Program 3Документ6 страницLab Program 3Sushmith ShettigarОценок пока нет
- Seminar 3Документ43 страницыSeminar 3manojmani380Оценок пока нет
- Machine Learning - Part 1Документ80 страницMachine Learning - Part 1cjon100% (1)
- Lab Program 3Документ6 страницLab Program 3Keshav DhawanОценок пока нет
- DM DT Solved Example 02 - UnlockedДокумент3 страницыDM DT Solved Example 02 - UnlockedJawaher AlbaddawiОценок пока нет
- Part Five - Extra PDFДокумент27 страницPart Five - Extra PDFNashowan100% (1)
- Government Engineering College Modasa Semester:7 (C.E) Machine Learning (3170724)Документ27 страницGovernment Engineering College Modasa Semester:7 (C.E) Machine Learning (3170724)Bhargav BharadiyaОценок пока нет
- 2.3 Decision-Tree-AlgorithmДокумент61 страница2.3 Decision-Tree-AlgorithmNandini rathiОценок пока нет
- Decision Tree: - Construct A Decision Tree To Classify "Golf PlayДокумент17 страницDecision Tree: - Construct A Decision Tree To Classify "Golf PlayAyaz HussainОценок пока нет
- Decision Trees For Classification - A Machine Learning Algorithm - XoriantДокумент4 страницыDecision Trees For Classification - A Machine Learning Algorithm - Xoriantmaanav8098Оценок пока нет
- Decision Tree Entropy GiniДокумент5 страницDecision Tree Entropy GiniSudheer RedusОценок пока нет
- Lecture 19 - Decision TressДокумент21 страницаLecture 19 - Decision Tressbscs-20f-0009Оценок пока нет
- Decision TreeДокумент10 страницDecision TreeSameer KhanОценок пока нет
- R20 Iii-Ii ML Lab ManualДокумент79 страницR20 Iii-Ii ML Lab ManualEswar Vineet100% (1)
- Tutorial 10 AnswersДокумент10 страницTutorial 10 AnswersTetzОценок пока нет
- Classification and Regression Trees (CART)Документ6 страницClassification and Regression Trees (CART)Pravin PanduОценок пока нет
- Lecture 12 - CH 03Документ22 страницыLecture 12 - CH 03Osama RousanОценок пока нет
- Learning by Asking Questions: Decision Trees: Piyush Rai Machine Learning (CS771A)Документ22 страницыLearning by Asking Questions: Decision Trees: Piyush Rai Machine Learning (CS771A)AnilОценок пока нет
- MLAll PracticalДокумент27 страницMLAll Practical55 ManviОценок пока нет
- Module 3 Chap 3 Decision Tree LearningДокумент79 страницModule 3 Chap 3 Decision Tree Learninghetomo5120Оценок пока нет
- AiML 4 3Документ59 страницAiML 4 3Nox MidОценок пока нет
- Government Engineering College, Modasa: B.E. - Computer Engineering (Semester - VII) 3170724 - Machine LearningДокумент3 страницыGovernment Engineering College, Modasa: B.E. - Computer Engineering (Semester - VII) 3170724 - Machine LearningronakОценок пока нет
- DWDM Lab 2Документ3 страницыDWDM Lab 2shreyastha2058Оценок пока нет
- Data Minig Haris Arshad BSSEДокумент9 страницData Minig Haris Arshad BSSEArsh SyedОценок пока нет
- Week 2 Lecture NotesДокумент61 страницаWeek 2 Lecture NotesAvijit GhoshОценок пока нет
- Machine LearningДокумент27 страницMachine Learningsahibpctebca21aОценок пока нет
- Selesaikan Dengan Logika ID3, Dari Sample Data Kriteriacuaca Untuk Permainan Bola BerikutДокумент13 страницSelesaikan Dengan Logika ID3, Dari Sample Data Kriteriacuaca Untuk Permainan Bola BerikutSasya NadiraОценок пока нет
- Decision Tree InductionДокумент52 страницыDecision Tree InductionIndumathy ParanthamanОценок пока нет
- Ilovepdf Merged 2Документ232 страницыIlovepdf Merged 2Dani ShaОценок пока нет
- Process Design Support DataДокумент53 страницыProcess Design Support DataSuryakant RanderiОценок пока нет
- Lec 3&4Документ20 страницLec 3&4Hariharan RavichandranОценок пока нет
- 20MIS7095 (LAB 7) .Ipynb ColaboratoryДокумент4 страницы20MIS7095 (LAB 7) .Ipynb Colaboratorysindhu gayathriОценок пока нет
- 20MIS7043 (LAB 7) .Ipynb ColaboratoryДокумент4 страницы20MIS7043 (LAB 7) .Ipynb Colaboratorysindhu gayathriОценок пока нет
- Decision TreeДокумент5 страницDecision TreeshubhОценок пока нет
- DWH&DM Ver2Документ3 страницыDWH&DM Ver2ramish489868Оценок пока нет
- 3.1 C 4.5 Algorithm-19Документ10 страниц3.1 C 4.5 Algorithm-19nayan jainОценок пока нет
