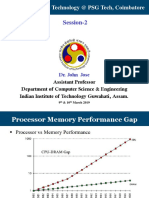
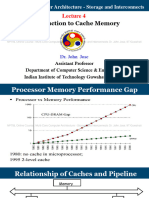
Вам также может понравиться
- File Storage and Indexing: Lesson 13 Cs 3200 Kathleen Durant PHDДокумент46 страницFile Storage and Indexing: Lesson 13 Cs 3200 Kathleen Durant PHDChu Mạnh TuấnОценок пока нет
- 02 Blocking - AddionalДокумент74 страницы02 Blocking - AddionalrakhaaditОценок пока нет
- File Organizations and Indexing: R&G Chapter 8Документ40 страницFile Organizations and Indexing: R&G Chapter 8shalini_gour08Оценок пока нет
- W5 Storage Files Indexing pt1Документ61 страницаW5 Storage Files Indexing pt1Khalil El LejriОценок пока нет
- B+ Tree & B TreeДокумент38 страницB+ Tree & B TreeRamkaran JanduОценок пока нет
- AI6122 Topic 3.1 - IndexДокумент40 страницAI6122 Topic 3.1 - IndexYujia TianОценок пока нет
- UE20CS332 Unit2 Slides PDFДокумент264 страницыUE20CS332 Unit2 Slides PDFGaurav MahajanОценок пока нет
- Storage and IndexingДокумент41 страницаStorage and Indexingtaiwo44Оценок пока нет
- StorageДокумент27 страницStorageQomindawoОценок пока нет
- Asm 1Документ400 страницAsm 1EnzoVibioОценок пока нет
- Search and Sort AlgorithmДокумент37 страницSearch and Sort AlgorithmAhmad Maulana IbrahimОценок пока нет
- Unit-4 File SystemДокумент21 страницаUnit-4 File SystemSanskruti DhananiОценок пока нет
- 1 Indexing TechniquesДокумент30 страниц1 Indexing TechniquesUmer Usman SheikhОценок пока нет
- Lecture9 PDFДокумент45 страницLecture9 PDFsangita kumreОценок пока нет
- Layers of A DBMS: Query Optimization Query Processor QueryДокумент15 страницLayers of A DBMS: Query Optimization Query Processor QueryAthar Abd AlmonemОценок пока нет
- Module 5 - Indexing and SearchingДокумент15 страницModule 5 - Indexing and SearchingPravin ShindeОценок пока нет
- IRS Module5-IДокумент15 страницIRS Module5-IPravin ShindeОценок пока нет
- DBMS Storage and IndexingДокумент90 страницDBMS Storage and IndexingKarthik_Srinan_6524Оценок пока нет
- Chapter Four Indexing StructureДокумент60 страницChapter Four Indexing StructureAlemayehu Getachew100% (2)
- Dbms Unit 5.2 (Ar16)Документ23 страницыDbms Unit 5.2 (Ar16)X BoyОценок пока нет
- Disk Storage Basic File Structures Indexing: CS 421 / 720 Spring 2015Документ52 страницыDisk Storage Basic File Structures Indexing: CS 421 / 720 Spring 2015waka wakaОценок пока нет
- Lesson 9 Lecture9Документ45 страницLesson 9 Lecture9Russel PonferradaОценок пока нет
- 8 DataStorageIndexingStructures UpdatedДокумент57 страниц8 DataStorageIndexingStructures UpdatedRosmarinusОценок пока нет
- Introduction To Computers and ProgrammingДокумент41 страницаIntroduction To Computers and ProgrammingLEON CAMPUSОценок пока нет
- 14-Record Nei BlocchiДокумент14 страниц14-Record Nei Blocchias_123Оценок пока нет
- 1 - Disk Storage - Ch13Документ31 страница1 - Disk Storage - Ch13modyxstarОценок пока нет
- 15IF11 Multicore BДокумент36 страниц15IF11 Multicore BRakesh VenkatesanОценок пока нет
- LOB Concepts - IBM DB2Документ64 страницыLOB Concepts - IBM DB2gitaОценок пока нет
- Lecture 19: Cache Basics: Today's Topics: Out-Of-Order Execution Cache Hierarchies Reminder: Assignment 7 Due On ThursdayДокумент17 страницLecture 19: Cache Basics: Today's Topics: Out-Of-Order Execution Cache Hierarchies Reminder: Assignment 7 Due On ThursdayZakiah AyopОценок пока нет
- File System Lecutre1Документ40 страницFile System Lecutre1vivekОценок пока нет
- Tree-Structured Indexes: R & G Chapter 9Документ34 страницыTree-Structured Indexes: R & G Chapter 9Son TongОценок пока нет
