Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- PERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFДокумент18 страницPERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFJose HugoОценок пока нет
- Developing An OutlineДокумент18 страницDeveloping An OutlineEnrico Dela CruzОценок пока нет
- Integrated Cost and Risk Analysis Using Monte Carlo Simulation of A CPM ModelДокумент4 страницыIntegrated Cost and Risk Analysis Using Monte Carlo Simulation of A CPM ModelPavlos Vardoulakis0% (1)
- Agents SocializationДокумент4 страницыAgents Socializationinstinct920% (1)
- BharathДокумент2 страницыBharathbharath kumarОценок пока нет
- Barry Farm Powerpoint SlidesДокумент33 страницыBarry Farm Powerpoint SlidessarahОценок пока нет
- 1-Employees Retention Strategies in Reliance Retail LTD Thesis 85pДокумент6 страниц1-Employees Retention Strategies in Reliance Retail LTD Thesis 85pArunKumar100% (1)
- DataStage Interview QuestionsДокумент3 страницыDataStage Interview QuestionsvrkesariОценок пока нет
- 02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxДокумент1 страница02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxMichel van WordragenОценок пока нет
- Control Panel Manual 1v4Документ52 страницыControl Panel Manual 1v4Gustavo HidalgoОценок пока нет
- Chapter - 5 Theory of Consumer BehaviourДокумент30 страницChapter - 5 Theory of Consumer BehaviourpoojОценок пока нет
- Bao Nguyen - Internship Report v1Документ41 страницаBao Nguyen - Internship Report v1Giao DươngОценок пока нет
- Assignment 2: Question 1: Predator-Prey ModelДокумент2 страницыAssignment 2: Question 1: Predator-Prey ModelKhan Mohd SaalimОценок пока нет
- Fidelizer Pro User GuideДокумент12 страницFidelizer Pro User GuidempptritanОценок пока нет
- Segmented Shaft Seal Brochure Apr 08Документ4 страницыSegmented Shaft Seal Brochure Apr 08Zohaib AnserОценок пока нет
- L53 & L54 Environmental Impact Assessment (Eng) - WebДокумент31 страницаL53 & L54 Environmental Impact Assessment (Eng) - WebplyanaОценок пока нет
- Chris Barnes UEFA Presentation Nov 2015Документ47 страницChris Barnes UEFA Presentation Nov 2015muller.patrik1Оценок пока нет
- Marvel Science StoriesДокумент4 страницыMarvel Science StoriesPersonal trainerОценок пока нет
- AFDD 1-1 (2006) - Leadership and Force DevelopmentДокумент82 страницыAFDD 1-1 (2006) - Leadership and Force Developmentncore_scribd100% (1)
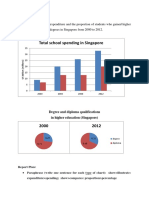
- Total School Spending in Singapore: Task 1 020219Документ6 страницTotal School Spending in Singapore: Task 1 020219viper_4554Оценок пока нет
- Research QuestionДокумент6 страницResearch QuestionAlfian Ardhiyana PutraОценок пока нет
- Physics For EngineersДокумент5 страницPhysics For EngineersKonstantinos FilippakosОценок пока нет
- Bab 4 Ba501 Pecahan SeparaДокумент24 страницыBab 4 Ba501 Pecahan SeparaPrince ShanОценок пока нет
- I. Objectives: A. Power Point PresentationДокумент3 страницыI. Objectives: A. Power Point PresentationJohn Brad Angelo LacuataОценок пока нет
- Shape The Future Listening Practice - Unit 3 - Without AnswersДокумент1 страницаShape The Future Listening Practice - Unit 3 - Without Answersleireleire20070701Оценок пока нет
- Lab 18 - Images of Concave and Convex Mirrors 1Документ4 страницыLab 18 - Images of Concave and Convex Mirrors 1api-458764744Оценок пока нет
- DSSSSPДокумент3 страницыDSSSSPChris BalmacedaОценок пока нет
- Listening Test 1.1Документ2 страницыListening Test 1.1momobear152Оценок пока нет
- Charity Connecting System: M.Archana, K.MouthamiДокумент5 страницCharity Connecting System: M.Archana, K.MouthamiShainara Dela TorreОценок пока нет
- Report Swtich Cisco Pass DNSДокумент91 страницаReport Swtich Cisco Pass DNSDenis Syst Laime LópezОценок пока нет