Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Configuration Switch Plateforme TSSRДокумент5 страницConfiguration Switch Plateforme TSSRMohamed BehtaneОценок пока нет
- Algebraic Expressions: College AlgebraДокумент8 страницAlgebraic Expressions: College Algebragerwin dagumОценок пока нет
- MG University 7th Ece Full SyllabusДокумент12 страницMG University 7th Ece Full SyllabusJinu MadhavanОценок пока нет
- Auto Power Supply ControlДокумент4 страницыAuto Power Supply ControlshivОценок пока нет
- CompanionДокумент84 страницыCompanionAsriani HasanОценок пока нет
- Why Townscript Live Is The Best GoToMeeting AlternativeДокумент6 страницWhy Townscript Live Is The Best GoToMeeting AlternativeAbhijeet SawantОценок пока нет
- OperatorsДокумент41 страницаOperatorsAavas ChaudharyОценок пока нет
- Smart City Using IOT Simulation Design in Cisco Packet TracerДокумент10 страницSmart City Using IOT Simulation Design in Cisco Packet TracerIJRASETPublicationsОценок пока нет
- Cloud Peak - Virtual Cloud Infrastructure ValidationДокумент9 страницCloud Peak - Virtual Cloud Infrastructure Validationbhushan7408Оценок пока нет
- Exfo Spec-Sheet Nqmsfiber v5 enДокумент11 страницExfo Spec-Sheet Nqmsfiber v5 enLeonel HerreraОценок пока нет
- Spare Part 2012Документ4 страницыSpare Part 2012Andy TangОценок пока нет
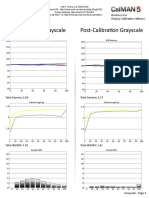
- LG 55EG9100 CNET Review Calibration ResultsДокумент3 страницыLG 55EG9100 CNET Review Calibration ResultsDavid KatzmaierОценок пока нет
- The Complexity of The Annihilating Polynomial.Документ17 страницThe Complexity of The Annihilating Polynomial.Muhammad AmmarОценок пока нет
- Filmora11 For Win User GuideДокумент250 страницFilmora11 For Win User GuideTriton PusatОценок пока нет
- TSUV Gyratory CrushersДокумент24 страницыTSUV Gyratory Crushersalejandrovives.oОценок пока нет
- D2K Imp QuesДокумент22 страницыD2K Imp Quespradauman100% (1)
- Trafodion Messages GuideДокумент386 страницTrafodion Messages GuideaОценок пока нет
- Presentation CI601820 Grys AU2023 - 1698699724963001xf7iДокумент49 страницPresentation CI601820 Grys AU2023 - 1698699724963001xf7iLeonel Julio Sánchez ArayaОценок пока нет
- Awp VivaДокумент3 страницыAwp VivaZoyaОценок пока нет
- How To Boot Windows Into Safe ModeДокумент4 страницыHow To Boot Windows Into Safe ModegrungeshoesОценок пока нет
- Aug - 2018 - Neo - MPT Prox TagsДокумент4 страницыAug - 2018 - Neo - MPT Prox TagsAndre EinsteinОценок пока нет
- Sujets-Corrigés Physique-Chimie Tse Bac (2000-2017)Документ193 страницыSujets-Corrigés Physique-Chimie Tse Bac (2000-2017)Oumar Traoré100% (2)
- Service Manual: UBP-X800 / UBP-UX80/ UBP-X1000ESДокумент61 страницаService Manual: UBP-X800 / UBP-UX80/ UBP-X1000ESalvhann_1Оценок пока нет
- TEC NOT 051 Ethernet Frames Wireshark Technical NotesДокумент12 страницTEC NOT 051 Ethernet Frames Wireshark Technical NotesGustavo RipoliОценок пока нет
- Digital Ethics - FINAL - 160616Документ35 страницDigital Ethics - FINAL - 160616ERNA BERLIANA 210904092Оценок пока нет
- CIMSpy BrochureДокумент2 страницыCIMSpy Brochurerahul.srivastavaОценок пока нет
- GSM/GPRS/GPS Tracker: ManualДокумент11 страницGSM/GPRS/GPS Tracker: ManualJunior NgongoОценок пока нет
- 80286, 80386, 80486 and Pentium MicroprocessorДокумент9 страниц80286, 80386, 80486 and Pentium Microprocessoramit mahajan91% (11)
- Forouzan MCQ in Bandwidth Utilization Multiplexing and Spreading PDFДокумент10 страницForouzan MCQ in Bandwidth Utilization Multiplexing and Spreading PDFburnnah leezahОценок пока нет
- Euphoria An It Quiz Essential Volume 2Документ54 страницыEuphoria An It Quiz Essential Volume 2Garvit SwamiОценок пока нет