- Indexing and Hashing: (Emphasis On B+ Trees)Документ23 страницыIndexing and Hashing: (Emphasis On B+ Trees)Goutham TvsОценок пока нет
- It Is A Very Efficient Method To Search The Exact Data Items Based On Hash TableДокумент49 страницIt Is A Very Efficient Method To Search The Exact Data Items Based On Hash TableDr. Salini SureshОценок пока нет
- File Organizations and Indexing: R&G Chapter 8Документ26 страницFile Organizations and Indexing: R&G Chapter 8raw.junkОценок пока нет
- AI6122 Topic 2.1 - BooleanRetrievalДокумент32 страницыAI6122 Topic 2.1 - BooleanRetrievalYujia TianОценок пока нет
- Editors L21 L24Документ47 страницEditors L21 L24Neha PachauriОценок пока нет
- Lecture15 FallДокумент102 страницыLecture15 FallFaruk KaragozОценок пока нет
- Instructions: Commands in A Computer's LanguageДокумент27 страницInstructions: Commands in A Computer's Languageakhwat salafiyahОценок пока нет
- FAL (2019-20) - CSE1004 - ELA - 119 - AP2019201000445 - Reference Material I - Week-1-2Документ32 страницыFAL (2019-20) - CSE1004 - ELA - 119 - AP2019201000445 - Reference Material I - Week-1-2abhay chaudharyОценок пока нет
- Lecture3 PDFДокумент28 страницLecture3 PDFjohnОценок пока нет
- 23 - BSBI - Part 2Документ13 страниц23 - BSBI - Part 2gpswainОценок пока нет
- Database Design and Implementation 02.recordДокумент8 страницDatabase Design and Implementation 02.recordsushmsnОценок пока нет
- Lec 4Документ31 страницаLec 4jettychetan524Оценок пока нет
- Indexing and Hashing: (Emphasis On B+ Trees)Документ23 страницыIndexing and Hashing: (Emphasis On B+ Trees)Kishor PeddiОценок пока нет
- Lecture3 File OrgnДокумент13 страницLecture3 File OrgnAbhishek SarkarОценок пока нет
- Lobs: Stronger and Faster in Db2 9 For Z/Os (Part 2 of 2)Документ55 страницLobs: Stronger and Faster in Db2 9 For Z/Os (Part 2 of 2)Marco Antonio AraujoОценок пока нет
- Sankalp For DBMS - Indexing and ER DiagramДокумент52 страницыSankalp For DBMS - Indexing and ER DiagramDigambar DiwakarОценок пока нет
- RAID Systems: CS 537 - Introduction To Operating SystemsДокумент24 страницыRAID Systems: CS 537 - Introduction To Operating SystemsAadityaIcheОценок пока нет
- 15-440 Distributed Systems: Hashing and CdnsДокумент38 страниц15-440 Distributed Systems: Hashing and CdnsElОценок пока нет
- William Stallings Computer Organization and Architecture 6th Edition Cache MemoryДокумент45 страницWilliam Stallings Computer Organization and Architecture 6th Edition Cache MemoryFatima ZehraОценок пока нет
- Storage 5Документ10 страницStorage 5Harshit GargОценок пока нет
- C10 IR M2021 IndexConstruction SimpleandDistributedДокумент42 страницыC10 IR M2021 IndexConstruction SimpleandDistributedNaveen Kumar KalagarlaОценок пока нет
- DBMS Storage and IndexingДокумент80 страницDBMS Storage and IndexingkrishnaОценок пока нет
- 18.FileSystems Fundamentals HandoutДокумент5 страниц18.FileSystems Fundamentals HandoutBhubanAnandaChhatriyaОценок пока нет
- William Stallings Computer Organization and Architecture 7th Edition Cache MemoryДокумент67 страницWilliam Stallings Computer Organization and Architecture 7th Edition Cache Memorydilshadsabir8911Оценок пока нет
- The Google File System: CSE 490h, Autumn 2008Документ29 страницThe Google File System: CSE 490h, Autumn 2008hEho44744Оценок пока нет
- File System ImpelementationДокумент11 страницFile System ImpelementationAnushkaОценок пока нет