- 111Документ56 страниц111Hrayer AprahamianОценок пока нет
- Data Mining 2020Документ2 страницыData Mining 2020waleedОценок пока нет
- Decision Tree LearningДокумент32 страницыDecision Tree Learningruff ianОценок пока нет
- Quiz 3 PoolДокумент9 страницQuiz 3 PoolLara FloresОценок пока нет
- Collective ViolenceДокумент3 страницыCollective ViolenceagrawalsushmaОценок пока нет
- Araling Panlipunan Academic Festival Accomplishment ReportДокумент7 страницAraling Panlipunan Academic Festival Accomplishment Reportlovely venia m jovenОценок пока нет
- Escholarship UC Item 8nd6j930Документ4 страницыEscholarship UC Item 8nd6j930Israel OrtizОценок пока нет
- DLP No. 13 - Retelling Myths and LegendsДокумент2 страницыDLP No. 13 - Retelling Myths and LegendsLeslie Felicia Peritos-Fuentes100% (2)
- On Totalitarian Interactivity: (Notes From The Enemy of The People)Документ4 страницыOn Totalitarian Interactivity: (Notes From The Enemy of The People)laureansggdОценок пока нет
- Concussions in SportsДокумент5 страницConcussions in Sportsapi-231143197Оценок пока нет
- English For Senior High SchoolДокумент11 страницEnglish For Senior High SchoolKukuh W PratamaОценок пока нет
- Introduction To CounsellingДокумент26 страницIntroduction To CounsellingSufanah Sabr100% (1)
- Lac Session GuideДокумент3 страницыLac Session GuideArela Jane TumulakОценок пока нет
- 2001teched1112 DraftdesignДокумент130 страниц2001teched1112 DraftdesignchristwlamОценок пока нет
- Op-Ed Rubric.v2Документ1 страницаOp-Ed Rubric.v2Dinu ElenaОценок пока нет
- Principles of Management, 6e: P C Tripathi & P N ReddyДокумент22 страницыPrinciples of Management, 6e: P C Tripathi & P N Reddyjp mishraОценок пока нет
- Spot The Discrepancy: Activity Form 9Документ2 страницыSpot The Discrepancy: Activity Form 9Jea Mycarose C. RayosОценок пока нет
- Peer Evaluation FormДокумент2 страницыPeer Evaluation FormAmir DanialОценок пока нет
- ĐỀ SỐ 30Документ6 страницĐỀ SỐ 30Joy English TeachersОценок пока нет
- Learning StyleДокумент11 страницLearning Stylepermafrancis17Оценок пока нет
- PerdevДокумент10 страницPerdevdarlene martinОценок пока нет
- General Psychology (Soc. Sci. 1) Course Outline Psychology: The Study of BehaviorДокумент5 страницGeneral Psychology (Soc. Sci. 1) Course Outline Psychology: The Study of BehaviorShairuz Caesar Briones DugayОценок пока нет
- The Social Construction of Reality (1966)Документ32 страницыThe Social Construction of Reality (1966)Lucas SoaresОценок пока нет
- Peace Corps Language and Cross Cultural CoordinatorДокумент1 страницаPeace Corps Language and Cross Cultural CoordinatorAccessible Journal Media: Peace Corps DocumentsОценок пока нет
- OB Session Plan - 2023Документ6 страницOB Session Plan - 2023Rakesh BiswalОценок пока нет
- Secondary Syllabus Form 3Документ18 страницSecondary Syllabus Form 3Syazwani Abu Bakar100% (1)
- Data Retreat 2016Документ64 страницыData Retreat 2016api-272086107Оценок пока нет
- Notes in ACC116 P1Документ3 страницыNotes in ACC116 P1Shaina Laila OlpindoОценок пока нет
- ABM - AE12 Ia D 9.1Документ2 страницыABM - AE12 Ia D 9.1Glaiza Dalayoan FloresОценок пока нет
- Matthias Steup - Knowledge, Truth, and Duty - Essays On Epistemic Justification, Responsibility, and Virtue (2001) PDFДокумент267 страницMatthias Steup - Knowledge, Truth, and Duty - Essays On Epistemic Justification, Responsibility, and Virtue (2001) PDFJorge Prado CarvajalОценок пока нет
- HNC RC Alan Slater, Ian Hocking, and Jon Loose - Theories and Issues in ChildДокумент30 страницHNC RC Alan Slater, Ian Hocking, and Jon Loose - Theories and Issues in ChildDea Novianda GeovanniОценок пока нет
- Coaching The Inner-Game of Trading: Monika MüllerДокумент7 страницCoaching The Inner-Game of Trading: Monika Mülleraba3abaОценок пока нет
- Tagalog As A Dominant Language PDFДокумент22 страницыTagalog As A Dominant Language PDFMYRLAN ANDRE ELY FLORESОценок пока нет
- MC 3 2019 Student NotesДокумент18 страницMC 3 2019 Student NotesRonaky123456Оценок пока нет