Вам также может понравиться
- NOtesДокумент1 страницаNOtessalman khanОценок пока нет
- Tetris-Packing Problem With Maximizing Filled Grid SquaresДокумент73 страницыTetris-Packing Problem With Maximizing Filled Grid Squaressalman khanОценок пока нет
- Computer Organization: Bus StructuresДокумент4 страницыComputer Organization: Bus Structuressalman khanОценок пока нет
- O o o o o o O: What Is DatabaseДокумент20 страницO o o o o o O: What Is Databasesalman khanОценок пока нет
- Finite Automata DFA and NFAДокумент39 страницFinite Automata DFA and NFAsalman khanОценок пока нет
- By: Parul Chauhan Assistant ProfДокумент64 страницыBy: Parul Chauhan Assistant Profsalman khanОценок пока нет
- O o o o o o O: What Is DatabaseДокумент20 страницO o o o o o O: What Is Databasesalman khanОценок пока нет
- Data Mining Guide: A Step-by-Step Process for BeginnersДокумент64 страницыData Mining Guide: A Step-by-Step Process for Beginnerssalman khanОценок пока нет
- How To Make A PDFДокумент5 страницHow To Make A PDFRodel NocumОценок пока нет
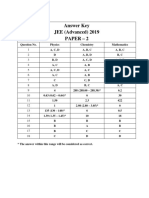
- KEY 2019 Paper2 PDFДокумент1 страницаKEY 2019 Paper2 PDFsalman khanОценок пока нет
- Chapter 6Документ57 страницChapter 6Rakesh KumarОценок пока нет
- 8085 Microprocessor Ramesh S. GaonkarДокумент330 страниц8085 Microprocessor Ramesh S. Gaonkarrohit31bark64% (22)
- EM SRS ReviewSoftRightHospitalManagementSystemSRSДокумент23 страницыEM SRS ReviewSoftRightHospitalManagementSystemSRSsunnyОценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Professional Data Engineer Certification Exam GuideДокумент6 страницProfessional Data Engineer Certification Exam GuideFatine AMOURIОценок пока нет
- Mathematical Methods of Classical Mechanics - V.I. ArnoldДокумент536 страницMathematical Methods of Classical Mechanics - V.I. Arnoldcollegetextbooks230100% (6)
- Creating Numerically Efficient FDTD Simulations Using Generic C++ ProgrammingДокумент2 страницыCreating Numerically Efficient FDTD Simulations Using Generic C++ ProgrammingŚrì KОценок пока нет
- Dissertacao Corrigida Laura Barroso 73943Документ87 страницDissertacao Corrigida Laura Barroso 73943Yulizar WidiatamaОценок пока нет
- June 2014 IAL QP S1 EdexcelДокумент13 страницJune 2014 IAL QP S1 EdexcelBara' HammadehОценок пока нет
- A Review of Basic Statistical Concepts: Answers To Odd Numbered Problems 1Документ32 страницыA Review of Basic Statistical Concepts: Answers To Odd Numbered Problems 1Rafidul IslamОценок пока нет
- Expert Systems With Applications: Oche Alexander Egaji, Gareth Evans, Mark Graham Griffiths, Gregory IslasДокумент7 страницExpert Systems With Applications: Oche Alexander Egaji, Gareth Evans, Mark Graham Griffiths, Gregory Islaspranay sharmaОценок пока нет
- ECEn631 13 - 8 Point AlgorithmДокумент33 страницыECEn631 13 - 8 Point AlgorithmtodoforОценок пока нет
- Instant Download Ebook PDF Fundamentals of Differential Equations and Boundary Value Problems 7th Edition PDF ScribdДокумент41 страницаInstant Download Ebook PDF Fundamentals of Differential Equations and Boundary Value Problems 7th Edition PDF Scribdwalter.herbert733100% (35)
- 21CS53 DBMS Iat3 QBДокумент2 страницы21CS53 DBMS Iat3 QBKunaljitОценок пока нет
- Bird Species Identifier Using Convolutional Neural NetworkДокумент9 страницBird Species Identifier Using Convolutional Neural NetworkIJRASETPublicationsОценок пока нет
- Simultaneous Method Sequential MethodДокумент1 страницаSimultaneous Method Sequential MethodMohammedMujahed0% (1)
- Binary Data Transmission MethodsДокумент16 страницBinary Data Transmission MethodsRomel Taga-amoОценок пока нет
- Clustering of Categorical Data Using Entropy Based K MODE AlgorithmДокумент2 страницыClustering of Categorical Data Using Entropy Based K MODE Algorithmvish crossОценок пока нет
- Identifying Visible & Hidden Edges of SolidsДокумент2 страницыIdentifying Visible & Hidden Edges of SolidsChacko JacobОценок пока нет
- BOOK-Soner-Stochastic Optimal Control in FinanceДокумент67 страницBOOK-Soner-Stochastic Optimal Control in FinancefincalОценок пока нет
- Applied Time Series AnalysisДокумент350 страницApplied Time Series AnalysisCristina MihaelaОценок пока нет
- Chapter 18 Linked Lists, Stacks, Queues, and Priority QueuesДокумент37 страницChapter 18 Linked Lists, Stacks, Queues, and Priority QueuesEbrahim AlalmaniОценок пока нет
- CE Model Question Paper 2019 - 16ME72Документ3 страницыCE Model Question Paper 2019 - 16ME72ashitaОценок пока нет
- CPEN 304 L08 - 1 - FIR Filter Design 2Документ47 страницCPEN 304 L08 - 1 - FIR Filter Design 2Phoebe MensahОценок пока нет
- A Neural Network Approach To Ordinal RegressionДокумент6 страницA Neural Network Approach To Ordinal Regression张拓Оценок пока нет
- Remove Trend and Detect Peaks in A Photoplethysmogram (PPG) Signal - MATLAB Answers - MATLAB CentralДокумент6 страницRemove Trend and Detect Peaks in A Photoplethysmogram (PPG) Signal - MATLAB Answers - MATLAB CentralGeneration GenerationОценок пока нет
- DBN: Deep Belief Networks ExplainedДокумент26 страницDBN: Deep Belief Networks ExplainedFiromsa TesfayeОценок пока нет
- Hirbod Assa: Curriculum VitaeДокумент9 страницHirbod Assa: Curriculum Vitaeapi-352033253Оценок пока нет
- IndexДокумент2 страницыIndexakita_1610Оценок пока нет
- DataДокумент1 137 страницDataOmkar Pradeep KhanvilkarОценок пока нет
- Power Generation Operation y Control Allen Wood 013Документ1 страницаPower Generation Operation y Control Allen Wood 013Vinod MuruganОценок пока нет
- Euler Bernoulli Beam TheoryДокумент10 страницEuler Bernoulli Beam TheoryinaОценок пока нет
- Lesson 2 Arithmetic SequenceДокумент27 страницLesson 2 Arithmetic SequenceLady Ann LugoОценок пока нет
- Discovery of Inert Gas StatsДокумент9 страницDiscovery of Inert Gas StatsDayanna GraztОценок пока нет