- Index Architecture: Febriliyan SamopaДокумент110 страницIndex Architecture: Febriliyan SamopaPramuditha Muhammad IkhwanОценок пока нет
- DB2 11 for z/OS: Intermediate Training for Application DevelopersОт EverandDB2 11 for z/OS: Intermediate Training for Application DevelopersОценок пока нет
- Intro ERP Using GBI Slides SD en v2.40 ARISДокумент49 страницIntro ERP Using GBI Slides SD en v2.40 ARISatungmuОценок пока нет
- Kendall7e - ch06 Agile Modeling and PrototypingДокумент52 страницыKendall7e - ch06 Agile Modeling and PrototypingMeynard BaptistaОценок пока нет
- Lecture 6Документ50 страницLecture 6Rana GaballahОценок пока нет
- Chapter17 CurrenttrendsДокумент55 страницChapter17 CurrenttrendsRana GaballahОценок пока нет
- Lecture 7Документ56 страницLecture 7Rana GaballahОценок пока нет
- Chapter 2 6Документ58 страницChapter 2 6Rana GaballahОценок пока нет
- End UserДокумент196 страницEnd UserRana GaballahОценок пока нет
- Lecture 8Документ51 страницаLecture 8Rana GaballahОценок пока нет
- Lecture 9Документ69 страницLecture 9Rana GaballahОценок пока нет
- Lecture 1Документ52 страницыLecture 1Rana GaballahОценок пока нет
- Lecture 5Документ52 страницыLecture 5Rana GaballahОценок пока нет
- Lecture 2Документ44 страницыLecture 2Rana GaballahОценок пока нет
- Lecture 3Документ57 страницLecture 3Rana GaballahОценок пока нет
- Design MetricsДокумент16 страницDesign MetricsRana GaballahОценок пока нет
- Growing Agile A Coachs Guide To Training Scrum... (Z-Library)Документ154 страницыGrowing Agile A Coachs Guide To Training Scrum... (Z-Library)amanda dingОценок пока нет
- Design IntroДокумент12 страницDesign IntroRana GaballahОценок пока нет
- Agility For Business AnalysisДокумент80 страницAgility For Business AnalysisRana GaballahОценок пока нет
- Agile MeetingsДокумент6 страницAgile MeetingsRana GaballahОценок пока нет
- 03 Intro ERP Using GBI Exercises Sales Order SD (A4) v2, Nov 2009Документ22 страницы03 Intro ERP Using GBI Exercises Sales Order SD (A4) v2, Nov 2009Javed AhamedОценок пока нет
- Design 3Документ14 страницDesign 3Rana GaballahОценок пока нет
- Pricing ConfigДокумент19 страницPricing Configsavera20Оценок пока нет
- Icebe 2013 TMGMT 6 FinalДокумент7 страницIcebe 2013 TMGMT 6 FinalRana GaballahОценок пока нет
- مراجعة كونكت بلس - 6 ب - ترم 1 - ذاكروليДокумент141 страницаمراجعة كونكت بلس - 6 ب - ترم 1 - ذاكروليRana GaballahОценок пока нет
- 04 Intro - ERP - Using - GBI - Case - Study - Sales, SD (A4) - v2, Nov 2009 .2 PDFДокумент58 страниц04 Intro - ERP - Using - GBI - Case - Study - Sales, SD (A4) - v2, Nov 2009 .2 PDFsnd31Оценок пока нет
- ExamДокумент447 страницExamaksОценок пока нет
- Lecture 01Документ39 страницLecture 01Rana GaballahОценок пока нет
- Certchamp 200 PMP 4th Edition QuestionsДокумент58 страницCertchamp 200 PMP 4th Edition Questionstohema100% (1)
- Intro S4HANA Using Global Bike Notes FI Fiori en v3.3Документ11 страницIntro S4HANA Using Global Bike Notes FI Fiori en v3.3Rana GaballahОценок пока нет
- Lecture 12: SQL (Nested Queries and Aggregate Functions)Документ50 страницLecture 12: SQL (Nested Queries and Aggregate Functions)Rana GaballahОценок пока нет
- Lecture 4: More SQL: Monday, January 13th, 2003Документ58 страницLecture 4: More SQL: Monday, January 13th, 2003Rana GaballahОценок пока нет
- 60617-7 1996Документ64 страницы60617-7 1996SuperhypoОценок пока нет
- Industrial Visit Report Part 2Документ41 страницаIndustrial Visit Report Part 2Navratan JagnadeОценок пока нет
- Togaf Open Group Business ScenarioДокумент40 страницTogaf Open Group Business Scenariohmh97Оценок пока нет
- L 1 One On A Page PDFДокумент128 страницL 1 One On A Page PDFNana Kwame Osei AsareОценок пока нет
- Discrete Probability Distribution UpdatedДокумент44 страницыDiscrete Probability Distribution UpdatedWaylonОценок пока нет
- Chapter 15 (Partnerships Formation, Operation and Ownership Changes) PDFДокумент58 страницChapter 15 (Partnerships Formation, Operation and Ownership Changes) PDFAbdul Rahman SholehОценок пока нет
- Information Security Policies & Procedures: Slide 4Документ33 страницыInformation Security Policies & Procedures: Slide 4jeypopОценок пока нет
- Motion and Time: Check Your Progress Factual QuestionsДокумент27 страницMotion and Time: Check Your Progress Factual QuestionsRahul RajОценок пока нет
- Field Assignment On Feacal Sludge ManagementДокумент10 страницField Assignment On Feacal Sludge ManagementSarah NamyaloОценок пока нет
- Harbin Institute of TechnologyДокумент7 страницHarbin Institute of TechnologyWei LeeОценок пока нет
- 1634313583!Документ24 страницы1634313583!Joseph Sanchez TalusigОценок пока нет
- FIREXДокумент2 страницыFIREXPausОценок пока нет
- Volvo D16 Engine Family: SpecificationsДокумент3 страницыVolvo D16 Engine Family: SpecificationsJicheng PiaoОценок пока нет
- PHD Thesis - Table of ContentsДокумент13 страницPHD Thesis - Table of ContentsDr Amit Rangnekar100% (15)
- StatisticsAllTopicsДокумент315 страницStatisticsAllTopicsHoda HosnyОценок пока нет
- Grave MattersДокумент19 страницGrave MattersKeith Armstrong100% (2)
- " Thou Hast Made Me, and Shall Thy Work Decay?Документ2 страницы" Thou Hast Made Me, and Shall Thy Work Decay?Sbgacc SojitraОценок пока нет
- 2024 01 31 StatementДокумент4 страницы2024 01 31 StatementAlex NeziОценок пока нет
- Nandurbar District S.E. (CGPA) Nov 2013Документ336 страницNandurbar District S.E. (CGPA) Nov 2013Digitaladda IndiaОценок пока нет
- SANDHU - AUTOMOBILES - PRIVATE - LIMITED - 2019-20 - Financial StatementДокумент108 страницSANDHU - AUTOMOBILES - PRIVATE - LIMITED - 2019-20 - Financial StatementHarsimranSinghОценок пока нет
- HTTP Parameter PollutionДокумент45 страницHTTP Parameter PollutionSpyDr ByTeОценок пока нет
- 37 Sample Resolutions Very Useful, Indian Companies Act, 1956Документ38 страниц37 Sample Resolutions Very Useful, Indian Companies Act, 1956CA Vaibhav Maheshwari70% (23)
- BRAC BrochureДокумент2 страницыBRAC BrochureKristin SoukupОценок пока нет
- PEG Catalog Siemens PDFДокумент419 страницPEG Catalog Siemens PDFrukmagoudОценок пока нет
- Marriage Families Separation Information PackДокумент6 страницMarriage Families Separation Information PackFatima JabeenОценок пока нет
- De Luyen Thi Vao Lop 10 Mon Tieng Anh Nam Hoc 2019Документ106 страницDe Luyen Thi Vao Lop 10 Mon Tieng Anh Nam Hoc 2019Mai PhanОценок пока нет
- Science Project FOLIO About Density KSSM Form 1Документ22 страницыScience Project FOLIO About Density KSSM Form 1SarveesshОценок пока нет
- Atelierul Digital Pentru Programatori: Java (30 H)Документ5 страницAtelierul Digital Pentru Programatori: Java (30 H)Cristian DiblaruОценок пока нет
- Deadlands - Dime Novel 02 - Independence Day PDFДокумент35 страницDeadlands - Dime Novel 02 - Independence Day PDFDavid CastelliОценок пока нет
- Steel and Timber Design: Arch 415Документ35 страницSteel and Timber Design: Arch 415Glennson BalacanaoОценок пока нет